Department of Phonetics and Linguistics

First the functionality of the various modules is formally defined
and discussed. Next, a number of long-standing issues related
to variability with phonetic context are discussed from the perspective
of the framework. In this discussion a number of fresh insights
are gained into problems such as acoustic variability versus perceptual
constancy, acoustic constancy versus perceptual variability, the
segmentation issue and cue-trading relations. It is argued that
viewing the phonetic categorisation problem as multidimensional
pattern classification unifies these issues and may inspire a
reformulation of some research questions.
1. Introduction
The work presented in this paper is based on the viewpoint that
it is extremely useful to treat the issue of perception of consonants
and vowels as a pattern-recognition problem. A pattern recognition-based
framework is proposed which can serve as a starting point from
which research questions can be formulated and human classification
of speech sounds can be modelled and interpreted.
2. Background
Throughout the history of speech-perception research the issues
of segmentation and variability have consistently been put forward
as the most basic problems for theories of phonetic perception
(e.g. Cooper et al., 1952; Liberman et al., 1967; Pisoni and Sawusch,
1975; Lindblom, 1986; Sawusch, 1986; Klatt, 1989; Nygaard and
Pisoni, 1995). The segmentation issue can be summarised
as follows. When listening to speech, one has the impression of
receiving a series of discrete linguistic units (e.g. phonemes
or syllables). The acoustic signal, however, cannot be segmented
into discrete chunks corresponding to these linguistic units.
Instead, the acoustic consequences of the articulatory realisation
of a particular linguistic unit generally strongly overlap with
those of the neighbouring units. The variability issue
refers to the finding that there does not seem to exist a set
of acoustic properties that uniquely identifies any given linguistic
unit. Any such set will show considerable variability depending
on factors such as phonetic context, speaker identity, speaking
rate and transmission conditions.
As far as the factor of phonetic context is concerned (i.e. the
influence of surrounding linguistic units on the acoustic realisation
of a particular linguistic unit), the issues of segmentation and
invariance are intimately linked. Both can be considered to be
acoustical consequences of a phenomenon known as coarticulation.
Coarticulation can be defined as the temporal overlap of articulatory
movements associated with different linguistic units.
In the vast majority of theoretical as well as experimental studies addressing the issues of segmentation and variability in phonetic perception the concept of the cue or acoustic cue has played a central role. Although the precise interpretation of this concept is rather hazy in most of these studies, some definitions are available. Repp's definition seems to correspond with the generally accepted interpretation:
"A cue ... is a portion of the signal that can be isolated
visually, that can be manipulated independently in a speech synthesizer
constructed for that purpose, and that can be shown to have some
perceptual effect" (Repp, 1982).
In the history of phonetics, large numbers of acoustic cues for various phonetic distinctions have been found and their perceptual effects documented. It is generally assumed that in the process of classifying a speech sound, the listener extracts a certain number of acoustic cues from the speech signal and bases the labelling of the
speech sound on these cues. In the framework proposed here, the
cue concept will also play an important role. I will, however,
propose a slightly altered definition of the acoustic cue which
closely corresponds to the "feature" in pattern-recognition
theory.
In this paper it will be argued that, although the notion of a
cue is very useful and has indeed generated a large body of knowledge,
a number of aspects of this approach need to be better formalised
and integrated into a whole. In the light of a more formal framework
it will emerge that basic issues, as well as the interpretations
of certain experimental findings, need to be re-evaluated.
2.1 Purpose
In this paper I will propose a pattern recognition-based framework
for research on the classification behaviour of listeners in a
phonetic perception experiment. Within the framework I will try
to formalise the most important aspects of the cue-based account
of phonetic perception that underlies the major part of phonetic
research. This framework can serve as a starting point from which
research questions can be formulated and human classification
of speech sounds can be modelled and interpreted.
The framework is formulated within the general information-processing
approach and consists of various interconnected modules that process
and exchange information. Although the functions of the various
modules as well as relevant terminology will be defined as precisely
as possible, the framework will remain qualitative and as such
cannot deal with quantitative data without additional assumptions
and parameter estimations. This is the reason why I use the term
framework rather than model, reserving the latter term for instantiations
of the framework that can actually simulate or predict quantitative
data.
The framework is restricted in two basic ways, dealing only with:
Other problems of variability such as speaker identity, speaking
rate and transmission conditions will not be considered. Clearly,
these restrictions considerably reduce the complexity of the problem
at hand. It will be argued, however, that the framework can be
extended in a consistent way to incorporate at least some of the
additional sources of variability mentioned. Furthermore, the
framework is kept as simple as possible, while at the same time
being able to qualitatively account for several experimental
findings reported in the literature. In particular, it will be
argued that the removal of one or more of the information processing
modules or connections between these modules will cause the framework
to be inadequate in accounting for certain experimentally observed
phenomena.
It is emphasised that it is not the purpose of this paper to formulate
a novel speech perception theory that competes with existing ones
such as the motor theory (Liberman et al., 1967; Liberman and
Mattingly, 1985), the theory of acoustic invariance (Blumstein
and Stevens, 1981; Stevens and Blumstein, 1981) or the direct-realist
account of speech perception (Fowler, 1986). Instead, these theories
can all be formulated as particular instances of the proposed
framework, although strictly speaking the scope of the framework
is narrower than that of these theories.
The structure of the paper is as follows. In the next section
the general setup of the framework will be introduced. Next, in
section 3, the functionality of the individual modules in the
framework will be described. Section 4 is devoted exclusively
to a discussion of principles and aspects of the pattern-classification
module. In section 5, I will use the proposed framework to shed
fresh light on a number of experimental findings and theoretical
issues.
3. General structure of the framework
The proposed framework is intended as a comprehensive and formal
representation of the widely adopted cue-based approach to phonetic
perception. As indicated earlier, the framework specifically deals
with the classification behaviour of listeners in a phonetic perception
experiment, i.e., an experiment in which subjects are instructed
to classify speech sounds. As is the case for the subjects, the
input and output for the framework are speech waveforms and response
labels, respectively. Although, after an experiment is completed,
the waveforms and response labels are generally all you have as
experimenter, several distinct intermediate processing steps are
commonly assumed to take place in the subject (e.g. Massaro, 1987;
Ashby, 1992). Each of these processing steps transforms information
from one level of description to another. I assume that the following
four levels of description must be distinguished, both in the
subject as well as in the framework.
The terminology used above will be defined more precisely later.
Repp (1981) has already convincingly argued that these distinctions
are essential, but we will return to this issue later.
Figure 1 displays a graphical representation of the proposed framework. Note that the four levels of description are explicitly distinguished within the framework, as indicated on the left-hand side of Figure 1.
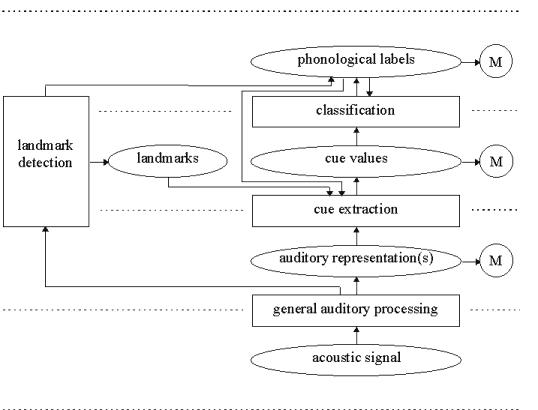
4. Description of modules
In this section the modules found in Figure 1 will be described,
introducing a number of definitions along the way.
4.1 General auditory processing
The input to this module is the acoustic signal (pressure wave),
the output is roughly equivalent to the representation found in
the auditory nerve. It is assumed that the general auditory processor
can be reasonably well modelled by converting the speech signal
into some form of time-frequency representation like the spectrogram.
It is noted, however, that such a model has the potentially significant
drawback that it does not emphasise transients the way the auditory
system does.
Definition: General auditory context
The general auditory context is defined as the information in
the auditory time-frequency representation(s) which is available
at a given point in time.
In accordance with Crowder and Morton (1969) we assume that the
most recent incoming general auditory information is stored in
some relatively unprocessed form in a "precategorical acoustic
storage" (PAS), where it is available for further processing.
Old information is assumed to be lost or to become progressively
"blurred" or noisy with the passage of time. Hence,
a time window can be associated with the general auditory context.
The length of this window is assumed to be in the order of several
hundreds of milliseconds. This corresponds to the "short
auditory store", which is one of the two precategorical storages
proposed by Cowan (1984).
The general auditory level is general in the sense that only peripheral
auditory processing takes place indiscriminately with regard to
the incoming signal. That is, it is assumed to be independent of higher-level processes. In later
modules of the framework, several specialised (non-general) processing
will take place, which is dependent on higher-level information.
4.2 Detection of landmarks
Definition: Landmark
A landmark is defined as a time instant in the speech signal which
functions as a reference point for one or several cue-extraction
mechanisms.
The input to this module is the general auditory context. The
output is twofold: (1) the landmarks, i.e. the time instants,
(2) a broad phonetic ("manner") classification of the
landmark.
A form of landmark detection has been implicitly assumed in many
cue-based phonetic studies. For example, if the listener is supposed
to use the frequency of F2 at voicing onset in place-of-articulation
perception, it is implicitly assumed that he or she knows where
in the signal the F2 should be sampled. Hence, the instant of
voicing onset has to be established first.
The concept of acoustic landmarks has been explicitly put forward
by Stevens and co-workers (e.g. Stevens and Blumstein, 1981; Stevens,
1985; Stevens, 1995) in the context of the "lexical access
from features" (LAFF) theory. In Stevens's approach an acoustic
landmark is generated by a significant articulatory event such
as establishing or releasing a (locally) maximum constriction
in the vocal tract, reaching a (locally) maximum opening of the
vocal tract, and onset or offset of voicing. Acoustically, landmarks
are generally characterised by a maximum or minimum of spectral
change. A computational model of an "abrupt-nonabrupt"
landmark detector has recently been implemented by Liu (1995).
