
SFS Manual for Users
3. SFS Utilities
3.1
'scopy'
The utility scopy may be used to make a physical copy of an existing data item. Items can be duplicated within a single file, or they can be copied from one file to another. Thus the command line
% scopy -isp life test
copies the last speech item from file life into file test - which must have been created previously using hed. For the scopy program, an input item must be specified, using the standard notation ('-i' switch, see section 2.3). The command line
% scopy -i 2.01 life
duplicates the item 2.01 (giving the copy a new number) in the file life. The history string for this item will be simply: 'scopy(2.01)', whereas for items copied across files, the name of the source file and the original item history may also be found in the new item history.
The duplication of an item with scopy can be useful during program development. When the output of two versions of a program need to be compared, it is necessary to keep separate history records for the two outputs, but it may be the case that the two versions generate identical history strings. In this case scopy can be used to keep a record of the output of the earlier version without it being over-written by the output of the later version.
In many cases, the program slink, described below, is preferable to scopy. slink creates a new item in a file which appears to be a copy of a data set, but is in fact merely a pointer to the data set. Thus slink may be used to avoid duplication of data. The scopy of a linked item is however a physical copy of the data set in the destination file.
3.2
'slink'
The slink utility creates a new data item in a file, in a similar manner to scopy. But whereas scopy makes a physical copy of the source data set in the given file, slink merely generates a pointer to the data set. The item generated by slink appears to processing programs as a physical copy of the data: since access to the data is automatically re-directed to the actual source. Thus it is possible to have one physical copy of a data set, say a speech waveform, and have many files linked to it. Each file may be processed independently, without duplicating the original data or leaving it open to accidental change.
slink has the following modes of operation:
- create an item linked to a whole data set in the same or a different file.
- create an item linked to a portion of a data set in the same or a different file.
- create an item linked to foreign format data file.
- create a virtual file in which every item is linked to a data set in a master file.
The first mode may be used to link any item in an SFS file to any other SFS file. The following commands demonstrate the basic process:
% summary -isp. life 1. SPEECH (1.01) 12000 frames from inwd(freq=10000) % slink -isp. life test % summary test 1. SPEECH (1.01) 12000 frames from slink(1.01;file=life, item=1.01,history=inwd(freq=10000))
This new linked item in test may be processed or replayed (or linked to) using any SFS program just as if it physically existed in the file. Since it is simply a pointer, however, it occupies much less space than the original waveform.
The second mode of slink allows the link to point to a portion of a data set. Thus items can be created and analysed as though they were physical excisions from a larger data set. Currently, slink only allows these types of links to SPEECH and LX type data sets. To specify that a linked item should refer to part of the source data set, slink accepts the switches '-s start' and '-e end', where start and end are in seconds, or the switches '-S start' and '-E end', where start and end are in samples:
% summary -isp. life 1. SPEECH (1.01) 12000 frames from inwd(freq=10000) % slink -isp. -s 0.5 -e 0.6 life test % summary test 1. SPEECH (1.01) 1000 frames from slink(1.01;file=life, item=1.01, start=5000,end=6000,history=inwd(freq=10000))
The third mode of operation of slink allows the user to link a binary data file as a linked item in an SFS file. In this mode, slink must be provided with an indicator of the output item type ('-i' flag for SPEECH and LX only) and the sampling frequency ('-f' flag). In the following example, assume the file data contains a binary waveform sampled at 10000 samples/second:
% summary data summary: access error on 'data' % slink -isp -f10000 data test % summary test 1. SPEECH (1.01) 2340 frames from slink(file=data,freq=10000)
The first command demonstrates that data is not an SFS file. The second performs the link to the SFS file, supplying both the major type of the data set ('-isp') and the sampling frequency ('-f10000'). slink may also be used to link data from other signal file formats, including WAV, AU and AIFF formats; for example:
% slink -isp -tWAV ding.wav ding.sfs % slink -isp -tAU rooster.au rooster.sfs % slink -isp -tAIFF sine.aif sine.sfs
The fourth mode for slink generates a number of linked items, each of which points to a data set in given file. This mode allows a user to make an apparent copy of a complete data file, but in such a way that further processing of the data will not affect the original. Also the copy will occupy much less space than the original. For this mode to be selected, the destination SFS file must not exist, it will be created by slink with a copy of the main header from the original file. Thus:
% summary demo 1. SPEECH (1.01) 8960 frames from inwd(freq=10000) 2. COEFF -(11.01) 532 frames from spectran(1.01;window=8,overlap=6) 3. DISPLAY (9.01) 532 frames from dicode(11.01;dbr=50.00,nump=128) % slink demo newfile % summary newfile 1. SPEECH (1.01) 8960 frames from slink(file=demo,item=1.01, history=inwd(freq=10000)) 2. DISPLAY (9.01) 532 frames from slink(file=demo,item=9.01, history=dicode(11.01;dbr=50.00,nump=128))
Note that links are not made to deleted items.
