KLAIR Project
Mark Huckvale (UCL), Ian Howard (Cambridge), Sascha Fagel (Berlin)
A virtual infant for spoken language acquisition research
The KLAIR project aims to build and develop a computational platform to assist research into the acquisition of spoken language. The main part of KLAIR is a sensori-motor server that displays a virtual infant on screen that can see, hear and speak. Behind the scenes, the server can talk to one or more client applications. Each client can monitor the audio visual input to the server and can send articulatory gestures to the head for it to speak through an articulatory synthesizer. Clients can also control the position of the head and the eyes as well as setting facial expressions. By encapsulating the real-time complexities of audio and video processing within a server that will run on a modern PC, we hope that KLAIR will encourage and facilitate more experimental research into spoken language acquisition through interaction.
Current Development Status & Plans
| Sep 2009 | Version 1.0 is made available. This is the first release of the KLAIR server together with documentation for the interface API and sufficient example code for development of client applications in C and MATLAB. | |
| Sep 2009 | Presentation at Interspeech 2009 Brighton: M.Huckvale, I.Howard, S.Fagel, "KLAIR: a Virtual Infant for Spoken Language Acquisition Research", Proceedings 10th Interspeech Conference, Brighton, U.K. Download PDF. | |
| Sep 2010 |  Start of project to collect caregiver dialogues using KLAIR. We have acquired over 1 hour of video interactions between 10 caregivers and KLAIR.
This has resulted in 800 separate learning interactions in which the caregiver responds to KLAIR's behaviours in a toy naming task.
Analysis of the lexical and prosodic properties of these should be available in September 2011. Start of project to collect caregiver dialogues using KLAIR. We have acquired over 1 hour of video interactions between 10 caregivers and KLAIR.
This has resulted in 800 separate learning interactions in which the caregiver responds to KLAIR's behaviours in a toy naming task.
Analysis of the lexical and prosodic properties of these should be available in September 2011.
| |
| Aug 2011 | Version 2.0 is now available for download. This release contains the KLAIR server, some utility programs and example clients developed in C++, MATLAB and VB.NET. | |
| Aug 2011 | Presentation at Interspeech 2011 Florence: M.Huckvale, "Recording caregiver interactions for machine acquisition of spoken language using the KLAIR virtual infant", Proceedings 12th Interspeech Conference, Florence, Italy. Download PDF. | |
| Aug 2013 | Presentation at Interspeech 2013: M.Huckvale, A.Sharma, "Learning to imitate adult speech with the KLAIR virtual infant", Proceedings 14th Interspeech Conference, Lyon, France. Download PDF. |
Klair Server Configuration
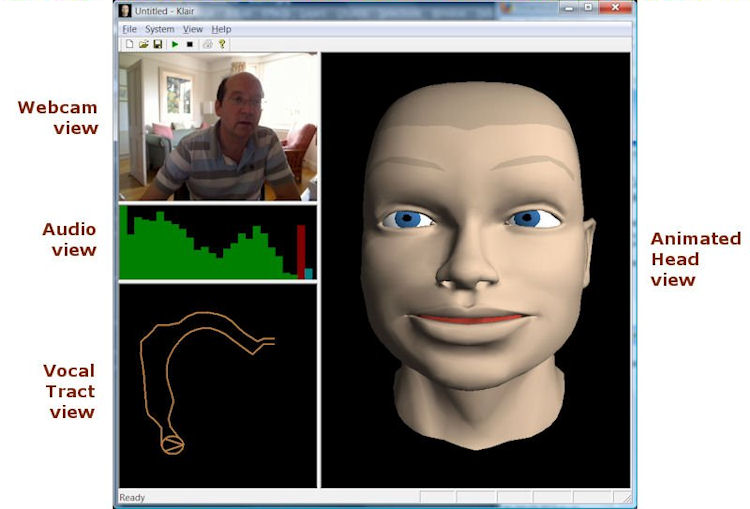
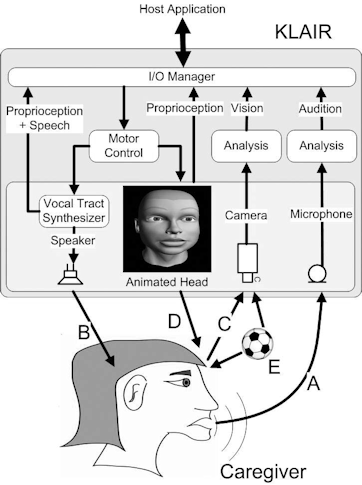 The KLAIR toolkit is designed to run on a modern Windows PC with a microphone, speakers, webcam, mouse and screen. The central component is the sensory-motor server application that provides sensory input and motor output for a separate machine learning client application. The server runs multiple real-time processing threads, while the learning system runs asynchronously in the background and polls the server to input audio, video and sensory signals, or to deliver facial expressions or vocal output. See Figure on right. The server can optionally log all I/O to disk for off-line processing.