In line with this work it is assumed here that the landmark detector
module comprises several individual detectors which essentially
continuously monitor the auditory representation(s) and trigger
on a threshold-like basis. There may, for instance, be a detector
for stop closure and release based on detection of a large enough
spectral discontinuity or a voice-onset detector based on some
form of periodicity detection.
4.3 Cue extraction
There are four types of input to this module: landmarks, the general
auditory context, the specific auditory context (previously determined
cue values) and phonological context (previously determined phonological
labels). The landmarks specify where acoustic cues are to be
measured, the phonological and specific auditory context specify
which cues are to be measured. Cues are always measured on the
general auditory context. Obviously, the output of the cue extractor
are cue values.
Definition: Cue extraction
Cue extraction is defined as a mapping of the general auditory
context onto a scalar variable.
The cue-extraction operation is in essence simply a measurement
operation. Examples of cue-extraction operations are the (perceptual)
measurement of the length of a stop release burst and of the frequency
of F2 at voicing onset.
Definition: Acoustic cue
An acoustic cue is defined as the output of a cue-extraction operation.
Typical examples of acoustic cues are the length of the stop release
burst and the frequency of F2 at voicing onset. Note that the
release burst and the F2 themselves do not qualify as acoustic
cues, as they are multidimensional acoustic structures. Also a
"F2 frequency of 1800Hz at voicing onset" is not a cue,
but a value of the cue "F2 frequency at voicing onset".
Let us compare my definition of acoustic cue to the one by Repp (1982). I have dropped the conditions that a cue:
Thus, the only meaningful element in Repp's definition that remains
is that an acoustic cue is a "portion of the signal",
and I have tried to sharpen up the definition of a "portion".
The resulting definition of acoustic cue is similar to that of
a "(pattern) feature" in the automatic speech recognition
literature in the sense of being simply a measurement result.
A major difference between the cue and the pattern feature is,
however, that, while in statistically-based automatic speech recognition
the same set of feature measurements is repeated at constant intervals
throughout the speech signal, the details of the cue measurement
are dependent on the type and position of the earlier detected
landmark.
Definition: Specific auditory context
The specific auditory context is defined as the set of earlier
extracted values of acoustic cues which is available at a given
point in time.
As for the general auditory context, the most recent incoming
specific auditory information is put in storage, where it is available
for further processing. Old cue values are assumed to be lost
or to become progressively blurred or noisy with the passage of
time. The storage of cue values corresponds to Cowan's "long
auditory store" (the second component of PAS), with a time
constant of at least several seconds.
4.4. Classification
The specific auditory context and the phonological context constitute
the input to the classifier. The output of the classifier is phonological labels.
Definition: Classification
Classification is defined as the mapping of a vector of cue values
onto a phonological label.
Essential to the concept of classification is that the number
of possible output elements is smaller than the number of possible
input elements. Theoretically, the input vector to the classifier
at hand consists of a vector of scalar cue values, each of which
can assume any real value. Hence, the number of input elements
is infinite, while the output can only assume one value out of
a finite set of discrete values (phonological labels).
Definition: Phonological label
A phonological label is defined as an element of a finite set
of phonologically meaningful elements.
Each phonological label is associated with at least one landmark.
Examples of phonological labels are distinctive features such as [+voice], articulatory movements such as "labial closure", segments such as [b], or syllables such as [ba].
Definition: Phonological context
Phonological context is defined as the set of earlier established
phonological labels which is available at a given point in time.
Definition: Phonological cue
A phonological cue is defined as an element of the phonological
context.
For example, if the value of the feature continuant has been labelled
as [-continuant], this value may have an influence on the subsequent
measurement of place of articulation of the same consonant. Or,
the labelling of a preceding vowel as [i] may influence the classification
of the following consonant.
As for the auditory contexts, the most recently generated phonological
labels are put in storage. Old labels are assumed to be lost or
to become progressively blurred or noisy with the passage of time.
A time window is associated with the availability of phonological
cues, which is assumed to be at least as long as the window associated
with the specific auditory context.
The classifier will be discussed in more detail in section 4.
4.5. A note on information storage
In the framework it is assumed that three types of short-term
memory are used. One memory is associated with each of the 3 levels
of information that are assumed to be explicitly used by the listener:
the general auditory level, the specific auditory level, and the
linguistic level. The memories are necessary because before one
of the modules can process information from level A to level B,
a certain body of information has to be accumulated at level A.
For instance, before a classification can be made, the values
of all relevant cues have to be available.
The specific auditory storage would not be necessary if it is
assumed that for each classification all cues are measured simultaneously
on the general auditory storage. I have chosen, however, to associate
the general auditory context with Cowan's short auditory store
and the specific auditory context with his long auditory store
(Cowan, 1984). Cowan estimated the maximum duration of the short
store at 200 to 300ms. This implies that, if the specific auditory
memory were to be dropped, only cues within a 200 to 300ms window
would be able to contribute to a phonetic classification. Repp
and other Haskins researchers have repeatedly demonstrated that
listeners integrate acoustic information pertaining to a particular
phonetic distinction over temporal windows with a length of up
to 400ms (e.g. Repp et al., 1978; Repp, 1980; Mann and Repp, 1981;
Repp, 1988). This is somewhat longer than Cowan's short auditory
storage, but of the same order of magnitude.
Besides the respective time constants associated with the long
and short auditory stores, there is an additional motivation to
use both these stores in the present framework. Cowan claimed
that the short store holds a relatively unanalysed auditory representation
of the incoming signal, while the long store holds partially analysed
information. Obviously these properties corresponds closely to
the notions of the general and specific auditory information in
the framework.
The memory associated with the linguistic context is not an auditory
memory because it contains abstract linguistic units such as distinctive
features or segments. I assume that this memory is therefore situated
at some cognitive level of information processing.
4.6. Example
Let us clarify the time course of the framework by means of a
discussion of a hypothetical example of the classification process
in a phonetic experiment. Suppose it is the subject's task to
classify the second consonant in a CVCV nonsense utterance, for
example [bada]. For the moment, a number of additional assumptions
will be made, the most important of which are (1) classification
is made in terms of distinctive features; and (2) relevant acoustic
cues are the frequencies of the first three formants and their
first time derivatives plus some additional burst cues. Note that,
although these choices reflect some of my preferences in the actual
filling-out of the framework, they are by no means fundamental.
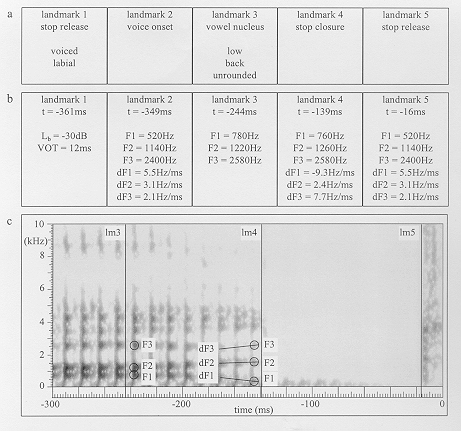
Figure 2 displays the status of the listener at a particular instant
in time, as it is represented in the framework. The "present"
time instant is defined as t = 0 at the plosive release
of [d]. The three rectangles in Figure 2 represent, from top to
bottom, the present phonological context, the present specific
auditory context, and the present general auditory context, respectively.
The general auditory context contains a time-frequency representation
of the most recent 300ms of the stimulus. Both the specific and
the phonological contexts, having much longer time constants,
contain information on the entire stimulus so far. All information
in the latter two contexts is associated with landmarks. As indicated
in the top two boxes, five landmarks have been detected in the
stimulus so far: a stop release landmark at t = -361ms,
a voice onset landmark at t = -349ms, a vowel nucleus landmark
at t = -244ms, a stop closure landmark at t = -138ms,
and a stop release landmark at t = -18ms. Note that the
specific auditory context contains psychophysical information
in terms of e.g. times and frequencies. The phonological context,
on the other hand, contains none of these, and the time dimension
is represented simply as an ordering of the landmarks and their
associated distinctive features.
Although the "target" consonant has not yet been classified,
a number of classifications have already been made. First of all,
landmark 1 was classified as a stop release landmark, based on
the sudden energy increase across frequencies detected by the
landmark detector. Next, landmark 2 was classified as a voicing
onset landmark based on the onset of periodicity.
After these classifications some acoustic cues were measured.
The overall level of the burst (log-energy) was established to
be 30 dB below the overall level of the first few voicing periods,
and the voice-onset time (VOT), defined as the interval between
landmark 1 and 2, was found to be 12ms. In addition the frequencies
of F1, F2 and F3 were measured at the first voicing pulse, as
well as their change in frequency over the first few voicing pulses.
Now a new classification was made. The initial stop consonant
was classified as voiced based on the acoustic cue values of the
relative burst level, VOT, the F1 frequency at voicing onset and
its initial change, and the phonological cue that the consonant
is a stop.
At t = -244ms a new landmark (L3) was placed (this landmark
is visible in the present general auditory context). Landmark
3 was classified as a vowel nucleus based on the detection of
a local minimum in spectral change. The frequencies of the first
3 formants were measured at this landmark. Based on these 3 acoustic
cues, the previous acoustic cues measured at landmarks 1 and
2, and the phonological cue that the consonant is a voiced stop,
the consonant was classified as labial, which fully specifies
the initial consonant as [b].
Due to a sudden decrease of energy across frequencies, landmark
4 was placed at t = -138ms and classified as a stop closure.
The frequencies of the first 3 formants, as well as their initial
change, are measured just before the closure landmark. Based on
the available acoustical cue values for landmark 2, 3 and 4, as
well as the phonological cue of the initial consonant being labial,
the vowel is classified as low, back and unrounded, or [a].
Most recently, a stop release landmark has been positioned at
t = -18ms due to a sudden energy increase across frequencies.
