1. Introduction
This paper reports some work carried out as part of a program
investigating the effects of acoustic cue enhancement on the intelligibility
of natural and synthetic speech. This approach aims to enhance
relatively clear speech before degradation by noise, reverberation
or band-pass filtering and therefore differs from conventional
signal enhancement which is largely concerned with the removal
of additive noise through techniques such as spectral subtraction,
adaptive filtering, adaptive noise cancellation, and harmonic
selection. While these methods appear to improve signal quality,
they show only small increases in intelligibility (e.g., Cheng,
O'Shaughnessy & Kabal, 1995).
When describing methods which enhance speech prior to degradation, a distinction must be made between those techniques which apply enhancements automatically to portions of the signal which display certain characteristics (e.g. regions characterised by fast spectral change) and those which apply enhancements to specific phonetic segments and so require the speech signal to be annotated in terms of its phonetic components.
Automatic enhancement methods such as those involving high-frequency emphasis or removal of the first formant can have a significant effect on intelligibility; however, these have shown most benefit in conditions of extreme distortion, such as infinite clipping, which have a very substantial effect on signal quality (Niederjohn & Grotelueshen, 1976). More recently, Tallal and her colleagues (Tallal et al., 1996) have applied automatic enhancement techniques which involve amplifying regions of rapid spectral change and manipulating segment durations. These were found to be beneficial in speech training with language-disordered children believed to have specific difficulty in processing sounds containing fast spectral change.
Methods in which signals are segmented and labelled using phonetic knowledge permit the manipulation of specific, perceptually-important, regions which may not be reliably identified via the types of signal processing techniques described above. Many concentrate on enhancing 'landmark' regions of the signal that are known to contain a high density of cues to phonetic identity (Stevens, 1985). These 'landmark' regions can be inherently transient and of low amplitude, such as the perceptually-important formant transitions following plosive release which are both brief and of low initial intensity as vocal fold vibration starts. Phonetically-motivated enhancement approaches have been used to increase the salience of these information-bearing regions by increasing their relative intensity or duration. By making it easier for normally-hearing listeners to process acoustic cues contained in these segments, the speech signal could become more resistant to subsequent degradation.
Techniques which enhance clear speech prior to degradation can be applied in telecommunications (e.g. telephone-based information services, or communication in noisy aircraft) where the communication channel can significantly degrade the speech signal. There are also applications in speech and language therapy and second language learning where certain perceptually-important portions of the speech signal can be emphasised in a computer-based training system to help listeners develop phonetic discrimination abilities. Jamieson (1995) used such an approach successfully in auditory training in second-language learners. These techniques have also been investigated with the view to improve speech intelligibility for listeners suffering from different types of hearing disability. For example, Gordon-Salant (1986) explored the effects of increasing consonant duration and consonant-vowel intensity ratio in a set of nonsense syllables presented to normally-hearing and hearing-impaired listeners. The manipulation of intensity ratios had the greatest effect on intelligibility. This phonetically-motivated approach has therefore clearly been successful although the need for pre-annotated material is a serious limitation in the use of these techniques.
The objectives of the work reported here are to determine the cue-enhancement strategies which are likely to have the greatest effect on intelligibility but which are also easily implemented in signal processing terms. Manipulations were primarily made to the relative intensity and the spectral shape of different portions of the signal. In the first experiment, the effect of cue-enhancement was examined using controlled nonsense Vowel-Consonant-Vowel (VCV) material which contained no contextual information. In this way, segmental intelligibility based on the perception of acoustic information alone can be evaluated. In the following experiments, similar cue-enhancement strategies were implemented in sentence-length material which exhibits a much higher degree of variability in vocalic context and degree of coarticulation.
2. VCV material enhancement
2.1 Method
36 vowel-consonant-vowel (VCV) stimuli comprising the consonants
/b,d,g,p,t,k,f,v,s,z,m,z/ in the context of the vowels /a,i,u/
spoken by a male speaker were recorded and digitized at 48 kHz
sampling rate with 16-bit amplitude quantization. Annotations
were made manually using a waveform editing tool to segment the
stimuli into different sections. The relative levels of sections
of the stimuli were then manipulated before the stimuli were reassembled
by abutting adjoining segments and then down-sampling the resultant
stimuli to 16 kHz to smooth any waveform discontinuities at segment
boundaries. Amplitude manipulations were made by calculating
the mean RMS level of each segment of the stimulus; with reference
to this level sample values within a segment were then scaled
to either produce a relative amplitude increase, or to set the
mean RMS level of a number of segments to the same value.
