DEPARTMENT OF SPEECH, HEARING & PHONETIC SCIENCES UCL Division of Psychology & Language Sciences |
|
|
|
John Wells’s phonetic blog archive 16-31 May 2008To see the IPA phonetic symbols in the text, please ensure that you have installed a Unicode font that includes them all, for example Lucida Sans Unicode or Charis SIL (click name for free download). Browsers: I recommend Firefox (free) or, if you prefer, Opera (also free). email:
|

Friday 30 May 2008 | IPA on a logoCzy nasze miasto nazywamy SzczeCIN? (Do we call our city SzczeCIN?). This is the question raised in a discussion in the local paper at miasta.gazeta.pl/szczecin/1,34959,5251335.html. (Thanks to Adam Ladziński for this.) Answer: no, you don’t. You call it SZCZEcin. Like almost all other Polish words this name is stressed on the penultimate. This could be a delicate matter, since before the second world war the city was in Germany and called Stettin ʃtɛˈtiːn, indeed stressed on the last syllable. But now it’s part of Poland, and isn’t. The proposed Szczecin logo alongside looks quite attractive. It was a nice idea to use eye-catching IPA symbols as the main content, with the usual orthographic form written very small underneath. In the bottom right quadrant there is a schematic representation of the geographical layout of the city, with Lake Dąbie in the background. But what a funny transcription! I have previously (blog, 3 March 2008) touched on the question of the Polish sz, cz, ś, ć and how to transcribe them. (The letter c before i, as in Szczecin, is pronounced like ć.) Pretty well everybody agrees on writing the latter two, the alveolopalatals, as ɕ, tɕ. The former two, postalveolars, are usually written simply as ʃ, tʃ, though you could argue for ʂ, tʂ. What I have never seen before is the use of diacritics for apical and palatalized applied to the basic palatoalveolar symbols. Moreover, one diacritic in the proposed logo is inappropriately large, the other inappropriately small. And the stress mark is in the wrong place. We can argue about whether the first vowel is best written with the simple symbol e or the comparative symbol ɛ. We can argue about whether or not we ought to use tie bars with the affricates to show that they’re not plosive-fricative sequences. Me? I would write ˈʃtʃetɕin. That’s if I wanted to transcribe the Polish pronunciation. The nearest we can get in English is ˈʃtʃetʃiːn. I wonder what Ryanair calls it. |
|

