
Introduction
The differences between the speech of an adult directed towards
a child and the same adult's speech directed towards another adult
have been investigated from many points of view - lexical, syntactic,
phonological and phonetic to name a few. This paper presents
the results of a study of some prosodic aspects of child-directed
speech (CDS) in a language which hitherto has not been investigated,
namely Cantonese.
The initial impetus for studies into CDS occurred in the 1960's
as a reaction to innatist theories of language acquisition. Most
of the work done in these early studies concentrated on English.
The reader is referred to an earlier paper by Ogle and Maidment
(1993) which includes a brief review of this literature and provides
a summary of the main findings on CDS prosody. Languages other
than English have also been the subject of study. Arabic and
Spanish were investigated by Ferguson (1964), Latvian by Ru±e
DraviÃa (1977),
Marathi by Kelkar (1964) and German by Fernald and Simon (1984).
A cross-linguistic study of CDS prosody including French, German,
Italian, Japanese, British English and American English may be
found in Fernald et al (1989). These and other studies broadly
confirmed the results of the English studies. The salient characteristics
of the prosody of CDS in these languages are: (a) an increase
in mean fundamental frequency and (b) an expansion of the range
of fundamental frequency which was effected by an increase in
the upper limit of the range rather than a decrease in the lower
limit.
That these tendencies are not perfectly universal is demonstrated
by the results of the study of Quiche by Pye and Ratner (1984)
which show that for this language mothers tend to lower mean fundamental
frequency when speaking to their offspring. The study by Fernald
et al (1989) showed that Japanese women tend not to expand their
frequency range when speaking to their children. Even within
one language it is clear that speakers vary considerably as to
the extent of the upward shift of mean fundamental frequency.
Shute and Wheldall (1989) report that some of their British English
mothers showed little or no increase in mean or mode fundamental
frequency for CDS while others showed marked increases.
The present study uses essentially the same technique and design
as those employed by Ogle and Maidment (1993). This paper reported
on fundamental frequency statistics for a small group of English-speaking
mothers under two conditions: (1) spontaneous speech to another
adult (henceforth the AA condition) and (2) spontaneous speech
to a child (henceforth AC). The technique used to record fundamental
frequency was electrolaryngography. The laryngograph is a non-invasive
device which monitors vocal fold vibration by electrodes placed
externally on the subject's neck at the level of the thyroid cartilage.
The high frequency current which is passed through the larynx
allows the measurement of the time-varying impedance of the neck
caused by the vibration of the vocal folds. The resulting signal,
known as Lx, can be recorded using a normal tape-recorder and
processed further to derive an estimate of the duration of each
glottal cycle (Tx) and instantaneous fundamental frequency (Fx).
For further details of the operation of the laryngograph the
reader is referred to Abberton and Fourcin (1984) and Abberton,
Fourcin and Howard (1989).
One of the great advantages of laryngographic analysis is that
it allows the rapid collection and analysis of a large number
of data points. Whereas earlier studies were limited by their
labour-intensive methods of analysis to basing statistical measures
on quite small samples, Ogle and Maidment analysed samples of
4000-5000 points per speaker. The present study was able to use
samples of approximately 8000 points.
In this paper results of the same kind as those presented for English by Ogle and Maidment are reported for Cantonese, namely mean fundamental frequency and range of fundamental frequency variation. The results obtained for the AA condition are compared with those for the AC condition. In addition, two further aspects of the prosody of Cantonese are investigated. These are (a): the difference in speech rate for the AA and AC conditions and (b) the differing realisation of lexical tone in the two conditions.
The first of these aspects has been investigated in the literature both qualitatively and quantitatively. Grewel (1959) characterised speech to the young child as slower in tempo with prolonged pauses between words, word groups and particularly between sentences. Sachs et al (1976) and Broen (1972) both report slower speech for CDS in terms of number of words per minute. Philips (1970) found that mothers took longer when reading particular sentences from a story to children than they did when reading the same sentences to another adult. As far as is known, there have been no investigations of the second aspect, lexical tone realisation.
Cantonese
Cantonese is a Yue language of Southern China and is spoken in
Hong Kong, Guangzhou, Macau and in many overseas Chinese communities
in Malaysia, Indonesia, USA and Britain. Like many of the languages
of China, Cantonese is characterised by a simple syllable structure
and by lexical tone. Lexical items which are segmentally identical
may be distinguished by the use of differing pitch patterns.
Cantonese has a particularly rich tone system. Most analysts
agree that 6 distinct tones should be recognised, although the
numbering and nomenclature of the tones vary somewhat from author
to author:
Tone 1: high level
Tone 2: high rising
Tone 3: mid level
Tone 4: low falling (or extra low level)
Tone 5: low rising
Tone 6: low level.