After manipulation, stimuli were combined with noise which had the same spectral envelope as the long-term average spectrum of speech. Signal-to-noise ratios (SNRs) of 0 and -5 dB were calculated on a stimulus by stimulus basis and took into account any change in the amplitude of the stimulus produced as a result of enhancement. The noise started 100 ms before the onset of the first vowel and finished 100 ms after the end of the second.
For all stimuli a distinction was made between (a) the transition
regions between vowel and consonant, and (b) the consonantal constriction/occlusion
regions, i.e. the burst transient, burst and aspiration, frication
or nasality portions. For the transition portions, the problem
of reduced amplitude as the consonant constriction/occlusion was
formed or released was counteracted by amplifying the final five
cycles of the first vowel, or the initial five cycles of the second
vowel. This was done by setting the level of the first four cycles
to the level of the fifth cycle. The amplitude of the consonant
occlusion/constriction region was amplified by either 6 or 12
dB according to consonant category (see Table 1).
|
|
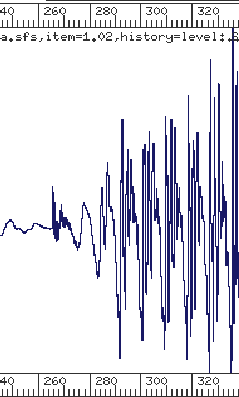
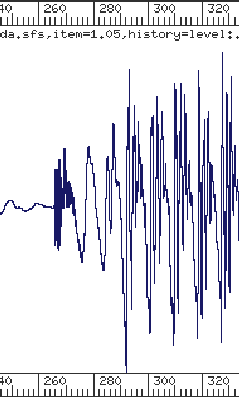
Figure 1: Waveforms of burst and formant transition regions
of /d/ in 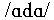
|
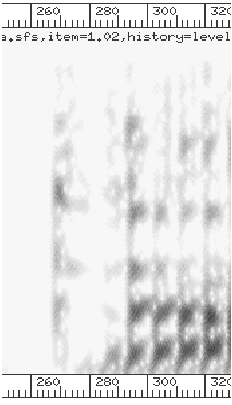
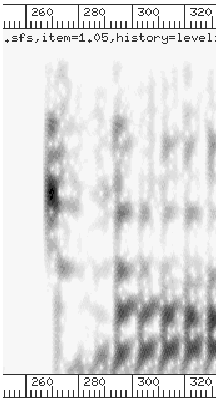
|
Figure 2: Spectrograms of the burst and initial transition
regions in
(natural and BTF conditions).
In two further conditions filtering was used to change the spectral content of perceptually-important regions in order to make them more discriminable. For plosives, the burst spectrum was examined to locate the greatest concentration of energy; the precise location varied depending on the vowel context but was around 300 Hz for labials, between 1.2 and 3 kHz for velars, and between 2.5 and 4 kHz for alveolars. The burst was then band-pass filtered to retain energy at and around this frequency with the width of the pass-band set to four times the ERB (Glasberg and Moore, 1990) at this frequency. For the fricative stimuli, the frication region was filtered to enhance the contrast in its lower-cut-off frequency, a cue to place of articulation in fricatives. The fricatives /f,v/ were high-pass and band-stop filtered respectively so that frication only appeared above 1 kHz; /s,z/ were filtered so that aperiodic energy only appeared above 4 kHz. No filtering was performed on nasal consonants. In summary, the following test conditions were used: in condition B, only the occlusion/constriction region was amplified; in condition BT, both the occlusion/constriction and format transition regions were amplified; in condition BF, the occlusion/constriction region (for plosives and fricatives) were filtered before being amplified; in condition BFT, all types of manipulations were applied.
| B | BT | BF | BFT | |
| Plosives | Burst:12dB | Burst:12dB Transitions:+ |
Burst:filtered, +12dB | Burst:filtered, +12dB, aspiration + 6dB Transitions+ |
| Fricatives | Friction:+6dB | Friction:+6dB Transitions:+ |
Friction:filtered +6dB | Friction:filtered +6dB Transitions+ |
| Nasals | Nasality:+6dB | Nasality:+6dB Transitions+ |
Nasality:+6dB | Nasality:+6dB Transitions+ |
Table 1: Manipulations applied in the VCV Experiment
2.2 Subjects
13 listeners aged between 20 and 35 with pure tone thresholds
below 20 dB HL were tested.