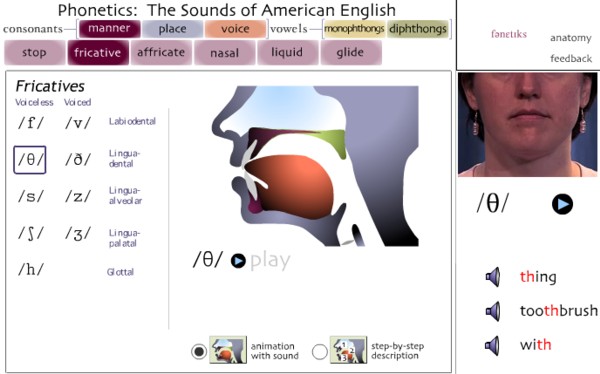
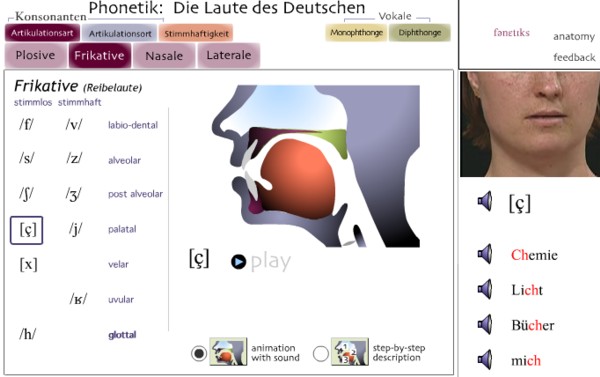
Thursday 29 May 2008 | Flash phoneticsThe Departments of Spanish and Portuguese, German, Speech Pathology and Audiology, and Academic Technologies at the University of Iowa have set up a web page for their Phonetics Flash Animation Project. It looks pretty impressive. For each sound of American English, German and Spanish you can watch a Flash animation of the movements of the organs of speech and see a video clip of a speaker pronouncing words exemplifying the sound. Here are two screenshots. | |
|
| ||
Once we start looking at things in detail, though, I must say I have certain reservations. The animations are schematic. They do not appear to be based on actual x-ray tracings. And in some respects they are clearly wrong. The American vowels in FACE and GOAT are transcribed /e/ and /o/, as in the Kenyon and Knott transcription — which is fair enough — and classified as monophthongs, which is not so satisfactory. Since they are taken as monophthongs, they are depicted with a steady-state configuration of the organs of speech, definitely not a good idea. The speaker on the accompanying video clips pronounces them as diphthongs, implying very clearly a substantial movement of the tongue during their production. It’s a pity to have such a mismatch between the schematic Flash animation and the real-life behaviour of the human speaker. If they had been able to find a speaker of AmE who uses a monophthongal /e/ and /o/ (there may be a few elderly ones left somewhere in Minnesota) they could have included corresponding monophthongal sound clips. And/or, given the diphthongs on the sound clips, they might have shown tongue movement in the animation. For Spanish jota we get both [x] and [χ] (‘Dialecto: castellano’), which is nice. The examples for Spanish [h] (‘Dialecto: caribeño’) all correspond to Castilian /s/ — but I wonder if it was really meant to be for jota too, as well, since that’s what they use in Cuba and Venezuela where others have [x]. And [h] corresponding to Castilian /s/ is found not just in Caribbean but in all American Spanish. Wouldn’t it have been sensible to include the glottal stop ʔ among the sounds of English? After all, that’s what most Americans use in words such as brightly and fitness. If phonemes are (as I believe) phonological abstractions in the human mind, I would have preferred to use [ ], not / /, for all the physical articulations rather than just for some of them. Despite these niggles, the Phonetics Flash Animation Project has given us a valuable resource. Congratulations to the University of Iowa. Let’s hope they can extend it to a few more languages. P.S. Kwan-Hin Cheung comments Thanks for pointing us to such an attractive site. As a phonetics teacher, I have mixed feelings. Animation is fascinating, but accuracy, at least to me, is more important. The representation of ɚ (retroflexed schwa) there is simply wrong. That discourages me from recommending it to students. The mistake also shows a wide-spread misconception that vowels only concern the dorsum, without noticing what happens to the tongue-tip or apex. | ||
Wednesday 28 May 2008 | SomeAn email from Paula Viera, who teaches phonetics in Buenos Aires: I would really appreciate it if you could write about the different pronunciations of the word some. I suppose that from the point of view of EFL there are three issues here:
Let’s take them in order. In RP some has the strong form sʌm and the weak form səm. The weak form is susceptible to possible syllabic consonant formation, making it sm̩. I’ll ignore this possibility in the remainder of the discussion. Despite ending in a labial rather than in an alveolar, this word is for many speakers also susceptible to assimilation of place of articulation, e.g. ˈsʌŋ kaɪnd əv... some kind of.... I’ll ignore this possibility, too. As far as other accents are concerned, it depends on whether or not there is a robust contrast between ʌ and ə (as in RP) or not (as in many other accents). If there’s no reliable contrast between the vowels, it makes little sense to distinguish strong and weak forms. The distribution of strong and weak forms in RP is subject to the usual rules. The word is pronounced strong if stranded or accented, weak otherwise. ‘Stranded’ means followed by a syntactic gap. In the case of some, this would be because the noun that would otherwise follow has been deleted (ellipted). In (1) some has its usual following noun, so is weak. In (2) it is stranded, therefore strong, even though unaccented. (1) (2) The some in (2) stands for some coffee. But the word coffee has been ellipted (‘is understood’). That leaves some stranded. In some more, some is not stranded, so has its weak form. Let me get you some more. Some is unaccented when it is merely a quantifier (used like a/an, but before a non-count noun or a plural: some salt, some books). If the noun is present it must have its weak form, səm. There’s some milk in the fridge. Here are some more examples of stranded some, with the strong form. (You’re eating ice cream.) 'I want some, | 'too! You could say that all ‘pronominal’ uses of some — all cases where some is not followed by its noun or noun phrase — represent stranding. That would cover cases like the following, where some is however likely to be accented. (Milk?) There’s 'some in the 'fridge. When some has a more specific meaning, it is usually accented and always has its strong form sʌm.
(i) as opposed to others or to all 'Some 'insects are 'good for the garden, A: All Cretans are liars. 'Some cheese | is made from 'goat’s milk. (ii) meaning ‘a considerable quantity of’ It was 'some 'years | be'fore she 'saw him again. (iii) as a determiner, ‘some ... or other’ 'Some 'idiot’s | 'left the 'light on. (iv) exclamatory, ‘very remarkable’ That was 'some | 'party! Compare (i) He put səm 'fruit on the pizza. (ii) He put ˈsʌm 'fruit on the pizza. Phew! This has taken longer than I expected. Sorry, Paula. P.S. Nigel Greenwood suggests I add the idiomatic BrE It’s 'all right for \/some! and Churchill’s defiant words to the Canadian parliament in 1941: When I warned [the French] that Britain would fight on alone, whatever they did, their Generals told their Prime Minister and his divided cabinet: 'In three weeks, England will have her neck wrung like a chicken.' all of course with the strong form. |
|