The manual page for slink gives more detail of its operating limitations and describes additional flags for linking to binary files which are stored in odd formats (byte-reversed, DC offset etc).
A linked item affords protection of the original data set, in that no operation on the linked item can affect the original. However there is no protection against direct operations on the original data. The SFS routines detect circumstances in which the original data set is deleted or changed, reporting messages such as 'sfs: linked item out of date' if there has been any change to the data since the link was set up.
3.3
'remove'
The remove utility may be used to delete data items from an SFS file. remove accepts a list of items using the standard item specification scheme ('-i item') as extended in summary to cope with all items of a given type ('-a item'). Thus the command line:
% remove -isp. -afx test
will remove the first speech item and all fundamental frequency items from the file test.
When remove makes a change to a file, it actually makes a copy of the file with the requested changes. The original file is left unchanged but with a filename modified to have a '.bak' extension. This allows recovery from single accidental changes to the file (second and further changes overwrite the '.bak' file).
When an item is specified for removal in the command line, remove will always remove the data set; under some circumstances, however, remove will leave behind the item header for the data set in a modified form: called an item stub. The item stub consists of the item header for the deleted item, but with its major type field negated, and with its length set to zero. The item stub cannot be selected for processing, and does not interfere with the processing of other items in the file. Item stubs are indicated in the list produced by summary with a '-' flag before the item number.
The item stub is required when the item requested for deletion forms part of the processing path of other data sets in the file (data sets not also selected for deletion). If remove were to completely delete the item, the processing history for these later data sets could not be traced back to the primary sources of data in the file.
When remove scans a file, it checks to see if the selected items are part of the processing path of later items, and also checks to see if any item stubs in the file are still required. Thus item stubs may be deleted when other items are requested for removal simply because they are no longer required.
remove has a switch '-s' which indicates that the items for removal consist of the items specified and all other items that have been subsequently processed from a deleted item. This is a convenient way of removing a whole branch of a processing tree.
If remove is executed with no items specified for deletion, it enters a prompted mode in which the processing history of each item is presented, and the user can answer 'y' or 'n' to request removal. The '-s' option may also be used in this mode.
3.4
'Ds' & 'dig'
The utility Ds is a general purpose static display facility for data sets. The next section describes Es, an interactive version of Ds. The utility dig is a device-independent graphics display routine. Together, these utilities may be used to create graphs of speech data, display graphs on a range of graphic display terminals, store graphs in files, and print graphs on a range of hardcopy devices.
The default operation of Ds is to display on the current terminal all of the data sets in the current file. The default display width in seconds is taken from the first speech item in the file, or is set to 1 second. A typical Ds display is shown in Figure 1. Here you can see that the display consists of three items: a speech waveform, a fundamental frequency track and a set of formant estimates. Note that Ds automatically formats the display for the number and type of items. The items are displayed in the order they appear in the file.
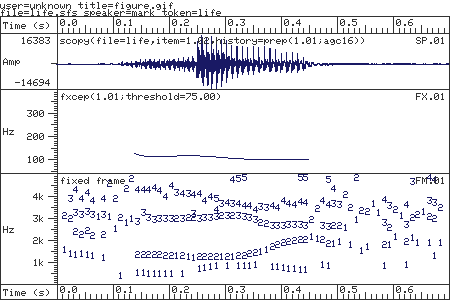
Each item displayed with Ds has a title and a label, displayed at the top left and top right of the display box respectively. In default operation, the label is simply the item number and the title is a text description of the data set generated automatically from its processing history. The generation of text descriptions is described in section 4.3. Where no text description has been defined, the history string is printed instead.