2.3 Test procedure
Listeners were tested individually in a sound-attenuating room,
using a computer-based testing procedure. Stimuli were presented
binaurally via AKG240DF headphones, and listeners responded by
pointing at a consonant only on the screen using a mouse. Listeners
heard three blocks of each enhancement condition, and three blocks
containing natural stimuli; each block contained five repetitions
of the 36 stimuli. The presentation order was randomized across
listeners. All listeners heard stimuli at 0 dB and -5 dB SNRs.
2.4 Results
Figure 3 shows the intelligibility scores for all conditions.
ANOVAs revealed that the effect of test condition was significant
at -5 dB SNR [F(4,48)=41.54; p<0.0001] and at 0 dB SNR [F(4,48)=16.04,
p<0.0001]. At both SNRs all enhanced conditions gave significantly
higher intelligibility scores than the natural condition. Filtering
combined with amplitude manipulations did produce a significant
additional improvement at the worse SNR. The highest mean increase
was 12% for -5 dB SNR and 6% for 0 dB SNR. The scores obtained
for the BFT condition at -5 dB were nearly identical to those
obtained for the unenhanced stimuli at 0 dB SNR. The effect of
the enhancement therefore corresponds to an increase in signal-to-noise
ratio of approximately 5 dB. The main effects of subject and vocalic
context were also significant at both SNRs. Duncan's Multiple
Range tests revealed that consonant perception in the /u/ context
was significantly poorer than in the /i/ and /a/ contexts (see
Figures 4 and 5).
Information Transfer analyses were applied in order to determine how well consonants were recognised in terms of their voicing, place and manner of articulation, and how the enhancements applied affected the correct labelling in terms of these features. ANOVAs were then carried out on these voicing, place and manner scores. The pattern of errors obtained is consistent with what is known about consonant perception in noise. The voicing feature was robust and was well preserved in conditions of noise degradation. However, consonants were most often confused in terms of their place of articulation, and to a lesser extent, in terms of their manner of articulation. Enhancements led to a significant increase in the correct perception of the place and manner of articulation.
Results are presented here for the BFT condition, where all types
of enhancements were applied. Results are presented separately
for the consonants in the context of the vowels
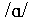 ,
/i/ and /u/.
It can be seen that recognition was poorest overall for consonants
in the context of /u/ and that the same general patterns of errors
are seen at both SNRs. In all three contexts, the greatest effect
of the enhancements applied is in the correct recognition of the
consonants' place of articulation (20% improvement in the context
of ). Manner discrimination also improved slightly, which is likely to be due
to a reduction in plosive/fricative confusions.
,
/i/ and /u/.
It can be seen that recognition was poorest overall for consonants
in the context of /u/ and that the same general patterns of errors
are seen at both SNRs. In all three contexts, the greatest effect
of the enhancements applied is in the correct recognition of the
consonants' place of articulation (20% improvement in the context
of ). Manner discrimination also improved slightly, which is likely to be due
to a reduction in plosive/fricative confusions.
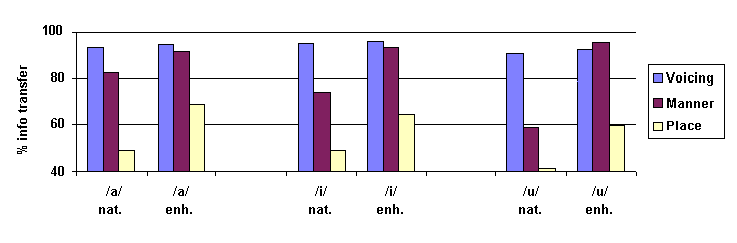
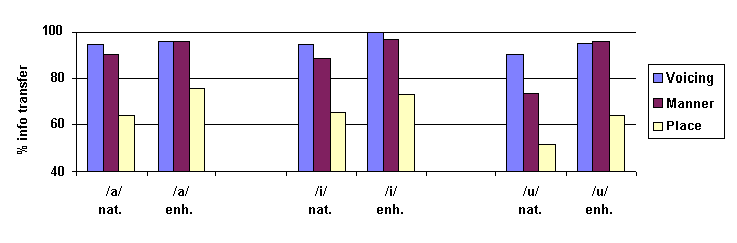
Figure 5: Correct identification of features of voicing, place and manner of articulation for consonants presented in three vocalic contexts at an SNR of 0 dB for natural and BFT conditions.
The data were analysed further to see which specific consonants benefited the most from the enhancement strategies applied. Bar charts showing the percentage of correct responses per consonant are presented in figures 4 and 5. Overall, it can be seen that all but one consonant (/g/) either showed higher or similar scores in the enhanced condition relative to the control condition. As expected, the correct identification of place of articulation of voiced plosives was particularly difficult in noise. At SNR -5 dB, /d/ identification showed a dramatic improvement after enhancement.