Tuesday 27 May 2008 | Idiomatic nucleus on a pronounIn my English Intonation: an Introduction, top of page 126, I mention a few English intonation idioms involving a falling tone on a nuclear-accented pronoun. 'Good for \you! But I didn’t mention a further pattern involving accented pronouns. They're 'not going to fool \/me. I have shown these all with a fall-rise tone, though I think they can also, less usually, have a simple fall. The unspoken corollary of the fall-rise is something like the following. They're 'not going to fool \/me again You 'certainly told \/him where to get off and similarly with the remaining examples. Perhaps these are not exactly idioms. But they’re certainly cases in which the location of the nucleus is unexpected | 'even for the ad\vanced EFL learner. |
|

Monday 26 May 2008 | happY with a suffixAn eagle-eyed correspondent from Argentina, Mónica Terluk, writes I have noticed both in the previous edition of the LPD and in the new one a different vowel in the second syllable of the words happily and happiness. The first word is pronounced with vowel number 2 (i.e. ɪ) in that syllable, whereas the second word is pronounced with the happY vowel i. The same happens with other pairs of related words: readily - readiness, easily - easiness, etc. The presence of happY i in the second syllable of such words as happier or happiest could be explained by the "happY i + vowel" rule. But what rule governs the different vowel sound in the words above? This seems to be an effect of the consonant l in the suffixes -ly, -less. Before these suffixes there is usually some noticeable laxing or centralization of what would otherwise be i. In all other inflected and derived forms of stems ending in i I treat that vowel as unchanged. So I write i not only in happy, happier, happiest but also in happiness. I also show the same vowel in dirtied ˈdɜːtid and dirties ˈdɜːtiz as in dirty ˈdɜːti, to accommodate the many speakers from whom studied ˈstʌdid and studded ˈstʌdɪd, taxi#s ˈtæksiz and tax#es ˈtæksɪz are not homophones (although in my own speech they are). But before -ly and -less it is clear that the situation is different. The vowel changes to ɪ or ə. It is most noticeable in stems ending -ri, i.e. in words like angrily, where Gimson gave priority to ˈæŋɡrəlɪ as long ago as 1977. (Peter Roach has decided to change that in the current EPD, going back to ˈæŋɡrɪli.) A more conservative pronunciation keeps ɪ in this position, a more progressive one ə. For those who go all the way (like me) there is a further interesting consequence. The schwa deriving from the happY vowel can coalesce with the l, producing a syllabic l̩. In stems ending ti or di that means lateral release of the plosive: readily ˈredl̩i, steadily ˈstedl̩i. Mightily rhymes with vitally. Penniless can be ˈpenl̩əs. I wouldn’t do that in guiltily or unwieldily, though. |
|