No acoustic cues have been measured here yet and the place and
voicing features of the consonant associated with landmark 4 and
5 (and 6, the upcoming voice onset landmark) have yet to be classified
before the actual response can be given. These classifications
are postponed until more cues are available. If the hypothetical
experiment would involve gating (e.g., Cotton and Grosjean, 1984)
and the sound presented so far actually was the complete gated
stimulus, the listener would have to base the classification of
the consonant on the information currently available. Based on
the cue values associated with landmark 3 and 4, an educated guess
could be made on the consonant's place of articulation. The classification
of the voicing feature would however be very difficult, as no
information on VOT or F1 at voice onset are available.
5. Aspects of the classifier
This section is devoted to a discussion of the classification
module. In the history of research on phonetic perception relatively
little attention has been given to this topic. In my opinion,
however, some basic knowledge of pattern-recognition theory greatly
helps in the formulation of research questions as well as the
interpretation of classification data generated in a phonetic
perception experiment. In this section I will introduce and discuss
a number of basic issues relevant to the classifier in the framework.
I will concentrate on (1) the classification strategy, (2) the
input representation, and (3) the output representation.
5.1. Classification strategies
Before a number of classification strategies are discussed, first
some extra definitions are given.
Definition: Cue space
The cue space is defined as a vector space which is spanned by
acoustic cues. The cue extractor effectively maps individual utterances
onto points in the cue space.
In pattern-recognition literature the cue space is usually termed
feature space. Figures representing cue spaces abound in the phonetic
literature, see Liberman et al. (1957), Figure 2, Cooper et al.
(1952), Figure 3, and Hoffman (1958), Figure 4, for some well-known
early examples of 1-, 2-, and 3-dimensional cue spaces for stop
consonants, respectively.
Definition: Response region
A response region is defined as the subspace of the cue space
either which is assigned to one phonological label, or where the
probability of selecting a particular phonological label is larger
than the probability of selecting any one of the other labels.
Definition: Class boundaries
A class boundary is defined as the subspace of a cue space which
separates two response regions. At a class boundary the labels
associated with the two adjacent response regions are equally
likely.
Definition: Convex response region
A response region is convex if a line segment connecting any pair
of points with the same label lies completely within the response
region associated with that class.
On a conceptual level one could say that a convex response region
has a highly regular shape without any dents or protrusions. For
examples of convex response regions in the phonetic literature
see all "territorial maps" for the classification of
the four fricative-vowel syllables in Nearey (1990) and (1992).
For an example of non-convex response regions see Jongman and
Miller (1991), Figure 2. Note that the response region for /t/
consists of two subregions - which in itself makes the /t/-region
non-convex - each of which is also non-convex.
Definition: Classifier complexity
The classifier complexity is defined as the number of free parameters
in the classifier that are to be estimated.
This definition only holds for truly automatic classifiers. Non-automatic
classifiers are often used in phonetic research. For example,
Blumstein and Stevens (1979) used carefully hand-prepared templates
which were designed to optimally classify a training set of tokens,
and to which during testing individual tokens were matched visually.
The complexity of such non-automatic classifiers can be roughly
assessed by estimating roughly how many parameters would need
to be fitted if a truly automatic classifier were to simulate
the non-automatic one.
Both in the field of automatic pattern recognition and the field
of human classification behaviour, a number of different classification
strategies have been put forward (for an overview, see Medin and
Barsalou, 1987; Ashby, 1992). Roughly, they can be divided into
three classes.
Prototype models:
Each response class is represented by one prototype, which is
a point in the cue space. Probabilities for choosing each of the
possible response labels are calculated on the basis of distances
of the stimulus to each of the prototypes. The similarity-choice
model (Shepard, 1958; Luce, 1963) and the fuzzy logical model
of perception (Oden and Massaro, 1978) are well-known prototype
models.
Exemplar models:
Each response class is represented by a number of exemplars, which
may be conceptionalized as a cloud of labelled points in the cue
space. Probabilities for choosing each of the possible response
labels are calculated on the basis of average distances of the
utterance to all exemplars of each class (Nosofsky, 1986).
Boundary models:
The cue space is divided up into response regions by a number
of class boundaries. The position of a stimulus in the cue space
is established through an evaluation of its position relative
to all class boundaries. The stimulus receives the label of the
response region it finds itself in. Detection theory (Macmillan
and Creelman, 1991) and general recognition theory (Ashby and
Perrin, 1988) use a boundary-based approach.
A few remarks are in order here. First of all, although the three
classification strategies differ in their fundamental assumptions,
their behaviour can be hard to distinguish purely on the basis
of classification data. It has been shown, for example, that the
similarity-choice model (which is a prototype model) is asymptotically
equivalent to a boundary-model based on the single-layer perceptron
(Smits and Ten Bosch, submitted). Other experimental tasks than
straightforward classification may be needed to distinguish between
the strategies. If it is assumed, for example, that a token is
classified more rapidly with decreasing distance to the reference,
the boundary-based approach would predict that subjects classify
a stimulus near a class boundary most rapidly. In contrast, a
prototype-based approach would predict that subjects classify
a stimulus near a class prototype most rapidly. Hence, a categorisation
response time experiment may discriminate between the two strategies
(e.g. Ashby et al., 1994).
Secondly, it needs to be stressed that the finding that some stimuli
are "better" or more prototypical instances of a category
than others (e.g. Kuhl, 1991) does not imply that a prototype-based
strategy is actually used in classification. The essential difference
between the prototype-based and the boundary-based classification
strategies is that the classification in based upon a comparison
of the stimulus to the class prototypes or the class boundaries,
respectively. Both strategies will however rate a stimulus far
away from the class boundary as typical and one close to the class
boundary as non-typical.
Which of the three general types of classification strategies
most resembles human phonetic classification behaviour is unclear.
Indeed, although each of these models have played a role in the
history of research on phonetic perception, experiments explicitly
addressing this issue are rare. Early phonetic research operated
exclusively within the boundary approach (e.g. Liberman et al.,
1957). Later, extensive work by Rosch on the use of prototypes
in various kinds of human categorisation behaviour (see for example
Rosch, 1973) inspired a prototype-based approach in the modelling
of phonetic perception (e.g. Samuel, 1982; Kuhl, 1991). Recently,
Pisoni and co-workers have argued against an account of phonetic
perception in which incoming sounds are matched against idealised
prototypes. Instead, an exemplar-based approach is advocated (e.g.
Pisoni, 1992; Nygaard and Pisoni, 1995).
5.2. Input representation
The cues that span the cue space form the input representation
of the classifier. Many different types of cues have been proposed
over the years:
The assumption that a certain type of cues is used will have consequences
for the resulting complexity of the classifier. If one assumes,
for example, that formant frequencies are the relevant cues in
place perception of stop consonants, and an experiment is set
up in which formant-frequency continua are presented to listeners
for classification, the resulting data may require a complex classification
model. Conclusions in this vein were drawn on the basis of the
early Haskins speech perception experiments, which inspired the
formulation of the motor theory (Liberman et al., 1967). If, on
the other hand, an input representation is chosen in terms of
gross spectral shapes, the classification model may be much simpler,
which was essentially advocated by Stevens and Blumstein (1981).
Hence, the complexity of the phonetic classifier is intimately
tied to its input representation.
5.3. Output representation
The output representation is determined by the set of labels used
by the classifier. Note that the output representation can be
different from the actual response set used in the phonetic experiment,
which is usually segmental. For example, the subject may have
to choose one of six consonants B, D, G, P, T, or K. Internally,
however, the classifier may output distinctive-feature-sized labels.
In such a case an additional mapping from the internal label to
the response label has to take place. It is assumed here that
this mapping is trivial.
The representation issue in speech perception is a long-standing
one and it is by no means settled (e.g. theme issue on phonetic
representation, J. Phonetics 18(3), 1990; Marslen-Wilson, 1989).
Often used representations are articulatory gestures (e.g. Fowler,
1986), distinctive features (e.g. Stevens, 1995), and segments
(e.g. Liberman et al., 1967), which all are valid candidates for
the output representation in the present framework.
Obviously, as is the case for the input representation, assumptions
on the nature of the output representation have far-reaching implications
for the classifier. If the output representation is, for example,
assumed to be in terms of binary features, the cue space for each
individual feature classification is divided into 2 subspaces
only, and it is reasonable to expect that the dimensionality of
the cue space is relatively low. If, on the other hand, it is
assumed that the classifier outputs segments, the number of response
regions in the cue space is large and the dimensionality of the
cue space is assumed to be proportionally large.
6. Discussion of some theoretical issues and experimental findings
in the context of the framework
In this section a number of major theoretical issues as well as
experimental findings will be discussed within the proposed framework.
This discussion will hopefully show that the pattern-recognition-based
framework indeed provides useful insight into a number of phonetic
issues and findings. The issues and findings that will be discussed
relate to:
6.1. The segmentation issue
Beside the variability versus invariance issue, one of the basic
issues in speech perception is that, although, when listening
to speech, one has the impression of receiving a string of discrete
linguistic units (whatever their size), the acoustic signal cannot
be cut up into discrete segments corresponding with these linguistic
units. This issue is commonly known as the "segmentation
issue". The segmentation issue and the variability and invariance
issue are naturally related because both originate (at least partially)
from coarticulation. How does the proposed framework deal with
this issue?
As discussed earlier, the framework incorporates the "landmark
detection" strategy proposed by Stevens and co-workers. A
basic aspect of this approach is that the speech signal is not
segmented at all. Instead of acoustic segments important instances,
the acoustic landmarks, are identified (see Liu, 1995, for a more
elaborate discussion). The landmarks are classified in a broad
phonetic sense (e.g. manner features) and are subsequently used
as reference points for cue measurements. Although each of the
cues is associated with a single landmark (or for duration cues
possibly two), in any subsequent classification cues associated
with several different landmarks may be involved, as is the case
in some of the examples discussed so far. Eventually, the classifications
will result in a string of phonological labels as was illustrated
in Figure 2. Thus we find that the specific auditory context for
each classification that is made in the framework strongly overlaps
with the specific auditory contexts of other classifications.
In conclusion, because the landmark-detection approach is adopted,
the segmentation issue is hardly relevant in the context of the
framework.
6.2. Variability and invariance
As discussed in the introductory section, among the most basic
problems in research on phonetic perception is the variability
and invariance issue. In this discussion I will restrict myself
to variability and invariance related to phonetic context only.