The KLAIR toolkit is designed to run on a modern Windows PC with a microphone, speakers, webcam, mouse and screen. The central component is the sensory-motor server application that provides sensory input and motor output for a separate machine learning client application. The server runs multiple real-time processing threads, while the learning system runs asynchronously in the background and polls the server to input audio, video and sensory signals, or to deliver facial expressions or vocal output. See Figure on right. The server can optionally log all I/O to disk for off-line processing.
The audio output stream is generated through an adaptation of the articulatory synthesizer of Shinji Maeda to approximate an infant-sized vocal tract. This takes 12 articulatory parameters as input: JW: Jaw Position, TP: Tongue Position, TS: Tongue Shape, TA: Tongue Expansion, LA: Lip Aperture, LP: Lip Protrusion, LH: Larynx Height, NS: Velopharyngeal port opening, GA: Glottal Aperture, FX: Fundamental Frequency, VQ: Voice Quality, and PS: sub-glital pressure. Dynamical smoothing of the parameters over time using a critically-damped second-order spring-mass system is applied.
The visual appearance of the server is as an infant talking head. This is an OpenGL implementation of the talking head MASSY, adapted to appear as a virtual human infant. The head is controlled using three sets of animation parameters: one describing head & eye position, one describing movements of the speech articulators and one describing movements necessary for facial expressions. The 6 articulatory parameters are: vertical jaw opening, tongue advancement/retraction, vertical tongue dorsum position, vertical tongue tip position, vertical lip opening, and lip spreading/protrusion. This parameter set is designed to enable the display of visually distinguishable German and English phonemes. Their values are derived automatically from the articulatory synthesis parameters. The 23 facial expression parameters are: inner eyebrow riser, outer eyebrow riser (left/right), eyebrow depressor, upper and lower eyelid depressors (l/r each), cheek raiser (l/r), nose wrinkle (l/r), nose wings opener, upper and lower lip raisers and protruders, lip stretchers and depressors (l/r each), and jaw advancer and side shifter. A huge variety of facial expressions, e.g. for displaying emotional states, can be obtained by combining these facial expression parameters. The set of animation parameters is inspired by action units of the facial action coding system, but is in contrast to FACS designed for the generation of facial expressions instead of their description.
The audio input stream delivers information about the loudness, pitch and timbre of sounds currently being acquired from the microphone or generated by the articulatory synthesizer. A psychoacoustic model of the auditory periphery is used to deliver estimates of loudness. An autocorrelation analysis provides estimates of pitch, while an auditory filterbank based on the channel vocoder provides estimates of spectral envelope across 24 frequency channels. Estimates are provided in real time at 100 frames/sec.
Video capture is performed using the Windows VfW interface. The current resolution is 320x240 pixels at 10 frames/sec. Captured frames are each converted to an RGB bitmap.
The client can also obtain proprioception input from the server. Proprioception input returns the current vocal tract configuration, including information about articulator contact.
Machine Learning Client
An ML client contains all the machine learning components used in experiments with the toolkit. The client communicates with the server through asynchronous remote procedure calls (RPC). We anticipate a rather slow polling rate of about 10 calls/sec, transferring 10 audio frames and one video frame per call, but higher rates are possible. The server will maintain a short history of frames for when the client falls behind. We have endeavoured to make the interface as simple as possible and not to restrict the computer languages in which the executive may be programmed by toolkit users. In particular we provide a MATLAB interface to the RPC mechanism.
Demonstration Control Panel
The Klair Control Panel is useful for testing and demonstrating the Klair server.