Friday 23 May 2008 | Historic UCL Phonetics recordings
|
|
Thursday 22 May 2008 | Dissent and descentZulima Molina (blog, yesterday) says Thank you for such a speedy reply. Regarding short vowels at the end of syllables, we have a doubt concerning vowel number 2 in the word divorce. It looks as though it stands at the end of the first syllable. Is that possible? Wouldn’t you use a happY i instead? And going back to the word settee, would it ever be possible to divide it set.iː, in which case aspiration would be lost? First, divorce, which I transcribe in LPD as dɪ ˈvɔːs, də-. Why do I not write the main pron as di ˈvɔːs? After all, I now transcribe words such as depend as di ˈpend, də-, replacing the dɪ ˈpend, də-, §diː- of earlier editions. I decided to simplify the treatment of words with the weak prefixes be-, de-, pre-, re- for the reasons set out in my blog for 29 January 2007. I exploit the existing notation i, which covers a range of possibilities from iː to ɪ, extending its use from words such as happy, glorious, radiation to these prefixes. However words spelt di- are different. In the first and second editions I did not give them a variant with diː-, because as far as I know such a pron is not found. Their prefix vowel can only be ɪ or ə. A nice potential minimal pair is dissent vs. descent. Probably for most of us they are homophones; but not for everyone. I transcribe them dɪ ˈsent and di ˈsent respectively. Yes, this does mean that ɪ is thereby left at the end of an open syllable. But in any case we need to recognize ɪ as one of the weak vowels, sometimes distinct from i, because of its appearance in words such as finishing. And as schwa shows (banana bə-, commercial kə-), there is no difficulty about syllable-final weak vowels. |
Visit the Longman Dictionaries site, with three video clips of me talking about the new edition of LPD. |
|
Zulima’s second point relates to the possible syllabification set.ˈiː, rather than my se.ˈtiː. The former is actually the syllabification given in EPD. Although it might seem to improve the phonotactics, I think it is wrong. Why? Because the t is strongly aspirated, which it would not be if it were syllable-final. (The main function of syllabification as I present it in LPD is to predict the correct allophones in those phonemes that are sensitive to syllable boundaries.) Conversely, lack of aspiration is what leads me to syllabify nostalgic as nɒ.ˈstældʒ.ɪk, leaving a syllable-final short strong vowel as awkward as the one in settee. Sometimes language is not neat and tidy. The word mistake brings these various points together. We do not say it as mɪs.ˈteɪk, i.e. with an aspirated t. Despite its etymology, it must be mɪ.ˈsteɪk, since the t is unaspirated, just as in stake; because in English t is unaspirated after s in the same syllable. Furthermore, we are left with a first syllable ending in ɪ. This analysis goes back to A.C. Gimson, who as editor of the 14th edition of EPD corrected the syllabification of mistake (as shown by the location of the stress mark) given in earlier editions. As evidence he took the study by Niels Davidsen-Nielsen, ‘Syllabification in English words with medial sp, st, sk’, published in the Journal of Phonetics (1974), 2, 15-45. |
|


Wednesday 21 May 2008 | SetteeZulima Molina, who teaches phonetics in Buenos Aires, asks I’d like to know why vowel 3 is found at the end of the first syllable in the word settee, taking into account that such a vowel is never found in final open syllables. (Vowel 3 in the Daniel Jones numbering is e.) I replied This word, seˈtiː, is one of a small number of words that have a short strong vowel in this position: another is tattoo tæˈtuː. Why? That’s how it is. English is irregular. Not surprisingly, some people (including me) usually pronounce it with a schwa, səˈtiː, a variant not given in EPD or ODP. But I do remember the late Professor Gimson saying it with se-, and that, I think, is the usual pronunciation. When I was a boy our family had a piece of furniture we called a settee, so it is a familiar word for me. Nowadays, though, most people have a sofa. The following is an email I shall not be replying to. Subject: Request for an early reply Dear Sir, Advice to everyone: don’t try to run before you can walk. |
|