Individual items and all items of a given type can be selected by '-i' and '-a' flags as normal. The order of item selection does not alter the order in which items are displayed.
The Ds flag '-p' requests that output is sent directly to the printer.
Displays of part of the timescale may be selected using the flags '-s starttime' and '-e endtime' (all times in seconds). If not specified, the default start time is 0.0, and the default end time is the duration of the first speech item in the file (or 1.0 seconds if not found).
Displays of part of the y-axis of items of a given type may be specified using the '-f item ymin ymax' flag. This switch fixes the lower y-axis limit of all data sets of type 'item' to 'ymin', and the high y-axis limit to 'ymax', e.g.:
% Ds -isp. -afx -f fx 100 250 file
At present, this options is only implemented for some item types.
The command-line switches of Ds do not allow full control over the format of the display produced. To obtain arbitrary item ordering, titles, labels and sizes, it is necessary to use a display control file. Details of the format of the display control file may be found in the manual page.
A display produced by Ds may be stored in a file by simply re-directing the output of the program on the command line. Thus the command:
% Ds -asp test > waves.g
will create a file waves.g containing a coded representation of the normal diagram produced by Ds. Stored graphs may be edited using the Unix utility ged(1). Graphs in files may be re-displayed on a graphics terminal or sent to the laser printer with the program dig. The command:
% dig waves.g
will re-display the stored graph on the current terminal. Because of the generic coding used in the file, the graph will be slightly inferior to the graph produced by Ds directly onto the terminal. Also note that at present, grey scale images can not be stored in files, and so display boxes containing grey-scale images will appear blank if they have been stored in files or piped to dig. The dig option '-p' directs the graph to the laser printer.
3.5
'Es'
The program Es produces graphs substantially similar to Ds but allows the user to interactively control the time window displayed by placing cursors with a mouse and selectively 'zooming-in' or 'scrolling' the display. Selected portions of items may also be replayed through a Digital-to-Analogue converter if available. Es may also be operated in a labelling mode whereby speech material may be annotated, or existing annotation data sets may be edited.
Normal Mode
The initial display of Es looks the same as the default display for Ds given a set of item selections. The top right hand corner of the display contains four mouse control boxes however, and the keyboard may also be used to enter interactive commands. The interactive commands available using Es are:
Place 'start' marker: Use left mouse button.
Place 'end' marker: Use right mouse button.
Replay item: Use middle mouse button. (If you have a 2-button mouse, click the left button over the speech signal and type 'p')
Zoom in to selected region: Use mouse on 'zoom' box, or 'z' key.
Zoom out again: Use right button on zoom box, ot middle button on 'move' box, or 'u' key.
Scroll left: Use left button on 'move' box, or 'l' key.
Scroll right: Use right button on 'move' box, or 'r' key.
Display top-level: Use 't' key.
File operations: Use mouse on 'file' box, or 'f' key.
Copy data: Use mouse on 'copy', or 'c' key.
Link data: Use mouse on 'link', or 'l' key.
Print hard-copy: Use mouse on 'hard', or 'h' key.
Tree display: Use mouse on 'tree', or 't' key.
Quit program:Use mouse on 'quit' box, or 'q' key.
If the mouse cursor is not over a speech item when the Replay request is made, Es searches back up the history tree (see section 3.6) for the displayed item and replays the first speech item found.
Labelling Mode
To execute Es in labelling mode, include the switch -l labelname on the command line. The labelname parameter is a text label given to the set of annotations created by Es. A file can contain a number of sets of annotations, provided they have different labels. Thus to annotate a piece of speech with a phonemic transcription one might use:
% Es -isp. -ilx. -l phonemic datfile
In labelling mode, there is a small annotation window at the bottom of the screen where annotations are listed. The normal functions of Es for selective zooming, scrolling and printing of the display are still available. The replay command using the middle button works slightly differently, and there is a new annotation control command entered from the keyboard.