The single syllable [fan] serves as an example of the lexical distinctiveness of these tonal patterns:
|
[fan1] to divide
[fan2] powder [fan3] to sleep |
[fan4] tomb
[fan5] energetic [fan6] status |
Further information on the structure of Cantonese may be found
in Ramsey (1987) and Norman (1988).
Subjects and Recordings
Recordings were made of 7 Cantonese-speaking mothers, living in
England. All the subjects were the carers of children aged between
1;0 and 1;8 at the time of the recording. The details are set
out in Table 1 below.
Table 1: Subject Details
The age of the children was chosen to be between 1 and 2 years
as it was felt that features typical of CDS might have begun
to disappear with older children. All of the speakers had lived
in England for at least 3 years.
All recordings were made in the subjects' own homes so that they
and their children would feel at ease. A portable laryngograph
and Uher portable two-channel stereo tape-recorder were used.
The speech signal was recorded using a clip-on microphone.
Two recordings were made, each of which lasted approximately 15
minutes:
1. The AA condition: the subject was recorded in conversation
with the first-named author. The conversation concerned the subject's
background, children and life in England.
2. The AC condition: the subject was recorded interacting with
the child during story-telling. Three picture books were provided
as a stimulus for the interaction. In some cases the interaction
involved play with toys too.
Fundamental Frequency Statistics
Analysis and Results
A suite of programs, PCLX, running on a PC was used to analyse the Lx recordings. The Lx representation of larynx activity is first converted to a file of period measurements, Tx. The software provides facilities for analysing the Tx file in various ways. The most important analyses for the present purpose are those which result in a probability-density function of fundamental-frequency. The particular analysis used for this study gives a doublet distribution. Time-adjacent pairs of Fx values, derived from Tx, are examined to discover if they fall within the same subrange (frequency bin) of the range of fundamental frequency between 30 Hz and 1 kHz. There are 128 bins in this range and the centre frequency of the nth bin is given by:
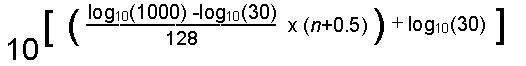
The doublet distribution is used because it removes irregularity
and rogue data points due to gross movements of the larynx and
only takes into account portions of Fx which are constant or which
display smooth and relatively slow change.
The PCLX software also provides statistics of the probability-density
function of Fx. The two measures used in this study are the arithmetic
mean and the 80% range. This latter is defined as the range between
a lower limit which is centre frequency of the bin which has 90%
of the samples above it and an upper limit which is the centre
frequency of the bin which has 10% of the samples above it.
Table 2 below presents a comparison of the mean fundamental frequency
in Hz of the 7 speakers under the two speaking conditions together
with the percentage change from one condition to the other which
is defined as ((AC-AA) * 100) / AA.
Subject | AA |
AC | % change |
A |
244.0 | 296.0 | 21.3 |
| B | 213.0 | 225.0 | 5.6 |
| C | 213.0 | 265.0 | 24.4 |
| D | 225.0 | 237.0 | 5.3 |
| E | 191.0 | 219.0 | 14.7 |
| F | 191.0 | 196.0 | 2.6 |
| G | 213.0 | 219.0 | 2.8 |
| Mean | 11 | ||
| Standard Deviation | 8.4 | ||
Table 2: Mean fundamental frequency (Hz)
It is clear from Table 2 that all subjects used a higher mean
fundamental frequency in CDS. The average increase was 11%.
However, the variation between subjects was quite large. A Student's
t test applied to the AA and AC figures yielded a significant
result ( t = 3.06, p < 0.05).
It is of interest to compare the mean increase observed for these
Cantonese speakers with the figure of 18.8% obtained by Ogle and
Maidment for the English speakers in their study. The tendency
for higher mean fundamental frequency is evidently considerably
stronger amongst Ogle and Maidment's subjects than it is for the
speakers of the present study.
Table 3 shows a comparison of the 80% fundamental frequency range
in Hz for the 8 subjects in the AA and AC conditions. Again the
percentage change from one condition to the other is presented.
Subject | AA |
AC | % change |
A |
120.0 |
162.0 |
35.0 |
| B | 94.0 | 113.0 | 20.2 |
| C | 108.0 | 129.0 | 19.4 |
| D | 79.0 | 97.0 | 22.8 |
| E | 85.0 | 108.0 | 27.1 |
| F | 78.0 | 92.0 | 18.0 |
| G | 86.0 | 94.0 | 9.3 |
| Mean | 21.7 | ||
| Standard Deviation | 7.4 | ||
Table 3: 80% fundamental frequency range
As Table 3 shows, there can be no doubt that these speakers consistently
used a wider range of fundamental frequency variation in CDS.
Apart from speakers A and H, the size of the increase is quite
consistent. An average increase in range of 27.1 percent was
observed. A Student's t test on the data in Table 3 showed
that the difference between the two conditions was highly significant
(t = 5.17, p < 0.01).
Compared to the figure of 89.3% for Ogle and Maidment's English
speakers, the average expansion of the 80% range is quite small
for the these Cantonese speakers.