The variability and invariance issue has two components (e.g.
Pisoni and Sawusch, 1975), namely acoustic variability versus
perceptual constancy and acoustic constancy versus
perceptual variability. A well-known example concerns the role
of the frequency of F2 at voicing onset (F20)
in the perception of consonantal place of articulation. Numerous
experimental studies has shown that F20 is a
very important cue for consonantal place of articulation. However,
the interpretation of this cue apparently strongly depends on
the phonetic context. For example, a F20 of
1600Hz may cue a /b/ or /d/ depending on the following vowel (acoustic
constancy versus perceptual variability). On the other hand, any
F20 within the range of 900Hz to 1800Hz may
cue a /b/, depending on the following vowel (acoustic variability
versus perceptual constancy).
I will attempt to show here that this type of "problem"
arises from an overly simplistic view of phonetic classification.
First of all, the considerations presented above seem to be based
on the assumption that a phonetic classification is based on the
value of a single acoustic cue. Based on considerations of simplicity
or parsimony this would undeniably be a desirable feature of a
perception model. However, despite the large body of research
devoted to finding the single acoustic cue that dominates the
perception of a given phonetic contrast, there seems to be no
fundamental reason whatsoever why the perceptual system would
operate in such a fashion. Indeed, there seems to be convincing
evidence that large numbers of acoustic cues play a significant
role in the perception of any phonetic contrast (e.g. Lisker,
1978; Diehl and Kluender, 1987).
Furthermore, an implicit assumption that often seems to be made
is that in order for two sounds to belong to the same phonetic
class they need to be acoustically similar, or expressed in terms
of cues, their representations in the cue space need to be close
together. This is fundamentally untrue. Even in a very simple
classifier, sounds that are mapped to points in the cue space
that are far apart may receive the same label, while points that
are close together may receive different labels.
It is useful to approach these issues from a pattern-recognition angle. Let us look at an example, based on a subset of the data of an acoustic and perceptual study of the voiced stops /b/ and /d/ in Dutch (Smits et al., submitted a, b). Figure 3 is a one-dimensional "scatterplot" of the values of F20 measured on 8 tokens of /bV/ and 8 tokens of /dV/, where V taken from /a, i, y, u/, spoken by a male Dutch talker.
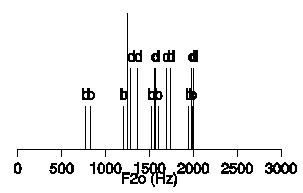
As can be seen in Figure 3, there is a large within-class variability,
and the classes overlap to a great extent. If a boundary-based
classification were to be made on the basis of this single cue,
the class boundary would optimally be placed at approximately
1250Hz, as indicated by the tallest line segment in Figure 3.
This would lead to a classification error rate of 25% (4 out of
16 misclassified).
Let us now measure another cue, the frequency of F2 at the vowel nucleus (F2n), in addition to F20. Figure 4 represents a two-dimensional cue space spanned by F2n and F20.
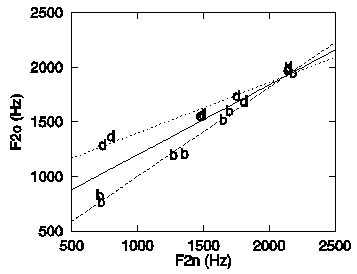
The optimal classifier using the two cues has a rate of incorrect classification of 12.5% (2 out of 16), which is half the rate obtained for the single cue. The associated
class boundary is represented by the solid line in Figure 4. The
two dashed lines in Figure 4 represent the locus equations associated
with the two consonants (see also Sussman et al., 1991). Clearly,
all points cluster closely around their associated locus-equation
lines. Sussman hypothesised that the locus equations may function
as perceptual class prototypes. Incoming stimuli would be mapped
onto a point in the F20- F2n
plane and the stimulus would be classified as the locus equation
which is closest. This is equivalent to using the boundary depicted
in Figure 4.
What can we learn from this simple example so far? First of all,
theoretically speaking, the more stimulus measurements are used
by the classifier, the higher the classifier's potential in terms
of correct classification rate. In our example the 2-cue classifier
clearly does a better job than the 1-cue one. Of course, in practice
the classifier complexity rapidly increases with the dimensionality
of the cue space, e.g. in terms of the number of parameters needed
to defined a class separator. Therefore, a trade-off needs to
be made in a classification model as well as in the perceptual
system. It is stressed here, however, that from a pattern-recognition
point of view, a large within-class variability on a single cue
is only fundamentally problematic if the classifier is indeed
restricted to using only this cue. Even when two classes strongly
overlap on one acoustic dimension, using one or more additional
cues may dramatically increase the correct classification rate,
or even completely disambiguate the problem. This seems a rather
trivial point to make, but it does steer phonetic problem formulations
away from classical questions like "what is the best or most
disambiguating cue" towards issues like "what is the
cue space dimensionality" and "what set of cues leads
to good or human-like classification".
Secondly, utterances that are acoustically very different on a
number of important cues may receive the same label while utterances
that are acoustically very similar may receive different labels.
Consider for example three hypothetical utterances with (F2n
, F20) pairs of (1kHz,1kHz), (2kHz,1.7kHz)
and (2kHz,1.9kHz). The first two utterances, although being far
apart in the cue space (Euclidean distance of approximately 1.2kHz),
are both classified as /b/ by the classifier of Figure 4. The
third utterance, on the other hand, though being close to the
second one (Euclidean distance of 0.2kHz), is classified differently,
namely as /d/.
Thirdly, from the viewpoint of the classifier, all cues are equal. In our example, F20 and F2n have exactly the same status. We, being phoneticians, know that F2n is almost completely determined by the vowel identity and we might be tempted to call it a "vowel cue" or a "context cue". However, from the classifier's perspective, a set of cues is measured and a classification is subsequently made. Thus, the status of F2n as an acoustic cue for stop place of articulation is exactly the same as that of F20.1
Finally, the potential role of an acoustic cue in the perception
of a phonetic distinction can only be established within the context
of the total set of cues that is investigated. The value of a
cue cannot be measured on the basis of its classification potential
in isolation. For example, in the carefully pronounced CVs used
for the example, F2n considered in isolation
has no disambiguating value whatsoever. However, within the context
of the two-cue set together with F20 , F2n
does play an important role in the classification process.
Let us now use the example to further scrutinise the issues of acoustic variability versus perceptual constancy and acoustic constancy versus perceptual varibility. Figure 5 again depicts the F2n x F20 space with the /b/-/d/ class boundary. In addition four arrows are drawn in the Figure.
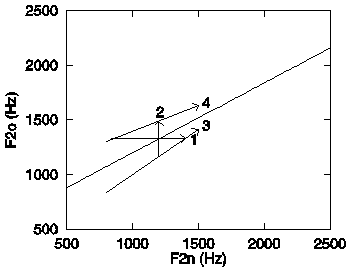
Arrow 1 shows that, although F20 is constant
(1325Hz), the percept is shifted from /d/ to /b/ when the F2n
is raised from 845Hz to 1400Hz. This is a classical case of perceptual
variability versus acoustic constancy, where the perceived consonant
changes although the "consonant property" F20
remains constant (e.g. Liberman et al., 1967; Lindblom,
1986; Nygaard and Pisoni, 1995). Arrow 2 shows that the percept
is changed from /b/ to /d/ by shifting F20 from
1165Hz to 1490Hz, while keeping F2n constant.
This case refers to classical experiments using F20
continua (e.g. Liberman et al., 1954), which have been used to
emphasise the role of F20 (or the F2 transition)
for the perception of consonantal place of articulation. I would
like to argue that both are simply two sides of the same coin.
(Here, the "coin" would the complete picture of the
cue space plus perception model, where the model is represented
by the class boundary). Both refer to a situation where one cue
is held constant while another is changed, thus moving through
the cue space parallel to one of the cue axes. Naturally, if the
class boundary is not parallel to one of the axes, chances are
that it will be crossed at some point and the percept will change.
Referring back to a point made earlier, both cues have the same
status within the classification process, so arrows 1 and 2 describe
fundamentally equivalent situations. Moreover, formulated within
a pattern-recognition context, the issue of acoustical constancy
versus perceptual variability does not seem to be a particularly
interesting one. It seems to arise only when one concentrates
on a single cue, while the actual classification process is multidimensional.
Arrows 3 and 4 represent acoustical variability versus perceptual
constancy. The arrows are placed on the locus equations of /b/
and /d/. While arrows 1 and 2 are parallel to a cue axis, arrows
3 and 4 are (more or less) parallel to the class boundary. This
obviously results in perceptual constancy as the class boundary
is not crossed. As argued earlier, if two stimuli have been given
the same label, the points in the cue space associated with the
two stimuli do not need to be close together, they only need to
be in the same response region. Figure 5 clearly illustrates a
situation in which both response regions are very large - indeed
they are half-infinite. A word of caution is needed however. There
is a bounded "natural region" in the cue space to which
all stimuli will be mapped. Obviously, natural stimuli with an
F20 of 15 kHz do not occur, and if synthesised,
the perceptual system is unlikely to treat the resonance at 15
kHz as a second formant. Still, response regions may be acoustically
quite extensive in practice.
6.3. Cue trading relations
As a definition of a cue trading relation I will use the one proposed
by Repp (1982, p. 87):
Definition: Cue trading relation.
A trading relation between two cues occurs when "... a change
in the setting of one cue (which, by itself, would have led to
a change in the phonetic percept) can be offset by an opposed
change in the setting of another cue so as to maintain the original
phonetic percept."
Many examples of cue trading relations have been reported in the
literature, (see Repp, 1982, for an overview). Perhaps the best
known trading relation is the one between voice-onset time (VOT)
and first formant onset frequency (e.g. Lisker, 1975). Lengthening
VOT in a synthetic stop-vowel syllable which is ambiguous with
respect to the voicing feature will increase the proportion of
"voiceless" responses. However, this change can - to
a certain extent - be repaired by creating an upward F1 transition
by lowering F1 at voicing onset.