In labelling mode, the middle button replays different sections of the display depending on the location of the mouse and the cursors. Left of the start cursor, the section of the waveform up to the start cursor is replayed. Right of the end cursor, the section after the end cursor is replayed. With the mouse between the two cursors, the section between the cursors is replayed. (The same functions are also on the 'o', 'p' and '[' keys)
To add an annotation, locate the point in time using the start cursor (left button), press mouse button in 'anno' box (or key 'a') and type the text of the label, then key [RETURN]. Mis-keyed characters may be deleted with [DELETE]. The annotation should appear below the start cursor.
To delete an annotation, locate the start cursor directly over the existing annotation point, key 'a' and [RETURN] only. To change an annotation, locate the start cursor over the existing annotation point, key 'a', the text of the new label, and then [RETURN]. To move an annotation, click the middle mouse button on the annotation and then click the left or the right mouse button at the new position. To annotate at the right cursor rather than the left cursor, use the 'b' key instead
When Es ends after a labelling session, it asks if you want to save the annotations. Type 'n[RETURN]' if you do not want them saved.
3.6
'pick'
The utility pick provides a menu-driven item selection facility that can be used with utility or speech processing programs. The utility fills in the '-i item' components of a command line from menu selections chosen by the user. In its simplest mode, the program accepts a program command and a filename and builds a menu from the items in the file. Items can now be selected from the menu by typing their menu index and [RETURN]. Typing a [RETURN] only tells pick to execute the given program with the chosen item selections. Thus:
% pick Ds test 1. 1.01 natural speech 2. 2.01 natural lx 3. 3.01 tx from lx Enter selection : 1 Enter selection : 3 Enter selection : __ executing: Ds -i 1.01 -i 3.01 test
would generate a diagram based on the chosen items. The text descriptions of the items in pick are generated from the text label facility used by Ds and described in 1.4.3. The program command to be executed with the chosen items must be the second argument to pick, even if it consists of more than one word. Thus to execute a command consisting of a program name and switches, these need to be enclosed in double quotes, e.g.:
% pick "Ds -p" test etc
pick also has a fast mode, whereby a single item may be selected, pick executes the program and then prints the item selection menu again for subsequent single choices. pick continues to execute the given command an print the menu until the user types [RETURN] only. This mode is most useful for replaying data sets, and is distinguished from the first mode by the fact that the third argument to pick is an item type:
% pick replay 1 test2 SPEECH item menu 1. 1.01 natural speech 2. 1.02 software synthesizer Enter selection : 1 executing: replay -i 1.01 test2 SPEECH item menu 1. 1.01 natural speech 2. 1.02 software synthesizer Enter selection : 2 executing: replay -i 1.02 test2 SPEECH item menu 1. 1.01 natural speech 2. 1.02 software synthesizer Enter selection : __
3.7
'apply'
Most programs written for SFS files operate on only a single file at a time. The utility apply is a simple script for executing a program on a number of files in sequence. When a command line is prefixed with apply the first argument is taken as a program name and parameters, and the rest of the command line is taken to be a sequence of filenames. Thus:
% summary -isp. file1 1. SPEECH (1.01) 12300 frames from inwd(freq=12800) % summary -isp. file2 1. SPEECH (1.01) 11800 frames from inwd(freq=12800) % summary -isp. file3 1. SPEECH (1.01) 21000 frames from inwd(freq=12800) % apply "summary -isp." file1 file2 file3 file1: 1. SPEECH (1.01) 12300 frames from inwd(freq=12800) file2: 1. SPEECH (1.01) 11800 frames from inwd(freq=12800) file3: 1. SPEECH (1.01) 21000 frames from inwd(freq=12800)
An option '-i' to apply allows the user to select items for processing from a list:
% apply -i "Ds -p -afx -isp." * file1: y file2: n file3: q %
Reply 'y' or [RETURN] to execute the command on the filename, 'n' or 's' to skip, and 'q' to quit the apply process.
For circumstances where the choice of file or processing program relies on a more sophisticated analysis of the contents of the file, the user is recommended to write a small SML program (see section 5).
Next Section