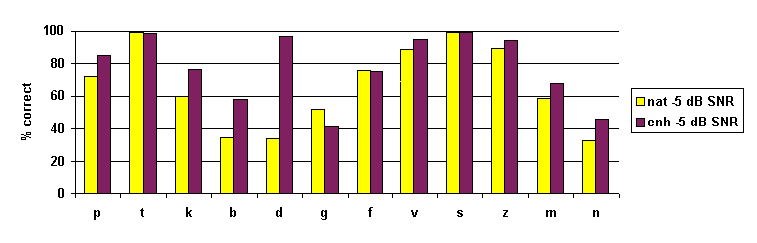 Figure 6: correct identification
of natural and enhanced (BFT condition) consonants at SNR -5 dB.
Figure 6: correct identification
of natural and enhanced (BFT condition) consonants at SNR -5 dB.
Confusion matrices for the data reveal which confusions occuring
in the natural condition were disambiguated once enhancement strategies
have been applied. At 0 dB SNR, a number of confusions are seen
within the voiceless stop (/p/-/k/)
and the voiced stop 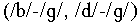 classes. The nasals /m/ and /n/ are also frequently
confused, as are the fricatives /f/ and /s/. Once enhancements
were applied, only the nasal confusions and voiced-stop confusions
remained. The enhancements therefore had the greatest effect in
disambiguating voiceless stops, and voiceless fricatives. A similar
pattern was seen at SNR -5 dB.
classes. The nasals /m/ and /n/ are also frequently
confused, as are the fricatives /f/ and /s/. Once enhancements
were applied, only the nasal confusions and voiced-stop confusions
remained. The enhancements therefore had the greatest effect in
disambiguating voiceless stops, and voiceless fricatives. A similar
pattern was seen at SNR -5 dB.
3. Sentence material enhancement
Many studies evaluating the effect of enhancement have used nonsense
VCV, CV or CVC syllables (e.g., Gordon-Salant, 1986). This is
a necessary step as it is only possible to analyse the effect
of enhancement in stimuli in which the perceptual contribution
of contextual information has been eliminated. However, the greater
degree of coarticulation and the greater variety in vocalic context
seen in sentence-level material may strongly affect the perceptual
effect of enhancements. It is therefore important to test enhancement
strategies with more natural sentence-length material whilst still
controlling the contribution of contextual information.
3.1 General Method
The second set of experiments applied similar enhancement techniques
to natural sentence materials. 50 semantically-unpredictable
sentences (SUS) (Benoit, Grice and Hazan, 1996), read by the same
male speaker as in the VCV experiment, were recorded and digitized
at 16 kHz with 16 bit amplitude quantization. SUS material was
used in order to limit the amount of contextual information present;
sentences were syntactically correct but had words with no semantic
relationship. They were constructed using five different grammatical
structures, and each sentence contained four key words. Examples
of SUS sentences are presented in Appendix I. A greater range
of consonants including affricates and approximants was manipulated
than in the VCV experiment; consonants annotated were
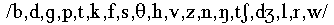 .
Sentences were annotated to identify
the consonant constriction/occlusion and transition regions as
described in the VCV experiment.
.
Sentences were annotated to identify
the consonant constriction/occlusion and transition regions as
described in the VCV experiment.
3.2 Sentence Experiment 1
3.2.1 Method
Following informal listening experiments with the SUS material
enhanced in the same way as in VCV Experiment 2, some small adjustments
were made to the enhancement strategies. Plosive and affricate
bursts were filtered, but it was necessary to use wider pass-bands
given the greater variation in centre burst frequency in this
sentence-length material. The degree of amplification of the
burst was reduced to 9 dB. Amplification was also applied to the
aspiration segments in the voiceless stops. No filtering was applied
to fricatives due to the increased variability in cut-off frequency
in these phones in sentence material. In the formant transition
regions, the five final and initial voicing cycles before and
after the consonant occlusion/constriction region were boosted
by 3 dB. After being manipulated, stimuli were combined with
speech-shaped noise at 0 dB and 5 dB SNR.