In this section I will argue that cue trading relations, such as the one described, naturally arise when a classification is multidimensional. Let us study an example. Ohde and Stevens (1983) have shown that a trading relation exists between F20 and the level Lb of the release burst in the perception of the labial-alveolar distinction in stop-vowel syllables. Both a high F20 and a high Lb cue an alveolar response, while the opposite holds for the labial response. The trading relation here refers to the finding that an increase in F20 can be offset by a decrease in Lb.
I have simulated this classification behaviour using a simple pattern classifier. On the same /b/-vowel and /d/-vowel utterances used for the earlier example I measured the level of the release burst Lb (for details on the measurement procedure see Smits et al., submitted b). Figure 6 is a scatterplot of the resulting values of Lb combined with the F20 values obtained earlier.
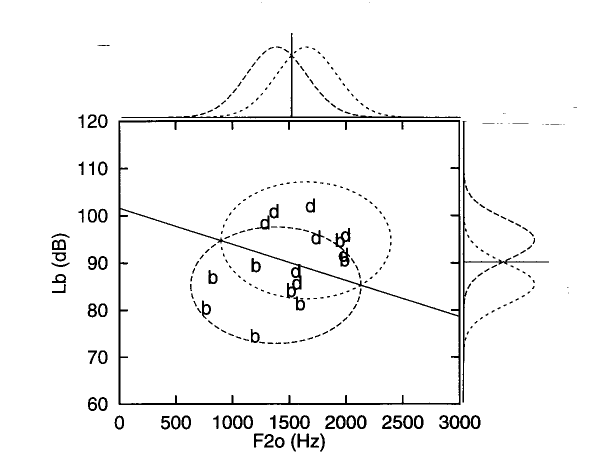
Figure 6. Scatterplot of measurements of Lb
and F20 made on the same utterances used for
Figures 4 and 5. The ellipses indicate the  = 2 equi-probability lines of the two-dimensional (equal variance,
zero covariance) Gaussian distributions fitted on the data. Again
the x symbols and the short dashes refer to /d/ and the + symbols
and the long dashes refer to /b/. The bell shapes on the top and
right-hand side of the figure are the marginals of the two-dimensional
distributions. The solid line indicates the /b/-/d/ class boundary.
= 2 equi-probability lines of the two-dimensional (equal variance,
zero covariance) Gaussian distributions fitted on the data. Again
the x symbols and the short dashes refer to /d/ and the + symbols
and the long dashes refer to /b/. The bell shapes on the top and
right-hand side of the figure are the marginals of the two-dimensional
distributions. The solid line indicates the /b/-/d/ class boundary.
Let us now analyse this situation using a well-known classification technique called linear discriminant analysis (LDA). Two-dimensional Gaussian probability-density functions (pdfs) can be calculated for the data of each class. As the actual number of data points is small, the assumption is used that the two classes have identical covariance matrices with covariances equal to zero. Equi-probability contours (corresponding with 2 standard deviations from the mean) of the resulting Gaussians are represented as dashed ellipses in Figure 6. Note that, as a result of the assumptions
of identical covariance matrices with zero covariance, the ellipses
are simply shifted versions of each other, and their principle
axes are parallel to the cue axes. The solid line represents the
optimal class boundary in the Bayesian sense, meaning that the
probability of misclassification is minimised. The marginal distributions
of the two-dimensional Gaussians along with their respective optimal
class boundaries are displayed at the top and right-hand side
of the figure.
Figure 6 clearly shows that in the classifier thus defined, both a high F20 and a high Lb favour a /d/ response, as was found by Ohde and Stevens (1983). It is easy to demonstrate that this classifier will also produce a trading relation between F20 and Lb, like the listeners in Ohde and Stevens's experiments. Figure 7 again shows the F20 x Lb cue space with the /b/-/d/ boundary.
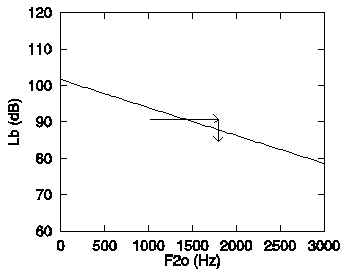
Figure 7. The F20 x Lb
cue space of Figure 6, with the /b/-/d/ boundary (solid line).
The arrows illustrate a cue trading relation.
The arrows in Figure 7 demonstrate the cue trading. Starting with
a stimulus with a F20 of 1020 Hz and a Lb
of 90.8 dB2, we increase F20 to 1800 Hz, thereby
crossing the class boundary from /b/ to /d/. Next we move back
into the /b/ region by lowering Lb to 84.8 dB.
Thus, a trading relation is established, because the perceptual
change induced by changing one cue is offset by a change in another.
Note that in this example we have not moved outside the natural
cue regions (indicated by the ellipses - see Figure 6).
Some evidence for such decision processes can be actually found
in the phonetic literature. Blumstein and Stevens more or less
assumed such a process in their classification of place of articulation
based on gross spectral templates (Blumstein and Stevens, 1979).
The decisions can be summarised as follows:
if (mid-frequency peak) then velar
else
if (rising spectrum) then alveolar
else labial
which is a hierarchical process of two separate decisions3.
This type of decision making in place perception for stops has
later been more or less replicated using more formal classification
models by Forrest et al. (1988) and Smits and Ten Bosch (submitted).
Nearey (1990, 1991) has explicitly tested the goodness of fit
of several models on the data of Whalen (1989) for the perception
of fricative-vowel syllables. He demonstrated that the "primary
cue model", in which it is assumed that all boundaries are
parallel to the cue axes, provides a significantly worse fit than
a model in which this assumption is dropped. An explicit test
of a general hierarchical model in which the vowel identity influences
the consonant classification was not included, however.
The phenomenon of cue trading relations has been put forward as
evidence for the "speech is special" doctrine supported
by a number of motor theorists (e.g. Repp, 1982). The considerations
presented above do not support this view. Instead, it is argued
that cue trading is a natural expression of the multidimensionality
of a classification process. This holds for classification processes
is any modality, so it is definitely not special to speech perception.
If anything, it is the multidimensionality aspect that is special,
not the speech aspect. Interestingly, at some point Repp (1983)
did put forward an argument in a similar vein, although he did
not explicitly specify how the cue trading mechanism comes about.
Recently, Parker et al. (1986) and Sawusch and Gagnon (1995) have
shown that it is indeed possible to train subjects to classify
abstract auditory stimuli using two stimulus (cue) dimensions.
The subjects produced cue-trading behaviour in their classification,
which confirms the multi-dimensionality account of cue trading.
Furthermore Sawusch and Gagnon (1995) showed that the subjects
were able to generalise their categorisation to a new set of stimuli
which were acoustically dissimilar to the training set. Essentially,
these experiments show that listeners are able to set up a perceptual
pattern recognition mechanism based on a number of training exemplars,
and, when the classifier is sufficiently well-defined, subsequently
classify new auditory patterns. It seems reasonable to assume
that such perceptual mechanisms provide the basis for phonetic
perception. Earlier failures to elicit cue-trading behaviour in
listeners using abstract auditory stimuli (e.g. Best et al., 1981)
may be caused the fact that the listeners had not been effectively
trained in actually using more than one auditory cue in the categorisation
task.
Massaro has been advocating a pattern-recognition approach to
phonetic perception for a long time (e.g. Massaro and Oden, 1980;
Massaro, 1987). As Massaro's fuzzy logical model of perception
(FLMP) is in essence a multidimensional (fuzzy) pattern classifier,
it reproduces cue trading relations. Unfortunately, the work of
Massaro and colleagues is sometimes given the interpretation that
the cue trading/integration phenomena essentially arise from the
use of fuzzy logic and prototypes in the classification model
(e.g. Pisoni and Luce, 1987). Neither of these properties are
essential to cue trading, however. Only the multidimensionality
of the classification process is a necessary condition, as was
shown above.
6.4. The role of phonetic context in perception
As described earlier, three types of context are distinguished
within the general framework presented in this paper: general
auditory context, specific auditory context, and phonological
context. From such a starting point the observation that an acoustic
cue is "interpreted in a context-dependent manner" (for
example, the effect of F20 depends on the vowel
context) is ambiguous. At least two very different situations
can apply. First of all, several cues may be used in the classification,
some of which are "directly" related to the target (e.g.
the consonant) while others are "directly" related to
the context (e.g. the vowel). In a previous section we encountered
such a situation, regarding the classification of stops as /b/
or /d/ using F20 and F2n.
I was argued that a formal distinction between the cues is not
valid. The total set of cues used in the classification constitute
the specific auditory context, and the status of the various cues
is identical, i.e. all cues are equally "direct".
In the second situation, a phonological label that was obtained
earlier may influence the current classification. For example,
it may be the case that the vowel is classified prior to the consonant
and the details of the classifier (for example the exact boundary
locations) depend on the earlier established vowel identity. In
this situation the relevant context is phonological.
In many phonetic experiments reported in the literature the distinction
between the role of auditory and phonological context is not made,
and it is hard to establish to which of the two the observed "context
effects" can be attributed (e.g. Cooper et al., 1952; Schatz,
1954; Summerfield and Haggard, 1974; Mann and Repp, 1980, 1981;
Mann, 1980; Fowler, 1984; Whalen, 1989). A number of investigations
have however explicitly focused on the distinction between the
two types of context and have provided evidence that in a number
of phonetic classification tasks phonological context is indeed
used by listeners. Carden et al. (1981) showed that, assuming
that phonetic perception produces distinctive feature labels,
place perception is dependent on perceived manner. It was demonstrated
by Massaro and Cohen (1983) that the perception of C2
in C1C2V and C0C1C2V
syllables is influenced by the identity of C1
and C0C1, respectively. Finally,
Ohala and Feder (1994) showed that perception of V1
in V1CV2 utterances depends
on the identity of C. The evidence provided by these studies has
led me to include the concept of phonological context in the framework,
as well as the information flow from the phonological level to
the classifier.