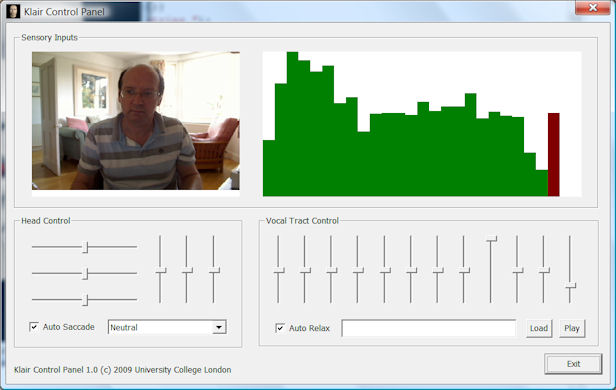
The control panel application can be run on the same computer as the server, or can communicate over the network. To connect to a remote server, start with the name of the server, e.g. "klairctl \\servername". The control panel polls the server to obtain current camera and audio inputs, and can queue head position, facial expression and vocal tract shape commands. The check boxes turn on/off the automatic head position changes, and the behaviour of the server to return to a neutral articulatory configuration after speaking. You can use the control panel to demonstrate some of Klair's individual parameters, or to replay a text file of articulatory synthesis parameters. Here is an example synthesis file.
MATLAB interface
The Klair server can be controlled from a MATLAB program using the supplied "klair_action" command. This is a MEX function for Windows PCs implemented as a DLL. The klair_action command provides essential functionality for connecting to the server, for receiving audio and video blocks and for queuing head, facial expression and articulation commands. You can read documentation on klair_action.
.NET interface
Clients can also be developed in the .NET languages, using the KlairLink API provided in release 2.0. This allows rapid prototyping of clients for experiments, and access to the .NET speech recognition engine. Contact Mark Huckvale for a .NET project that demonstrates speech recognition with KLAIR.
RPC interface
Client applications can also be developed in other languages and can be run on other platforms because of the device and network independence of the remote-procedure call (MS-RPC) mechanism used.
Publications
- Howard, I., Huckvale, M. (2004), "Learning to control an articulatory synthesizer through imitation of natural speech", Summer School on Cognitive and physical models of speech production, perception and perception-production interaction, Lubin Germany, Sept 2004. Web site.
- Huckvale, M., Howard, I. (2005), "Teaching a vocal tract simulation to imitate stop consonants", Proc. EuroSpeech 2005, Lisbon, Portugal. Download PDF
- Howard, I., Huckvale, M. (2005), "Training a Vocal Tract Synthesizer to Imitate Speech using Distal Supervised Learning", SpeCom: 10th International Conference on Speech and Computer 2005, Patras, Greece. Download PDF
- Howard IS, Messum P (2007), "A Computational Model of Infant Speech Development", XII International Conference "Speech and Computer" (SPECOM'2007).
- Howard IS, Messum P (2008), "Modelling motor pattern generation in the development of infant speech production", Eighth International Seminar on Speech Production (ISSP'08)
- Huckvale, M., Howard, I., Fagel, S. (2009), "KLAIR: a Virtual Infant for Spoken Language Acquisition Research", Interspeech 2009, Brighton, U.K. Download PDF.
- Howard IS, Messum P (2011), "Modeling the development of pronunciation in infant speech acquisition", Motor Control 15(1):85-117
- M.Huckvale (2011), "Recording caregiver interactions for machine acquisition of spoken language using the KLAIR virtual infant", Proceedings 12th Interspeech Conference, Florence, Italy. Download PDF.
- M.Huckvale (2011), "The KLAIR toolkit for recording interactive dialogues with a virtual infant", Proceedings 12th Interspeech Conference, Florence, Italy. Download PDF.
- Howard IS & Messum P (2011), "Modelling caregiver tutored development of pronunciation in a young child" Proceedings of 22nd German Conference on Speech Signal Processing, ESSV 2011, 28-30 September, Aachen, Germany.
- Howard IS & Messum P (2011), "The computational Architecture of Elija: A model of a young child that learns to pronounce", Proceedings of 22nd German Conference on Speech Signal Processing ESSV 2011, 28-30 September, Aachen, Germany.
- M.Huckvale, A.Sharma (2013), "Learning to imitate adult speech with the KLAIR virtual infant", Proceedings 14th Interspeech Conference, Lyon, France. Download PDF.