Table 4 presents a comparison of the Hz shifts in the upper and
lower limits of the 80% fundamental frequency range for the AA
and AC conditions. Once again the percentage change in frequency
is given.
From the three lefthand columns in Table 4 it is clear that the
expansion of the 80% range in CDS receives no consistent significant
contribution from a downward shift in the lower limit of the range.
In fact, all the subjects showed either no shift at all or an
upward shift for the lower limit.
Subject | AA |
AC | %change | AA |
AC | %change |
A |
201.0 |
237.0 |
17.9 |
321.0 |
399.0 |
24.3 |
| B | 186.0 | 191.0 | 2.7 | 280.0 | 304.0 | 8.6 |
| C | 180.0 | 219.0 | 21.7 | 288.0 | 348.0 | 20.8 |
| D | 201.0 | 207.0 | 3.0 | 280.0 | 304.0 | 8.6 |
| E | 166.0 | 180.0 | 8.4 | 251.0 | 288.0 | 14.7 |
| F | 166.0 | 166.0 | 0.0 | 244.0 | 258.0 | 5.7 |
| G | 186.0 | 186.0 | 0.0 | 272.0 | 280.0 | 2.9 |
| Mean | 7.7 | 12.2 | ||||
| Standard Deviation | 8.2 | 7.4 | ||||
Table 4: Comparison of upper and lower
80% range limits
The upper limit of the 80% range is shifted upward in CDS by all
speakers. The mean figure for this shift is 12.1%, but there
is considerable inter-speaker variation. The shift in the upper
limit is shown by a t-test to be statistically significant
(t = 3.64, p < 0.05).
These results are, in the main, consistent with those obtained by Ogle and Maidment, except that the shift in the upper limit is greater in most cases, as would be expected because of the very much greater expansion of the range displayed by the English speakers.
Speech Rate
There are many ways in which one could estimate the rate of speech.
For the purposes of this paper an estimate of the number of syllables
uttered per minute was chosen, mainly because it is a relatively
simple measure to calculate for the fairly large amounts of speech
involved in the recordings. Such a measure of course ignores
possible variations of speech tempo and other aspects of potential
interest such as pause length, occurrence of disfluencies and
turn-taking behaviour. Nevertheless, any overall tendency of
speech rate in CDS to differ from adult-directed speech rate should
be captured by this measure.
The number of syllables in each sample was counted by repeated
listening to the speech recording and this figure was divided
by the total time for the recording. Table 5 shows the results
for the two conditions and presents the percentage change between
them.
Subject | AA |
AC | % change |
A |
203 |
111 |
-45.3 |
| B | 189 | 110 | -41.8 |
| C | 184 | 99 | 46.2 |
| D | 174 | 101 | 42.0 |
| E | 231 | 168 | 27.3 |
| F | 198 | 156 | 21.2 |
| G | 221 | 125 | 43.4 |
| Mean | 38.1 | ||
| Standard Deviation | 9.1 | ||
Table 5: Speech rate in syllables per
minute
All speakers display a considerably slower rate for CDS. The difference between the two conditions is highly significant (t = -10.76, p < 0.01)
Tone Realisation
In order to assess the possible influences of CDS on the realisation
of the 6 lexical tone patterns of Cantonese, two simplifying assumptions
were made. The first of these is that the shape of all the tonal
patterns can be adequately represented by their beginning and
ending frequencies alone. The second assumption is that duration
and intensity may be ignored in distinguishing one tone from another.
Furthermore, in order to compare the realisation of tones across
speakers, it is necessary to perform some normalising transformation
of the frequencies in Hz. This transformation may be expressed
as.
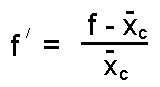
 is the mean fundamental frequency for the speaker
in a particular condition.
is the mean fundamental frequency for the speaker
in a particular condition.
The start and end frequencies of the tones were estimated for
each speaker under the two conditions by averaging over five tokens
of each of the six tones. The boundaries of the relevant syllables
were identified from a spectrographic display with playback facility.
The system used in this part of the study did not allow simultaneous
display of speech waveform and fundamental frequency. Therefore,
the relevant frequencies were calculated spectrographically. Because
of the possible interference of environmental noise on the speech
recordings, the frequencies were estimated by measuring the tenth
harmonic of a time-aligned narrow-band spectrogram of the Lx signal.