Tuesday 20 May 2008 | American t-voicing and ‘sentence’A Japanese correspondent asks... for an expert opinion on American voiced t, as shown in the Longman English-Japanese Dictionary as t̬ ("t" with a little "v" underneath). He continues, with my comments interspersed: As far as I know, American T-voicing happens in the following positions. 1. After the stressed vowel, and followed by another vowel, e.g. city Providing the following vowel, if within the same word, is weak (which it usually is). So although we get t-voicing (aka ‘flapping’) in city, better, we don’t get it in latex ˈleɪteks. Strangely enough, this restriction doesn’t apply across word boundaries, so we do get t-voicing despite a following strong vowel in put up, get over, quite obviously. 2. After the stressed vowel plus n or r, and then followed by another vowel, e.g. party, twenty Yes, but the same rule about the next vowel being weak applies: so there is no t-voicing in syntax ˈsɪntæks. Again, across a word boundary a strong vowel is as good as a weak one, so there is t-voicing in start off, count up. 3. After the stressed vowel, and followed by syllabic l, e.g. little Yes, and even after an unstressed vowel: capital. Do you have any idea why we don't have any t-voicing or elision for the pronunciation of sentence? I asked a native speaker of American English, and she said she realized that she would use both, sentence without any T-voicing, and sentence with elision. It falls under the same heading as words such as button. Before n Americans typically pronounce t as a glottal stop, ʔ, which is not susceptible to voicing. Although we British say sentence as ˈsentəns, Americans have different rules about syllabic consonant formation, ən → n. (Because of font and browser bugs in rendering the syllabicity mark, I won’t place it under the n here.) Americans typically use a syllabic n after the t in sentence. So the t is immediately followed by a nasal, which triggers t → ʔ (the t becomes glottal). You can get ˈsentəns in very careful speech, but mostly Americans say ˈsenʔns. Since the t is pronounced as a glottal stop, it is not voiced. (There can also be an epenthetic t between the last two segments, giving ˈsenʔnts. And the vowel can coalesce with the nasal, so that we end up with something like ˈsẽʔnts.) We get the same thing in the American pronunciation of words such as accountant əˈkaʊnʔnt, mountain ˈmaʊnʔn, Clinton ˈklɪnʔn. Your informant is mistaken about the possibility of elision. Using a glottal stop is not the same thing as eliding t. So the crucial thing is the set of environments in which the speaker applies syllabic consonant formation. In the word sentence, Americans do form a syllabic nasal, the English don’t (though people from northern Ireland do). Tricky, isn’t it? Easier to look it up in a dictionary. |
t̬ |

Monday 19 May 2008 | BrE and AmE: readers replySeveral readers have commented on the question of BrE vs AmE (blog, 15-16 May). First, what are the facts about current practice? Gunnel Melchers writes from Stockholm: Swedish schools have not been required to teach BrE (RP) for decades, as can be seen in some detail in the general school curriculum. In reality, though, there has been a lingering attitude among the majority of teachers to favour RP, but according to some recent attitude studies done by our students this is now changing. Petr Rösel reports: My experience with German students of English who come to my phonetics classes at university is that they have [typically] been taught English at secondary school for seven to nine years by different teachers; for example, during the first two or three years their teacher spoke British English (with or without a German accent), for the next three years their instructor favoured American English and the rest of the time at secondary school they heard British English again. When they come to my diagnostic sessions I’m confronted with a hodgepodge of accents: British English with patches of Americanisms and a strong tinge of German spoken by one and the same student. And I am not speaking of errors that consist in pronouncing some isolated word in the accent they are not aiming at. On the contrary! They pronounce the non-prevocalic /r/ in some words and leave it out in others. They pronounce stop with an open /ɑ/, but dog with an /ɒ/. They flap the /t/ in city, but not in letter etc., etc. If I were sarcastic I would call it International English. No, those poor souls are to be pitied. They should not have been confronted with this diversity during their first steps into the world of English and they should have been warned and encouraged by their teachers not to mix varieties. This is not to say that they should not be able to understand different varieties! Mainz University, where I teach English phonetics (among other things), accepts both standard varieties, which is a double-edged thing (see above). This is main reason why I split my phonetics classes when it comes to practising pronunciation. I hired a native speaker of American English as a tutor. She takes care of those students aspiring to speak AmE and I look after those who want to speak BrE. But, alas, this is just a drop in the ocean. Kilian Hekhuis comments: Although BrE is still the norm taught at school, I think the average Dutch student of English is exposed far more to AmE (in all varieties) than BrE, as a result of American movies, TV series, pop music, etc. being predominant. Lee Miller challenges my claim that a native speaker of English “can operate in any kind of English-speaking environment”. (OK, this claim was much too sweeping.) I’m a native midwesterner in the U.S. I work as an interpreter using American Sign Language, and a large amount of my work now is done by video-telephone. That puts me in a position of listening to a wide variety of spoken English, primarily from areas in the U.S., but particularly with “tech support” calls it is often English as spoken in India or other countries. There are some areas of the U.S. where the spoken English used by some people is nearly incomprehensible to me, necessitating frequent requests for clarification. Particularly noticeable are areas of Kentucky, North and South Carolina, Virginia, and Georgia. There are also forms of spoken English used by African-Americans that are nearly impossible to understand; sometimes I simply have to say to the Deaf person on the videophone that “he/she said something I don’t understand”. And tech support calls with foreign speakers of English sometimes are nearly impossible. One time I was on an airplane flight and sat next to a young man . . . during the flight we chatted, and I could barely understand him, and couldn’t place his accent. I was thinking possibly Bulgarian or some other eastern European location. I finally asked him where he was from and he was a native New Zealander. I’m still pondering that particular mystery. As native speakers we do admittedly sometimes have difficulty in understanding an accent we haven’t encountered before, or even one we have. We need time to “tune in”. And it’s interesting that New Zealanders — with less than two centuries to create their own variety — should be right up there with Ulstermen and American southerners in presenting a challenge to the rest of us. But the lesson of Lee’s experience is something we often say: that EFL learners should be exposed (passively) to a wide variety of types of English even if their teachers, dictionaries and textbooks offer a single standardized model for imitation. |
|