Repp (1982) made an explicit distinction between trading relations
and context effects. His definition of a trading relation has
been cited earlier. A context effect occurs, according to Repp,
"...when the perception of a phonetic distinction is affected
by a preceding or following context that is not part of the set
of direct cues for the distinction ..." (Repp, 1982, p. 87).
As argued earlier, the notions of "context" as well
as "direct cues" are insufficiently precise from my
viewpoint. However, Repp's examples following the definition strongly
suggest that his distinction between trading relations and context
effects is equivalent to my distinction between auditory and phonological
context. For example, Repp speaks of a context effect when "...
the perceived vowel quality modifies the perception or interpretation
of the fricative cues ..." in the perception of a fricative-vowel
syllable (Repp, 1982, p. 88). Assuming that Repp's perceived vowel
quality is equivalent to our phonological vowel label the vowel
quality is a "phonological cue" in my terminology.
At this point it does make sense to distinguish between a direct
acoustic cue and an indirect acoustic cue for the perception of
a phonetic distinction.
Definition: Direct acoustic cue
A direct acoustic cue to the perception of a phonetic distinction
is the output of a cue extraction operation which is explicitly
used in the classification procedure associated with the phonetic
distinction.
Definition: Indirect acoustic cue
An indirect acoustic cue to the perception of a phonetic distinction
is the output of a cue extraction operation which is not explicitly
used in the classification procedure associated with the phonetic
distinction at hand, but which instead is explicitly used in the
classification procedure associated with another phonetic distinction,
whose output is used as a phonological cue in the classification
procedure associated with the phonetic distinction at hand.
An example concerning the perception of CV syllables will clarify
the distinction. If F2n is, together with
F20 , used in the classification of the consonant,
as in one of the earlier examples, it is a direct cue to the perception
of the consonant. If, on the other hand, F2n
is not used in the classification of the consonant, but is used
instead in the classification of the vowel, and the vowel label
influences the classification of the consonant, F2n
is an indirect cue to the perception of the consonant.
In practice the distinction between the two situations will be
very hard to make experimentally. For example, if one would vary
the value of an indirect cue to the perception of the consonant
in synthetic CV syllables, this would affect the perception of
the consonant, just like a direct cue would. Within our framework,
however, the process responsible for this influence is different
in the two situations.
Let us briefly address the issue how the use of phonological cues
may be implemented within the proposed framework. First of all,
the set of cues used in the classification process can be adjusted.
For example, let us assume that the classifier's output labels
are distinctive features, and already classified manner features
influence the classification of place features. Then, depending
on the value of the feature nasal, the cues used in the place
classification may or may not include the cue Lb
(burst level). Secondly, the details of the classification procedure
may be adjusted. Depending on the basic classification strategy
that is hypothesised, these adjustments may be implemented as,
for example, shifts and rotations of linear class boundaries,
or relocations of class prototypes.
6.5. The theory of acoustic invariance
The issue of acoustic invariance has received much attention throughout
the history of research on phonetic perception. It is useful to
consider this issue from the viewpoint of the framework. Blumstein
and Stevens, the principle proponents of the theory of acoustic
invariance, proposed that invariant acoustic properties corresponding
to distinctive features are present in the signal, and that these
properties are used by listeners in their categorisation of speech
sounds. The invariant properties are sampled in a relatively short
segment of the speech signal (e.g. 25 ms) and are stable across
all major sources of variability such as phonetic context, speaker
identity, language, etc. (e.g. Blumstein and Stevens, 1981; Stevens
and Blumstein, 1981). Here we will again restrict ourselves to
variability associated with phonetic context. In order to translate
these claims in terms of our model, additional specifications
are necessary on two points:
Concerning the first point, we are faced with the problem here that in Blumstein and Stevens's initial acoustic classification studies, the classification procedures were semi-automatic. In a well-known experiment (Blumstein and Stevens, 1979), stop-vowel utterances were classified according to stop place of articulation by visually matching their onset spectra to spectral templates. The spectral templates were devised such that they put several constraints on the LPC-smoothed onset spectrum of
a token. As the LPC-smoothed spectra were made using a 14-pole
model, each token is essentially described by 14 numbers. Therefore,
effectively a classification takes place in a 14-dimensional cue
space. It is clear that Blumstein and Stevens's property was not
intended to be a scalar quantity, and as such it does not qualify
as a cue within our definition.
With respect to the term "invariant" the situation is
more difficult. In terms of the classification theory I have discussed
so far, "invariant" would at least suggest that all
tokens with the same labels are mapped to the same response region.
However, in the particular implementation of Blumstein and Stevens
(1979) this is strictly speaking not the case. This somewhat paradoxical
aspect of Blumstein and Stevens's approach has already been observed
and criticised by Suomi (1985). The velar template used by Blumstein
and Stevens (1979) actually consists of 7 subtemplates. Their
classification procedure thus effectively distinguishes 9 classes,
7 of which are subsequently combined to form the velar class.
It remains therefore somewhat uncertain what "invariant"
actually means in terms of the framework.
The term "relational invariance" as opposed to "absolute
invariance" has been used by several authors (e.g. Fant,
1986; Sussman et al, 1991). Where absolute invariance applies
when a single property or cue is invariant, relational invariance
refers to situations in which the relation between two or more
acoustic properties or cues is invariant. As discussed earlier,
Sussman et al. (1991) showed that a highly linear relation relationship
exists between F2n and F20
measured on CVC syllables. This relation, called a locus equation,
is an example of a relational invariant.
If we approach the invariance concept in a somewhat more graded fashion, we can distinguish four components within the framework that would influence the "level of invariance":
Obviously, maximum acoustic invariance would be associated with
a one-dimensional cue space, a short auditory context window,
no effects of phonological context, and convex response regions.
Note that on points 1 and 4 the implementation by Blumstein and
Stevens (1979) is far removed from this situation.
6.6. The perceptual relevance of an acoustic cue depends on
the phonetic context
Several studies have indicated that the perceptual relevance of
certain acoustic cues is variable with phonetic context, i.e.
in context A cue 1 dominates perception and cue 2 is hardly relevant
at all, while the reverse holds in context B. Fischer-Jorgensen
(1972) presented "burst-spliced" stop-vowel stimuli
to listeners for classification of place of articulation. These
stimuli consisted of a release burst isolated from a stop with
one place of articulation (e.g. /pa/) spliced onto the burst-less
part taken from an utterance with a different place of articulation
(e.g. /ta/). The results of the experiment showed that listeners
corresponded mainly in accordance with the burst in /i/ context,
while they responded mainly in accordance with the formant transitions
in context /u/. These results have recently been replicated by
Smits et al. (submitted a) for the Dutch language. Summerfield
and Haggard (1974) measured the influence of VOT and extent of
first formant transition on the perception of the /g/-/k/ contrast.
A two-dimensional synthetic continuum was used using CVs with
vowels /a/ and /i/. Their results showed that the VOT cue is much
more important in the /i/ context than in the /a/ context.
Intuitively, phenomena such as those discussed above could be
translated into a perceptual mechanism which "actively"
adjusts the classifier depending on the phonetic context, as was
indeed suggested by Fischer-Jorgensen (1972) and Summerfield and
Haggard (1974). More specifically, Fischer-Jorgensen (1972) observed
that in stop-/a/ syllables the second formant transitions for
labial, alveolar and velar place of articulation are very different
while the bursts are acoustically rather similar. The reverse
was found for the stop-/i/ syllables. Fischer-Jorgensen (1972)
suggested that the perceptual system tunes in on these differences
by giving more weight to formant cues in /a/ context and to burst
cues in /i/ context. In a similar vein, Summerfield and Haggard
(1974) suggested that, as the first formant transition is more
pronounced in /a/ context than in /i/ context it is perceptually
more useful in /a/ context than in /i/ context, and thus is weighted
more heavily.
In our framework the classifier can be adjusted in accordance
with an earlier classified phonological label, through the concept
of the phonological cue. Obviously, such a mechanism can implement
the context-dependent "cue weighting" strategy. Nevertheless,
I will demonstrate in this section that for a number of context-dependent
cue weighting situations it is not necessary to postulate such
a mechanism. It will be shown that the context-dependent cue weighting
behaviour can be reproduced by a "fixed" classifier,
i.e. a classifier which does not employ any phonological cues.
Smits et al. (submitted a) performed a burst-splicing experiment
on Dutch stop-vowel utterances containing the stops /p, t, k/
and the vowels /a, i, y, u/. The burst-splicing procedure was
similar to the one used by Fischer-Jorgensen (1972), and was only
carried out within syllables having the same vowel. Subjects were
required to classify the stimuli as P or T or K. Table 1 lists
the proportion of stimuli that were identified in accordance with
the burst or transitions, respectively, broken down for vowel
contexts. Only the data for speaker 2 in Smits et al. (submitted
a) were used. Note that the burst dominates perception in vowel
contexts /i/ and /y/, while the transitions are dominant in vowel
context /a/.
Table 1. Percentage of listeners' classifications of the burst-spliced stop-vowel stimuli in accordance with the burst, the transitions, or the remaining class. For example, if the stimulus consists of a /pa/ burst spliced onto the burst-less part of /ta/, then the response P would be in accordance with "burst", T with "trans", and K with "other".
trans |
|||
In follow-up study a simulation of the listeners' classification
behaviour was carried out (Smits et al., submitted b). A large
number of acoustic cues for place of articulation suggested in
the phonetic literature were measured on the stimuli. Next it
was attempted to reproduce the listeners' classification behaviour
from the acoustic data using a formal model of human classification
behaviour. To this end, several simple connectionist classification
models were trained and tested on the perceptual data. The models
used multidimensional acoustic vectors as input and produced an
output vector containing the probabilities of responding /p/,
/t/ or /k/. No phonological cues were used in the model, and the
model made no formal distinction between the various vowel contexts.
Eventually, the model that gave the best account of the perceptual
data on the basis of the acoustic cues was selected. This model
used a 5-dimensional cue space spanned by the following acoustic
cues: the length of the release burst lb, the
formant frequencies at voice onset F20 and F3n
, and the frequency F0mfp
and level L0 of a broad mid-frequency peak
just after consonantal release. The model's class boundaries were
linear functions of these 5 cues.