Table 6 shows the start and end points of the six tones by speaker
in the two conditions.
| AAS | AAE | ACS | ACE | AAS | AAE | ACS | ACE | ||
| A | 0.16 | 0.03 | 0.22 | 0.04 | 0.01 | 0.23 | 0.05 | 0.22 | |
| B | 0.30 | 0.12 | 0.37 | 0.15 | -0.11 | 0.21 | 0.04 | 0.20 | |
| C | 0.28 | 0.18 | 0.26 | 0.18 | -0.09 | 0.22 | 0.01 | 0.25 | |
| D | 0.25 | 0.14 | 0.28 | 0.09 | -0.10 | 0.27 | 0.06 | 0.21 | |
| E | 0.32 | 0.17 | 0.25 | 0.14 | -0.04 | 0.17 | 0.08 | 0.21 | |
| F | 0.22 | 0.07 | 0.26 | 0.02 | -0.10 | 0.20 | 0.07 | 0.15 | |
| G | 0.25 | 0.09 | 0.31 | 0.06 | -0.14 | 0.27 | 0.01 | 0.24 | |
|
Mean |
0.25 |
0.11 | 0.29 | 0.10 | -0.08 | -0.22 | -0.04 | -0.21 | |
| A | 0.16 | 0.04 | 0.07 | 0.20 | 0.10 | 0.01 | 0.10 | 0.07 | |
| B | 0.06 | 0.17 | 0.02 | 0.27 | 0.04 | 0.15 | 0.03 | 0.17 | |
| C | 0.08 | 0.14 | 0.03 | 0.18 | 0.05 | 0.08 | 0.00 | 0.12 | |
| D | 0.08 | 0.04 | 0.06 | 0.17 | 0.11 | 0.04 | 0.02 | 0.11 | |
| E | 0.02 | 0.27 | 0.04 | 0.21 | 0.04 | 0.24 | 0.06 | 0.17 | |
| F | 0.07 | 0.13 | 0.04 | 0.21 | 0.05 | 0.04 | 0.01 | 0.19 | |
| G | 0.03 | 0.15 | 0.07 | 0.36 | 0.07 | 0.02 | 0.10 | 0.21 | |
Mean | -0.07 | 0.13 | -0.02 | 0.23 | -0.05 | 0.08 | 0.01 | 0.15 | |
| A | 0.03 | 0.11 | 0.06 | 0.08 | 0.02 | 0.14 | 0.08 | 0.22 | |
| B | 0.08 | 0.03 | 0.10 | 0.05 | 0.03 | 0.08 | 0.07 | 0.13 | |
| C | 0.03 | 0.04 | 0.13 | 0.04 | 0.01 | 0.08 | 0.02 | 0.22 | |