In addition, in order to check the effect of these small changes
in enhancement levels, the same manipulations that were used in
the SUS material were also applied to the VCV material described
above.
| Class | Manipulations |
| Plosives | burst: +9dB,filtered; aspiration: +9dB; transitions+ |
| Fricatives | friction: +6dB; transitions+ |
| Affricates | burst: +9dB, filtered; friction: +6dB; transitions+ |
| Approximants | constriction: +3dB; transitions+ |
| Nasals | nasality: +6dB; transitions+ |
Table 2: Manipulations applied in Sentence Experiment 1.
3.2.2 Subjects
Separate groups of listeners were used for each SNR condition
on order to avoid word learning effects. All were aged between
20 and 35 with pure tone thresholds below 20 dB HL. 12 listeners
were tested in the 0 dB SNR condition and 13 in the 5 dB SNR condition.
3.2.3 Test procedure
Listeners were tested individually in a sound-attenuating room,
using computer-controlled sentence presentation. Sentences were
presented binaurally via AKG240 DF headphones, and listeners responded
by writing down the sentence heard on a response sheet. Each
listener heard 25 SUS sentences in the natural condition and 25
in the enhanced condition. Sentence order within a block was
randomized, and which half of the sentence list a block was drawn
from, and whether a subject heard the enhanced or natural condition
first were counterbalanced across subjects.
3.2.4 Results
Sentences were scored in terms of the number of key-words correctly
transcribed. Intelligibility scores were then obtained by calculating
the percentage of key-words correctly transcribed in each 25-sentence
block (total of 100 key-words). Figure 7 shows the intelligibility
scores for all conditions.
At 5 dB SNR, the effect of enhancement was significant [F(1,8)=6.08, p=0.039]. The order in which conditions were presented, and the sentence blocks used did not significantly affect test scores. At 0 dB SNR, the enhanced condition did not produce significantly higher scores than the natural condition. Results obtained for the VCV tests replicated those obtained above. At 0 dB SNR, mean intelligibility scores showed a significant increase from 76% to 83% (paired-difference t-test p<0.001) as compared to an increase from 77% to 83% in VCV Experiment 2.
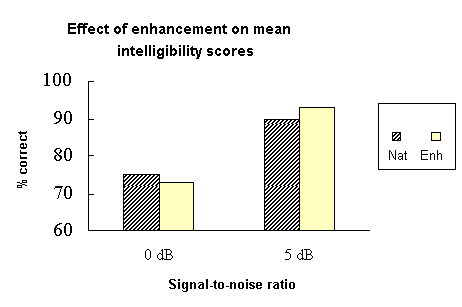
Little benefit of cue-enhancement on intelligibility was obtained for this sentence material. This experiment varied from previous one in three important respects: First, the type of material itself was radically different: the sentence-length material imposed a greater cognitive load on the listeners, especially as the sentences used were semantically-unpredictable. Second, a wider range of consonant classes with a greater variety of vocalic contexts were manipulated compared to previous experiments. Third, a different set of subjects was tested.
The replication of previously-obtained VCV results with a different listener group makes it unlikely that listener effects might be the cause for this difference. A detailed examination of sentence results did suggest that some of the enhancements made to affricates and approximants had led to an increased number of errors for words containing those sounds. In order to test whether this was the cause of the poorer results compared with those obtained for the VCV material, a further experiment was set up using the same SUS material, but with manipulations made only to plosives, fricatives and nasals, as in the VCV experiment.
3.3 Sentence Experiment 2
3.3.1 Method
Further adjustments were made to the enhancement techniques used
in sentence experiment 1. First, bursts were no longer filtered
as it was found that the filter-bandwidths could not be reliably
set due to the greater variability in burst center frequency in
continuous speech. The degree of amplification of the burst and
aspiration was also changed relative to sentence experiment 1.
Second, a change was made in the way in which the initial and
final vocalic cycles were amplified to avoid discontinuities in
the speech signal; vocalic cycles were amplified by between 4
and 2 dB; amplification was gradually altered with the cycles
nearest the occlusion being given the greatest amplification.
After being manipulated, stimuli were combined with speech-shaped
noise at 0 dB SNR.
| Class | Enhancement |
| Plosives | burst: +12dB; aspiration: +6dB; transitions+ 4-2 dB |
| Fricatives | friction: +6dB; transitions+ 4-2 dB |
| Affricates | not manipulated |
| Approximants | not manipulated |
| Nasals | nasality: +6dB; transitions+4-2 dB |
Table 3: Manipulations applied in Sentence Experiment 2.
b. Subjects
12 listeners were tested. All were aged between 20 and 30 with
pure tone thresholds below 20 dB HL.
c. Test procedure
As in Sentence Experiment 1.