Saturday 17 May 2008 | Chandler HouseUCL Language Sciences have now moved into their new premises at Chandler House, ten minutes away from the main campus. There was a welcome party yesterday evening. The thoroughly refurbished building, formerly home to Human Communication Sciences (speech therapy), is delightful. It is light and airy and gives an impression of spaciousness. You look out onto trees and greenery. People say they are pleasantly surprised. So, just a century after Daniel Jones started lecturing on phonetics at UCL, we say farewell, Gordon Square. |
|

Friday 16 May 2008 | BrE and AmE (cont.)I have not yet really answered Richard Rosser’s main point (blog, yesterday), which is the fear that “RP is ... under pressure from GA” and that “we shall have to let RP go”. There may be two separate issues here:
Despite what I said yesterday, most EFL learners do not have the luxury of extended one-to-one or small-group interaction with NSs: they depend on study, facilitated by a teacher (who may or may not be a NS). And those who train the teachers are rightly reluctant to restrict their phonetic description and practical training to English-as-a-lingua-franca minimalism. They want a complete codified model of English pronunciation that they can teach and examine. Everybody should have passive ability in as many kinds of English as possible. But what do we take for our classroom standard? What should dictionaries and textbooks show? Let’s run over some of the arguments in favour of the two pronunciation models for EFL: BrE (which means, by default, RP) and AmE (by default, GA). In favour of BrE:
In favor of AmE:
Which model a teacher trainer should adopt is usually determined not by the individual, but by the relevant ministry of education and examination system. But those responsible for these high-up decisions also have to weigh the pros and cons. Current officialdom in the Netherlands may prescribe RP. But the reality in that country, it seems to me, is a mixed kind of English that is based on BrE but adds various institutionalized Dutch influences such as the peculiar Dutch r-sound, a sort of palatalized molar r, used in the positions where non-rhotic BrE has no r-sound. The typical Dutch failure to master ð is irritating to English NS listeners but does not seriously inhibit intelligibility. Likewise the lack of aspiration for voiceless plosives. Similarly in Scandinavia. Schools, I think, are supposed to teach RP (though universities may also offer GA). Yet very many ordinary Scandinavians, despite an excellent general fluent ability in British-style English, nevertheless mispronounce z as s, again mostly without causing misunderstandings. You may be interested to follow these matters up in Adam Brown’s excellent Pronunciation Models (Singapore University Press, 1991). See also Jack Windsor Lewis’s current blog, and Collins & Mees Practical Phonetics and Phonology (Routledge, 2003, 2008). * * * Let’s leave for another day the question of whether BrE necessarily means RP. |
|





Blogroll links:
- DCblog (David Crystal)
- Language Log (Mark Liberman, Geoff Pullum et al.)
- John Maidment
- Linguism (Graham Pointon)
- PhonetiBlog (Jack Windsor Lewis)
Archived:
To search my web pages, use this Google search.