| D | 0.03 | 0.15 | 0.11 | 0.04 | 0.01 | 0.17 | 0.01 | 0.13 | |
| E | 0.24 | 0.02 | 0.10 | 0.06 | 0.09 | 0.04 | 0.09 | 0.14 | |
| F | 0.07 | 0.03 | 0.14 | 0.03 | 0.03 | 0.10 | 0.06 | 0.11 | |
| G | 0.06 | 0.10 | 0.17 | 0.01 | 0.02 | 0.14 | 0.11 | 0.16 | |
Mean | 0.07 | -0.07 | 0.12 | -0.03 | 0.00 | -0.11 | 0.04 | -0.16 | |
Table 6: Normalised frequency values
for the six tones by speaker
(AAS/AAE = Adult-Adult start/end, ACS/ACE
= Adult-Child start/end)
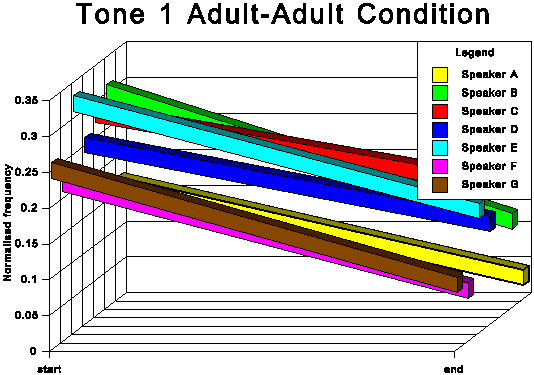
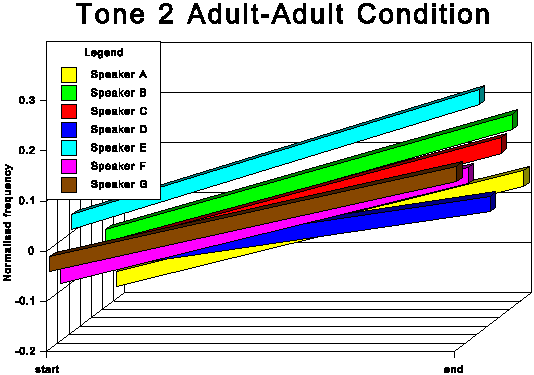
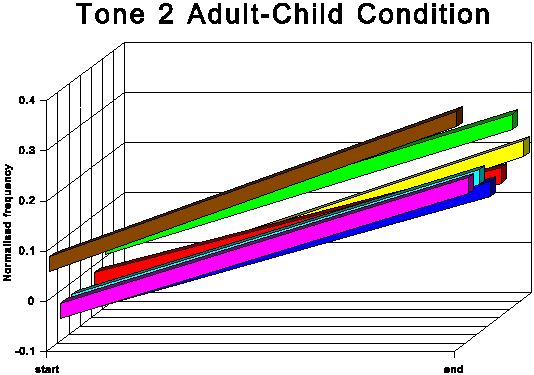
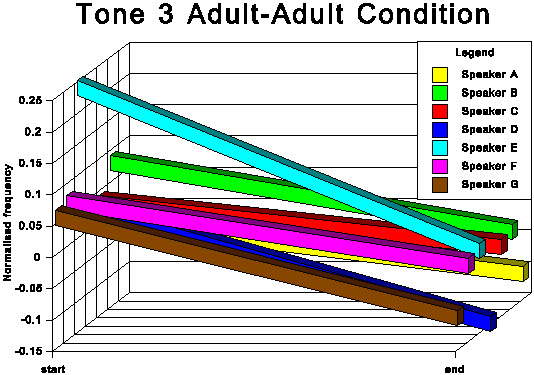
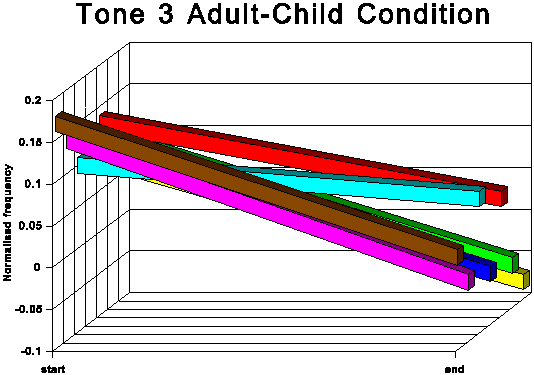
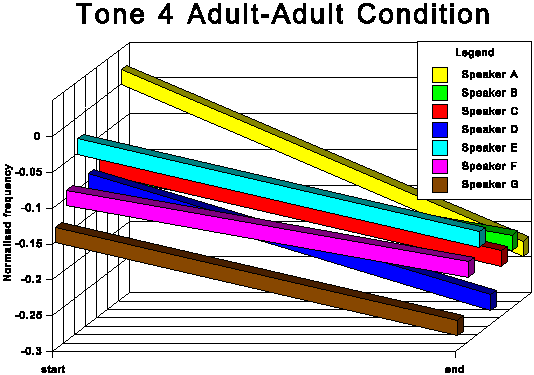
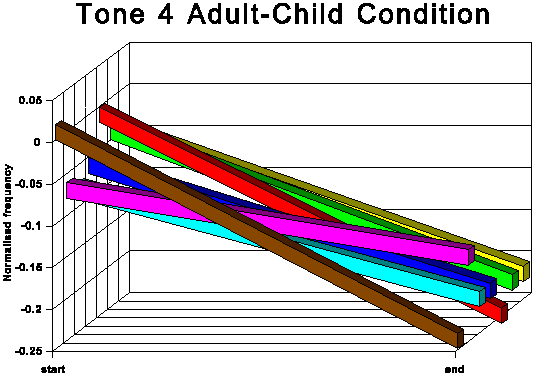
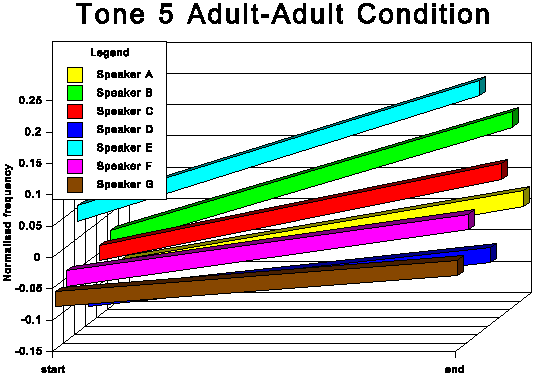
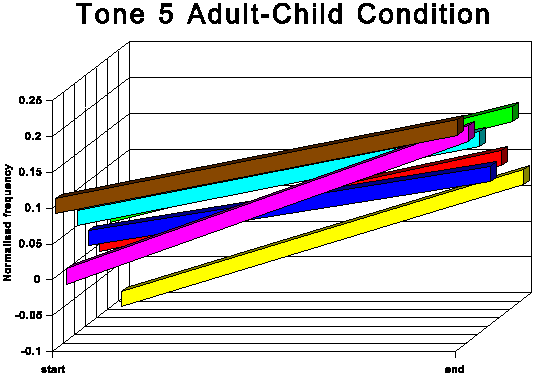
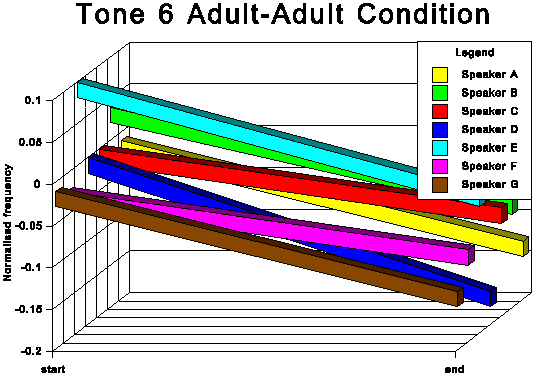
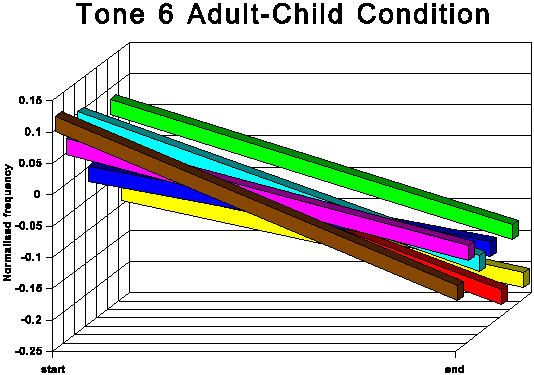
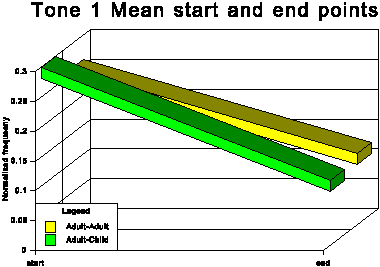
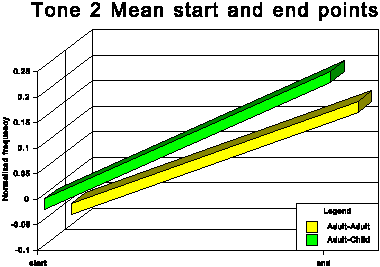
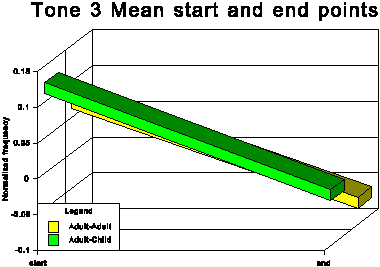
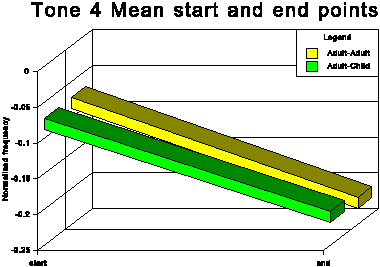
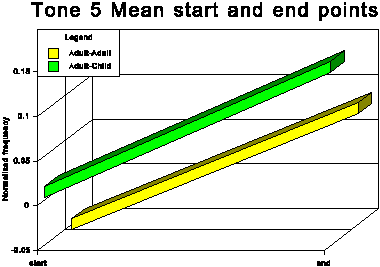
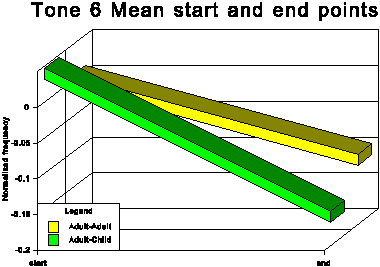
The above data is presented graphically in the appendix to this paper.
The following discussion is based upon Table 6.
The first point of interest is that three tones traditionally
described as level (tones 1, 3 and 6) in fact show quite marked