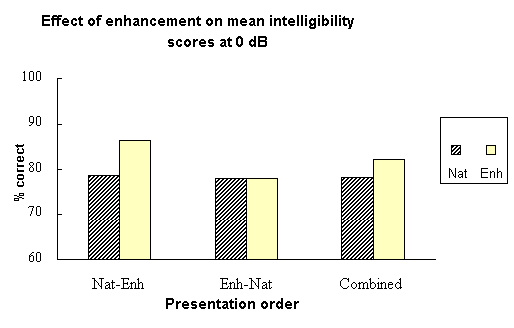
Mean scores are presented in Figure 8. The effect of enhancement was significant [F(1,8)=19.66, p=0.002]. The effect of order of presentation was not significant but there was significant interaction between order of presentation and enhancement [F(1,1)=21.45; p=0.002]: listeners who heard the enhanced sentences second showed a greater increase in intelligibility scores, but this effect did not apply when the presentation order was reversed. Learning effects with SUS material have also been reported in other studies (e.g. Grice and Hazan, 1989).
3.4 Sentence material discussion
The extension of enhancement techniques from highly-controlled
VCV material to sentence-level material did lead to a need for
refinements of the enhancement strategies. This was due to the
fact that consonants appeared in a much wider variety of vocalic
contexts and were also inherently more variable in their spectral
and temporal characteristics; as a result, the types and levels
of enhancements which were appropriate in the VCV experiments
sometimes led to abrupt changes in amplitude and other discontinuities
in the sentence material which had a deleterious effect on intelligibility.
Results obtained in Experiment 2, however, showed that more careful
adjustments made to the degree of amplification of certain constriction/occlusion
and transition portions did lead to significant increases in sentence
intelligibility as a result of cue-enhancement.
4. Conclusion
The work reported here has shown the benefit of speech pattern
enhancements in improving perception by normally-hearing listeners
in poor listening conditions. Despite the relatively gross manipulations
made to the stimuli in this study, a significant improvement in
intelligibility was achieved both for VCV and sentence material.
These enhancement techniques are currently being implemented within
a diphone-based text-to-speech system to allow testing of the
enhancement technique on the unlimited range of utterances that
can be generated in this way.
5. Acknowledgements
This work was funded by an EPSRC project grant (GR/J10426).
6. References
Benoit, C., Grice, M. and Hazan, V. (1996) The SUS test: a method
for the assessment of text-to-speech synthesis intelligibility
using Semantically Unpredictable Sentences, Speech Communication
18: in press.
Cheng, Y.M., O'Shaughnessy, D. & Kabal, P. (1995) Speech enhancement using a statistically derived filter mapping. Proceedings of International Conference of Spoken Language Processing, Banff, October 1992, vol.1, 515-518.
Glasberg, B.R. and Moore, B.C.J. (1990) Derivation of auditory filter shapes from notched-noise data. Hearing Research, 47, 103-138.
Gordon-Salant, S. (1986) Recognition of natural and time/intensity altered CVs by young and elderly subjects with normal hearing. Journal of the Acoustical Society of America, 80, 1599-1607.
Jamieson, D.G. (1995) Techniques for training difficult non-native speech contrasts. Proceedings of the XIIIth International Congress of Phonetic Sciences, 4, 100-104.
Nagarajan, S.S., Wang, X., Merzenich, M.M., Schreiner, C.E., Jenkins, W.M., Johnston, P.A., Miller, S.L., Byma, G. & Tallal, P. (1995) Speech modification algorithms for training language-learning impaired children. Proceedings of Society of Neuroscience Conference, 1995.
Niederjohn, R.J. & Grotelueschen, J.H. (1976) The enhancement of speech intelligibility in high noise levels by high-pass filtering followed by rapid amplitude compression, IEEE Trans. ASSP-24, p277.
Stevens, K.N. (1985) Evidence for the role of acoustic boundaries in the perception of speech sounds. In V. Fromkin (ed) Phonetic Linguistics: Essays in the honor of Peter Ladefoged. Academic Press, Orlando.
Tallal, P., Miller, S.L., Bedi, G., Byma, G., Wang, X., Nagarajan, S., Schreiner, C., Jenkins, W., Merzenich, M. (1996) Language comprehension in language-learning impaired children improved with acoustically modified speech. Science, 271, 81-84.
© 1996 Valerie Hazan and Andrew Simpson
 Back to SHL 9 Contents
Back to SHL 9 Contents
 Back to Phonetics and Linguistics Home Page
Back to Phonetics and Linguistics Home Page