Upon closely studying the model's output it was found that the
"context-dependent cue weighting" found in the perceptual
data emerged from the model's classifications as well. Table 2
lists the percentages of classifications of the burst-spliced
stop-vowel stimuli in accordance with the burst, the transitions,
or the remaining class as predicted by the classification model.
Table 2. Percentage of classifications of the burst-spliced stop-vowel stimuli in accordance with the burst, the transitions, or the remaining class as predicted by the classification model.
trans |
|||
In the classifier the burst appeared to play a more important
role in determining consonant place of articulation in the vowel
contexts /i/ and /y/, than in the vowel context /a/, which we
had already observed in the perceptual data. For a comparison
see Table 1. Nevertheless the model was "fixed", i.e.
no context-dependent reweighting of cues took place in the model,
and all stimuli were treated in the same way.
An examination of the distributions of the acoustic cues in the
different contexts suggested an explanation for this phenomenon.
It appeared to be the case that the three classes /p/, /t/, and
/k/ were separated mainly on burst cues in vowel contexts /i/
and /y/, while they were mainly separated on formant cues in /a/
context. Stated differently, the acoustic between-class variability
was predominantly accounted for by burst cues in /i/ and /y/ context,
and by formant cues in /a/ context. This is illustrated in Figure
8. I have concentrated on the distributions of the most important
burst cue F0mfp and the most important
formant cue F20 for the vowel contexts /y/
and /a/. Two 2-dimensional Gaussian pdfs (one for /a/ and one
for /y/) were fitted to the acoustic vectors (F0mfp,F20)
representing all burst-spliced stimuli with a particular vowel
context. Note that this time the extra assumptions of equal variances
and zero covariances were not used. The ellipses in Figure 8 represent
the = 2 equi-probability lines of the
two-dimensional Gaussian pdfs and the solid lines are the class
boundaries. Some typical stimuli are plotted within the ellipses
(the labels representing the most probable classification by the
subject as well as the model).
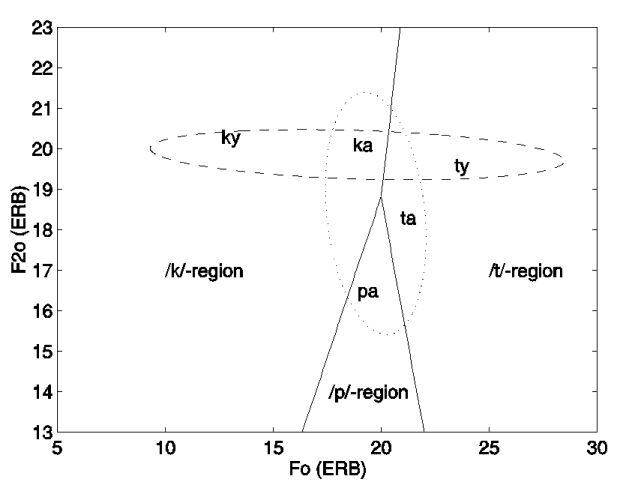
Figure 8. Two-dimensional cross-section of the 5-dimensional
cue space used in the simulation of the listeners' classification
of the burst spliced stimuli. The burst cue F0mfp
is plotted along the x-axis, the formant cue F20
is plotted along the y-axis. The "frequencies" are expressed
in ERB, units of equivalent rectangular bandwidth, which correspond
to constant distances along the basilar membrane, therefore being
a psychoacoustically more plausible unit than Hz (see Glasberg
and Moore, 1990). The ellipses represent the
= 2 equi-probability lines of the two-dimensional Gaussian pdfs
fitted on all the stimuli with /a/ context (short dashes) and
all stimuli with /y/ context (long dashes). The solid lines indicate
the class boundaries. The individual utterances plotted in the
ellipses represent typical stimuli.
The Figure clearly demonstrates that /p/, /t/, and /k/ are mainly
differentiated on the basis of the formant cue F20
in the /a/ context, because the principle axis of the Gaussian
representing the stimuli with /a/ context is almost parallel to
the F20 axis. Evidently, the values of F20
are very different for /pa/, /ta/, and /ka/, while their values
for F0mfp are similar. The reverse
holds for the Gaussian representing the stimuli in the /y/ context.
Here the values of F0mfp are very
different for /p/, /t/, and /k/, while the values for F20
are similar.
In conclusion, the experimental finding that the perceptual relevance of an acoustic cue appears to depends on the phonetic context can be reproduced by a fixed model if the between-class distribution of acoustic cues varies with vowel context. No "active"
reweighting of cues is necessary.
7. Summary and conclusions
In this paper I have proposed a general framework for research
on phonetic perception in which a pattern classifier plays a central
role. The framework is intended as a comprehensive and formal
representation of the widely adopted cue-based approach to phonetic
perception. Formulated within the information processing philosophy,
the framework consists of several interconnected information-processing
modules and storage facilities. Explicit distinctions are made
between various levels of information: acoustic, general auditory,
specific auditory, and phonological. A pattern-recognition module
plays a central role in the framework.
After the functionality of the various modules had been defined
and discussed, a number of long-standing issues rated to variability
with phonetic context were discussed from the perspective of the
framework. In this discussion a number of fresh insights and reformulations
of old problems were developed.
First of all, concerning the segmentation problem, it was concluded
that within the proposed framework this is a non-issue, because
the adopted approach is based on identifying important time instants
(acoustic landmarks) instead of acoustic segments.
Secondly, it was argued that the issues of acoustic variability
versus perceptual constancy and acoustic constancy versus perceptual
variability arise from concentrating on one-dimensional "cross-sections"
or "projections" of the more complete multidimensional
classification problem. It was argued that it is useful to formulate
the problem of phonetic perception in terms of a "dimensionality"
rather than a "variability" issue.
Next, it was argued that if phonetic categorization is viewed
as a pattern-recognition problem, the cue-trading phenomenon is
no more than a natural expression of the multidimensionality of
the pattern recogniser.
The framework allowed a more formal definition of acoustic invariance
than is so far available in the literature. It was concluded that
within the context of the framework four factors are relevant
for assessing the level of invariance associated with a particular
phonetic categorization model: the dimension of the cue space,
the length of the window associated with the specific auditory
context, the length of the window associated with the phonological
context, and the convexity of the response regions.
Finally, it was concluded that for at least some context-effects
found in the literature, active reweighting of cues by the perceptual
system is not necessary. Instead, it was argued that the observed
behaviour can be generated by a fixed pattern-recogniser when
the between-class variability changes with phonetic context.
Acknowledgements
This work was funded by a NATO-Science fellowship. Many thanks
to Louis ten Bosch and Terry Nearey for inspiring discussions
relevant to this paper.
References
Ashby, F.G. (1992) Multidimensional models of categorization.
In F.G. Ashby (Ed.), Multidimensional models of perception
and cognition. Hillsdale, NJ: Lawrence Erlbaum.
Ashby, F.G., Boynton, G., and Lee, W.W. (1994) Categorization
response time with multidimensional stimuli. Perception &
Psychophysics 55, 11-27.
Ashby, F.G., and Gott, R. (1988) Decision rules in the perception
and categorization of multidimensional stimuli. J. Exp. Psychology:
Learning, Memory and Cognition 14, 33-53.
Ashby, F.G., and Perrin, N.A. (1988) Toward a unified theory of
similarity and recognition. Psychological Review 95, 124-150.
Beckman, M.E. (1990) Theme issue on phonetic representation. J.
Phonetics 18.
Best, C. T., Morrongiello, B., and Robson, R. (1981) Perceptual
equivalence of acoustic cues in speech and nonspeech perception.
Perception & Psychophysics 29, 191-211.
Blumstein, S.E., and Stevens, K.N. (1979) Acoustic invariance
in speech production: Evidence from measurements of the spectral
characteristics of stop consonants. J. Acoust. Soc. Am. 66,
1001-1017.
Blumstein, S.E., and Stevens, K.N. (1981) Phonetic features and
acoustic invariance in speech. Cognition 10, 25-32.
Carden, G., Levitt, A., Jusczyk, P.W., and Walley, A. (1981) Evidence
for phonetic processing of cues to place of articulation: Perceived
manner affects perceived place. Perception & Psychophysics
29, 26-36.
Cooper, F.S., Delattre, P.C., Liberman, A.M., Borst, J.M., and
Gerstman, L.J. (1952) Some experiments on the perception of synthetic
speech sounds. J. Acoust. Soc. Am. 24, 597-606.
Cotton, S., and Grosjean, F. (1984) The gating paradigm: A comparison
of successive and individual presentation formats. Perception
& Psychophysics 35, 41-48.
Cowan, N. (1984) On short and long auditory stores. Psychological
Bulletin 96, 341-370.
Crowder, R.G., and Morton, J. (1969) Precategorical acoustic storage
(PAS). Perception & Psychophysics 5, 365-373.
Diehl, R.L., and Kluender, K.R. (1987) On the categorization of
speech sounds. In S. Harnad (Ed.), Categorical Perception,
Cambridge, U.K.: Cambridge University Press, 226-253.
Fant, G. (1986) Features: fiction and facts. In J.S. Perkell and
D.H. Klatt (Eds.), Invariance and variability in speech processes,
Hillsdale, NJ: Lawrence Erlbaum, 480-488.
Fischer-Jorgensen, E. (1972) Tape-cutting experiments with Danish
stop consonants in initial position. Annu. Rep. Inst. Phon.,
Univ. Copenhagen 6, 104-168.
Forrest, K., Weismer, G., Milenkovic, P., Dougall, R.N. (1988)
Statistical analysis of word-initial voiceless obstruents: Preliminary
data. J. Acoust. Soc. Am. 84, 115-123.
Fowler, C.A. (1984) Segmentation of coarticulated speech in perception.
Perception & Psychophysics 36, 359-368.
Fowler, C.A. (1986) An event approach to the study of speech perception
from a direct-realist approach. J. Phonetics 14, 3-28.
Glasberg, B.R., and Moore, B.C.J. (1990) Derivation of auditory
filter shapes from notched-noise data. Hearing Research 47,
103-138.