falling movements in both speech conditions.
It is noticeable that for all tones except tone 6 (low level),
the AC start and end points are higher in normalised frequency
than the corresponding AA start and end points. For tone 6, the
start point is slightly higher for the AC condition, but the end
point for AC is somewhat lower than for AA. This indicates that
the speakers not only raise the overall fundamental frequency
of their speech in CDS in absolute terms, but also adjust upwards
the frequency of most individual tonal realisations within their
fundamental frequency range. This adjustment is most marked for
the two rising tones, tones 2 and 5.
The fact that in AC tone 1 and tone 3 (high level and mid level
respectively) are adjusted upwards, considerably in the case of
tone 3 and slightly in the case of tone 1, while there is no corresponding
overall upward adjustment for tone 6 (low level), means that the
space occupied by the subsystem of level tones is expanded in
CDS and the distinctions between these three level tones are exaggerated.
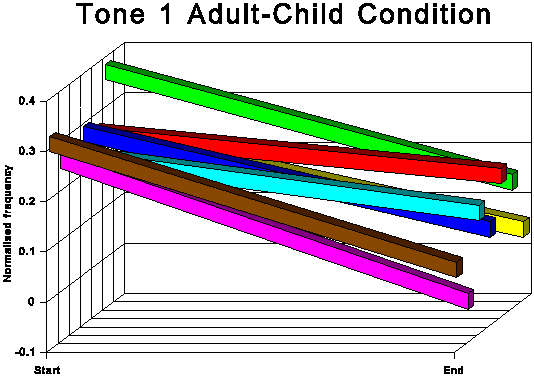
This expansion of the level tone subsystem is evident from the
averaged patterns in Figures 7 and 8 and is even clearer in some
of the results for the individual speakers. Compare, for instance,
the AA and AC conditions for subjects C and D.
Another readily identifiable difference between the two speech
conditions concerns tone 2 (high rising). For all speakers this
tone has the highest end point of the six tones in the AC. This
is not always true for the AA condition. Moreover, there is a
tendency for at least some of the speakers to increase the difference
between the two rising tones (tones 2 and 5) in the AC condition.
See especially subjects A, B and C.
Despite the above differences between the realisation of tonal
patterns, it is remarkable that the overall relationships in the
system (what Cheung, 1986 calls cardinal relations) are maintained.
The following hold for both the AA and AC conditions:
(1) The relationship between the start frequency of the so-called level tones is Tone 1 > Tone 3 > Tone 6.
(2) The end frequency of Tone 4 is lower than that for Tone 6.
(3) The end frequency for Tone 2 is higher than that for Tone 5.
(4) Tone 2 has a steeper gradient than Tone 5.
(5) Tones 1 3 4 and 6 show a falling contour.
(6) Tones 2 and 5 show a rising contour.
The question arises as to whether the differences between the
AA and AC realisations of tones show signs of lessening with the
increasing age of the child. In order to test this possibility,
the correlation co-efficient was computed between the age of the
child in months and the absolute difference between the normalised
frequency of the mid point of each AC tone and its corresponding
AA tone. If the differences were age-sensitive, one would have
expected a significant negative correlation. In fact, none of
the correlation co-efficients was statistically significant.
Therefore, one must conclude that over the age range investigated
features of CDS affecting the realisation of tones are fairly
stable and do not begin to abate.
In summary, it appears that the subjects in this experiment maintain the overall relationships of the adult tonal system in their speech to children, but have a tendency to maximise the difference between the realisations of the individual tones.
Discussion
The results reported in this paper for overall fundamental frequency
statistics in the AA and AC speech conditions largely agree with
those reported in earlier work. There is a statistically significant
raising of mean fundamental frequency in CDS, though the extent
of this for the present Cantonese speakers is not as great as
has been reported in other languages. Similarly, the range of
fundamental frequency variation is increased in CDS for the present
speakers, but the increase is by no means as great as has been
reported for English. One possible explanation is that, Cantonese
being a lexical tone language, there is less freedom for the speaker
to manipulate fundamental frequency than there is in intonation
languages such as English. The functional distinctiveness of
fundamental frequency patterning operates over a much shorter
time-scale in a lexical tone language and the points in an utterance
where the speaker is constrained by semantic considerations to
perform particular movements of fundamental frequency occur much
more frequently.
Nevertheless, the overall raising of fundamental frequency and
the expansion of the range of variation does take place in Cantonese.
There have been explanations in the literature of these CDS tendencies
as an attempt on the part of the adult speaker to minimise the
child's normalisation task. By adjusting mean fundamental frequency
upwards, the difference between what the child is capable of producing
and what the child hears is diminished. Other explanations concern
the auditory sensitivity of young children. Under this hypothesis
the raising of mean fundamental frequency is an attempt to match
the frequency at which children show the best response. However,
there is evidence (see for instance Kearsley, 1973) that young
children show stronger orientating responses to tones at 500 Hz
than to tones at 250 Hz. Very few adult speakers are capable
of maintaining a mean fundamental frequency of 500 Hz. This hypothesis
would also carry the implication that children of the relevant
age find it more difficult to understand men than to understand
women. There is no independent evidence to support such a conclusion.
There is of course the possibility that children's sensitivity
to speech-like sounds differs from that in evidence when they
are presented with tone stimuli.
Yet another hypothesis put forward to explain CDS fundamental frequency features is that it is an attention attracting device. Werker and McLeod (1989) showed that children aged 0;4-0;5 and 0;7-0;9 spent longer watching a television monitor that presented actors using CDS than when the same actors used adult-directed speech.
Masataka (1992) found that the mean and range of fundamental frequency
of Japanese mothers' CDS tended to diverge increasingly from those
for adult-directed speech as a function of the number of utterances
produced before a response form the infant.
The analysis carried out on the rate of speech of the present
subjects in the two speech conditions clearly shows that they
employ much slower speech when interacting with the child. This
is in accord with results presented in the literature for other
languages. There are a number of benefits a young child might
obtain from a slower speech rate. One is a gain in processing
time. Another is that slower speech is less likely to contain
as many occurrences of elision, assimilation and other contextual
modifications which are rife in rapid conversational speech between
adults. Thus, the child is likely to hear speech which approximates
more to an idealized input which avoids variability in the realisation
of individual linguistic forms.