Hoffman, H.S. (1958) Study of some cues in the perception of the
voiced stop consonants. J. Acoust. Soc. Am. 30, 1035-1041.
Jongman, A., and Miller, J.D. (1991) Method for the location of
burst-onset spectra in the auditory-perceptual space: A study
of place of articulation in voiceless stop consonants. J. Acoust.
Soc. Am. 89, 867-873.
Klatt, D.H. (1989) Review of selected models of speech perception.
In W. Marslen-Wilson (Ed.), Lexical representation and process,
Cambridge, MA: MIT Press, 169-226.
Kuhl, P.K. (1991) Human adults and human infants show a "perceptual
magnet effect" for the prototypes of speech categories, monkeys
do not. Perception & Psychophysics 50, 93-107.
Liberman, A.M., Cooper, F.S., Shankweiler, D.P., and Studdert-Kennedy,
M. (1967) Perception of the speech code. Psychological Review
74, 431-461.
Liberman, A.M., Delattre, P.C., Cooper, F.S., and Gerstman, L.J.
(1954) The role of consonant-vowel transitions in the perception
of the stop and nasal consonants. Psychological Monographs
68, 1-13.
Liberman, A.M., Harris, K.S., Hoffman, H.S., and Griffith, B.C.
(1957) The discrimination of speech sounds within and across phoneme
boundaries. J. Exp. Psychology 54, 358-368.
Liberman, A.M., and Mattingly, I.G. (1985) The motor theory of
speech perception revised. Cognition 21, 1-36.
Lindblom, B. (1986) On the origin and purpose of discreteness
and invariance in sound patterns. In J.S. Perkell and D.H. Klatt
(Eds.), Invariance and variability in speech processes,
Hillsdale, NJ: Lawrence Erlbaum, 493-510.
Lisker, L. (1975) Is it VOT or a first-formant transition? J.
Acoust. Soc. Am. 57, 1547-1551.
Lisker, L. (1978) Rapid vs. rabid: A catalogue of acoustic features
that may cue the distinction. Haskins Laboratories Status
Report on Speech Research SR-54, 127-132.
Liu, S.A. (1995) Landmark detection in distinctive feature-based
speech recognition. PhD-thesis Dept. Electr. Eng. and Comp.
Sci., M.I.T., Cambridge MA.
Luce, R.D. (1963) Detection and recognition. In R.D. Luce, R.R.
Bush, and S.E. Galanter (Eds.), Handbook of mathematical psychology,
vol. 1, New York: Wiley.
Macmillan, N.A., and Creelman, C.D. (1991) Detection theory:
A user's guide. Cambridge, U.K.: Cambridge University Press.
Mann, V.A. (1980) Influence of preceding liquid on stop-consonant
perception. Perception & Psychophysics 28, 407-412.
Mann, V.A., and Repp, B.H. (1980) Influence of vocalic context
on perception of the sh-s distinction. Perception & Psychophysics
28, 213-228.
Mann, V.A., and Repp, B.H. (1981) Influence of preceding fricative
on stop consonant perception. J. Acoust. Soc. Am. 69, 548-558.
Marslen-Wilson, W. (1989) Lexical representation and process.
Cambridge, MA: MIT Press.
Massaro, D.W. (1987) Speech perception by ear and eye: A paradigm
for psychological inquiry. Hillsdale, NJ: Erlbaum.
Massaro, D.W., and Cohen, M.M. (1983) Phonological context in speech perception.
Perception & Psychophysics 34, 338-348
Massaro, D.W., and Oden, G.C. (1980) Evaluation and integration
of acoustic features in speech perception. J. Acoust. Soc.
Am. 67, 996-1013.
Medin, D.L., and Barsalou, L.W. (1987) Categorization processes
and categorical perception. In S. Harnad (Ed.), Categorical
Perception, Cambridge, U.K.: Cambridge University Press, 455-490.
Nearey, T.M. (1990) The segment as a unit of speech perception.
J. Phonetics 18, 347-373.
Nearey, T.M. (1991) Perception: Automatic and cognitive processes.
Proc. 12th Int. Congress of Phonetic Sciences, Vol. I,
40-49.
Nearey, T.M. (1992) Context effects in a double-weak theory of speech perception.
Language and Speech 35, 153-171.
Nosofsky, R.M. (1986) Attention, similarity, and the identification-categorization
relationship. J. Exp. Psychology: General 115, 39-57.
Nygaard, L.N., and Pisoni, D.B. (1995) Speech perception: New
directions in research and theory. In J.L. Miller and P.D. Eimas
(Eds.), Handbook of perception and cognition, Vol. II, Speech,
Language and Communication. New York: Academic Press, 63-96.
Oden, G.C., and Massaro, D.W. (1978) Integration of featural information
in speech perception. Psychological Review 85, 172-191.
Ohala, J.J., and Feder, D. (1994) Listeners' normalization of
vowel quality is influenced by 'restored' consonantal context.
Phonetica 51, 111-118.
Ohde, R.N., and Stevens, K.N. (1983) Effect of burst amplitude
on the perception of stop consonant place of articulation. J.
Acoust. Soc. Am. 74, 706-714.
Parker, E.M., Diehl, R.L., and Kluender, K.R. (1986) Trading relations
in speech and nonspeech. Perception & Psychophysics 39,
129-142.
Pisoni, D.B. (1992) Some comments on invariance, variability and
perceptual normalization in speech perception. Proc. Int. Conf.
on Spoken Language Processing, 587-590.
Pisoni, D.B., and Luce, P.A. (1987) Trading relations, acoustic
cue integration, and context effects in speech perception. In
M. Schouten (Ed.) The psychophysics of speech perception.
Dordrecht, Martinus Nijhoff Publishers, 155-172.
Pisoni, D.B., and Sawusch, J.R. (1975) Some stages of processing
in speech perception. In A. Cohen and S. Nooteboom (Eds.), Structure
and process in speech perception. Berlin: Springer Verlag,
16-34.
Repp, B.H. (1978) Perceptual integration and differentiation of
spectral cues for intervocalic stop consonants. Perception
& Psychophysics 24, 471-485.
Repp, B.H. (1980) Accessing phonetic information during perceptual integration of
temporally distributed cues. J. Phonetics 8, 185-194.
Repp, B.H. (1981) On levels of description in speech research.
J. Acoust. Soc. Am. 69, 1462-1464.
Repp, B.H. (1982) Phonetic trading relations and context effects:
New experimental evidence for a speech mode of perception. Psychological
Bulletin 92, 81-110.
Repp, B.H. (1983) Trading relations among acoustic cues in speech
perception: Speech-specific but not special. Haskins Laboratories
Status Report on Speech Research SR-76, 129-132.
Repp, B.H. (1988) Integration and segregation in speech perception.
Language and Speech 31, 239-271.
Repp, B.H., Liberman, A.M., Eccardt, T., and Pesetsky, D. (1978)
Perceptual integration of acoustic cues for stop, fricative and
affricate manner. J. Exp. Psychology: Human Perception and
Performance 4, 621-637.
Rosch, E. (1973) Natural categories. Cognitive Psychology 4,
328-350.
Samuel, A.G. (1982) Phonetic prototypes. Perception & Psychophysics
31, 307-314.
Sawusch, J.R. (1986) Auditory and phonetic coding of speech. In
E.C. Schwab and H.C. Nusbaum (Eds.), Pattern recognition by
humans and machines: Volume I, Speech perception. Orlando:
Academic Press, 51-88.
Sawusch, J.R., and Gagnon (1995) Auditory coding, cues, and coherence
in phonetic perception. J. Exp. Psychology: Human Perception
and Performance 21, 635-652.
Schatz, C.D. (1954) The role of context in the perception of stops.
Language 30, 47-56.
Shepard, R.N. (1958) Stimulus and response generalization: tests
of a model relating generalization to distance in psychological
space. J. Exp. Psychology 55, 509-523.
Smits, R. and Ten Bosch, L. (submitted) The perceptron as a model
of human categorization behavior. Submitted to J. Math. Psychology.
Smits, R., Ten Bosch, L., and Collier, R. (in press a) Evaluation
of various sets of acoustical cues for the perception of prevocalic
stop consonants: I Perception experiment. Accepted for J. Acoust.
Soc. Am.
Smits, R., Ten Bosch, L., and Collier, R. (in press b) Evaluation
of various sets of acoustical cues for the perception of prevocalic
stop consonants: II. Modeling and evaluation. Accepted for J.
Acoust. Soc. Am.
Stevens, K.N. (1985) Evidence for the role of acoustic boundaries
in the perception of speech sounds. In V.E. Fromkin (Ed.), Phonetic
linguistics - Essays in honor of Peter Ladefoged. Orlando,
Florida: Academic Press, 243-255.
Stevens, K.N. (1995) Applying phonetic knowledge to lexical access.
Proc. Eurospeech 95, vol.1, 3-11.
Stevens, K.N., and Blumstein, S.E. (1981) The search for invariant
acoustic correlates of phonetic features. In P.D. Eimas and J.L.
Miller (Eds.), Perspectives on the study of speech, Hillsdale
NJ: Lawrence Erlbaum, 1-39.
Summerfield, A.Q., and Haggard, M.P. (1974) Perceptual processing
of multiple cues and contexts: Effects of following vowel upon
stop consonant voicing. J. Phonetics 2, 279-295.
Suomi, K. (1985) The vowel dependence of gross spectral cues to
place of articulation of stop consonants in CV syllables. J.
Phonetics 13, 267-285.
Sussman, H.M., McCaffrey, H.A. and Matthews, S.A. (1991) An investigation
of locus equations as a source of relational invariance for stop
place of articulation. J. Acoust. Soc. Am. 90, 1309-1325.
Whalen, D.H. (1989) Vowel and consonant judgments are not independent when cued by the same information. Perception & Psychophysics 46, 284-292.
 Back to SHL 9 Contents
Back to SHL 9 Contents
 Back to Phonetics and Linguistics Home Page
Back to Phonetics and Linguistics Home Page