The tonal system of Cantonese is a complex one, yet there is evidence
that tonal distinctions in this language, as in other lexical
tone languages, are acquired before segmental contrasts. Li and
Thompson (1977) report this for Modern Standard Chinese (Mandarin).
Tse (1977) concludes the same for Cantonese on the basis of a
longitudinal study of one child. Another of Tse's findings that
is relevant here is that the time span for the acquisition of
the production of all 6 Cantonese tones covered a period of only
8 months from 1;2 to 1;9. The majority of the children in the
present study fell within this age range. Tse also reports that
the perceptual discrimination of lexical tone contrasts began
as early as 0;10.
The main finding of the present study regarding Cantonese CDS tone realisation is that there is evidence that adults attempt to maximise the difference between some members of the tonal system. Of course, the overall expansion of the fundamental frequency range employed in CDS must have this effect in absolute terms. However, the fact that differences in tone realisation remain when the fundamental frequency values of the start and end points of the tones are normalised to the speaker's mean frequency. This suggests that the speaker does not rely on a global expansion of the range alone, but locates some members of the system differently within the range in the two speech conditions. This is especially noticeable with the three tones traditionally described as level, but there is also evidence of attempts to increase the distinguishing features of the two rising tones
References
Abberton, E. R. M. & Fourcin A. J. (1984) Electrolaryngography.
In C. Code & M. Ball, Eds, Experimental Clinical Phonetics,
pp 62-78. London: Croom Helm.
Abberton, E. R. M., Fourcin A. J. & Howard D. M. (1989) Laryngographic
assessment of normal voice: A Tutorial. Clinical Linguistics
and Phonetics 3, 281-296.
Broen, P. A. (1972) The verbal environment of the language learning
child. Monograph of the American Speech and Hearing Association
17
Cheung, K. (1986) The phonology of present day Cantonese. Doctoral
dissertation. University of London.
Ferguson, C. A. (1964) Baby talk in six languages. American Anthropologist 66, 103-114
Fernald, A. & Simon, T. (1984) Expanded intonation contours
in mothers' speech to newborns. Developmental Psychology
201, 104-113.
Fernald, A., Taeschner, T., Dunn, J., Papousek, M., Boysson-Bardies,
B., & Fukui, I (1989) A cross-language study of prosodic
modifications in mothers' and fathers' speech to preverbal infants.
Journal of Child Language 16, 477-501
Grewel, F. (1959) How do children acquire the use of language?
Phonetica 3, 193-202
Kearsley, R. (1973) The newborn's response to auditory stimulation:
a demonstration of orienting and defensive behaviour. Child
Development 44, 582-590
Kelkar, A. (1964) Marathi baby talk. Word 20, 40-54
Li, C. N. & Thompson S. A. (1977) The acquisition of tone
in Mandarin-speaking children. Journal of Child Language
4, 185-200.
Masataka, N. (1992) Pitch characteristics of Japanese maternal
speech to infants. Journal of Child Language 19, 213-223.
Norman, J. (1988) Chinese. Cambridge: Cambridge University
Press.
Ogle, S. & Maidment, J. A. (1993) Laryngographic analysis
of child-directed speech. European Journal of Disorders of
Communication 28, 289-297.
Philips, J. (1970) Formal characteristics of speech which mothers
address to their young children. Doctoral dissertation, John
Hopkins University.
Pye, N. B. & Ratner, C. (1984) Higher pitch in B. T. is not
universal: acoustic evidence from Quiche Mayan. Journal of
Child Language 11, 515-522
Ramsey, S. R. (1987) The Languages of China. Princeton:
Princeton University Press.
Ru±e-DraviÃa,
V. (1977) Modifications of speech addressed to young children
in Latvian. In C. E. Snow and C. A. Ferguson, Eds, Talking
to Children: Language Input and Acquisition, 237-253. Cambridge:
Cambridge University Press.
Sachs, J., Brown, R. & Salerno, R. A. (1976) Adults' speech
to children. In W. von Raffler-Engel and Y. Lebrun, Eds, Baby
Talk and Infant Speech, 240-245. Lisse, Netherlands: Swets
& Zeitlinger.
Shute, B. & Wheldall, K. (1989) Pitch alterations in British
motherese: some preliminary acoustic data. Journal of Child
Language 16, 503-512.
Tse, J. K. P. (1977) Tone acquisition in Cantonese: a longitudinal
case study. Journal of Child Language 5, 191-204.
Werker, J. F. & McLeod, P. J. (1989) Infant preference for
both male and female infant-directed talk: a developmental study
of attentional and affective responsiveness. Canadian Journal
of Psychology 43, 230-246.
© 1996 Joanne Siu-Yiu Tang and John A. Maidment
 Back to SHL 9 Contents
Back to SHL 9 Contents
 Back to Phonetics and Linguistics Home Page
Back to Phonetics and Linguistics Home Page
