
This paper will cover four areas:
1. The function of the SiVo-3 device.
2. Fitting of SiVo-3.
3. Signal processing strategies of SiVo-3.
4. The field trials of SiVo-3 and some preliminary results.
2. Function of the Device
SiVo-3 is a digital processing hearing aid. The real-time software
can be programmed onto the device via its interface with a PC.
The function of the device depends on the real-time code stored
on it. The current real-time software for the SiVo-3 device has
combined both the speech-analytic hearing aid function and the
conventional amplifying hearing aid function. They are chosen
by the positions of two front-panel switches "switch between
modes" and "multi-purpose switch" of the device
as shown in Figure 1:
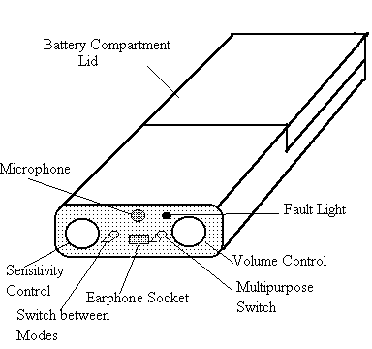
Table 1: The functions of the two front panel switches.
between Modes (Left Switch) |
Switch (Right Switch) |
|
up/middle up/middle down down |
middle down up/down middle |
SiVo 3, mapitch (pitch shifted down by) 50 Hz SiVo 3, mapitch 80 Hz conventional hearing aid, normal operation conventional hearing aid, 1kHz 18dB/octave highpass filtered |
2.1 Speech-Analytic Mode
In the speech-analytic mode, the device provides speech
fundamental frequency, amplitude and voiceless frication information
extracted from speech. The voice fundamental frequency information
is presented as a sinusoid following the voice pitch. The voiceless
frication is detected when there is a voiceless fricative/affricate
sound such as 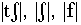 and
and 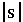 .
It also detects the strong plosive sounds
.
It also detects the strong plosive sounds
 and
and 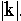 This information is presented as a low frequency
noise within 2000 Hz. The spectrum of the noise is shaped by
a filter matching the patient's most comfortable level (MCL) between
125 and 2000 Hz. The speech amplitude envelope is used to amplitude-modulate
both the sinusoid and the low frequency noise. The output level
of the sound is guaranteed to be within the patient's dynamic
range. It is possible to switch off the fundamental frequency
or frication sound separately by changing the position of a rotary
switch on the processor circuit board. The rotary switch has
16 positions marked 0 - F.
This information is presented as a low frequency
noise within 2000 Hz. The spectrum of the noise is shaped by
a filter matching the patient's most comfortable level (MCL) between
125 and 2000 Hz. The speech amplitude envelope is used to amplitude-modulate
both the sinusoid and the low frequency noise. The output level
of the sound is guaranteed to be within the patient's dynamic
range. It is possible to switch off the fundamental frequency
or frication sound separately by changing the position of a rotary
switch on the processor circuit board. The rotary switch has
16 positions marked 0 - F.
|
| |
frication sound switched off. |
The voice fundamental frequency can be shifted down by 50 Hz or 80 Hz if needed. This is useful for patients who have problems hearing a female or child's voice. This function is determined by the position of the multipurpose switch, as summarised in Table 1.
2.2 Conventional Amplifying Mode
In the conventional amplifying mode, the hearing aid acts
like an amplifier. The specification for this mode was provided
by Oticon A/S. The maximum output level can reach 148 dB SPL.
A highpass filter with 1 kHz/octave low frequency cut designed
to reduce low frequency noise can be switched on and off by changing
the position of the multi-purpose switch as shown in Table 1.
The insertion gain for each frequency is set from thresholds
measured by the setting-up software according to the POGO fitting
rule (McCandless & Lyregaard, 1983). A filter that matches
the patient's insertion gain across the 2000 Hz frequency band
is applied to the input signal. An earphone compensation filter
is also applied to flatten the frequency response peaks caused
by resonance in the earphone.
3. Fitting the SiVo-3 Device
One of the important features of the SiVo-3 device is that it
can store the patient's audiogram data (the threshold level, comfortable
level, and the discomfort level across different frequencies)
and the matching filter's parameters via its set-up software SiVoSet1
and the device's PC interface. Therefore the SiVo-3 device can
be tailored for each individual patient. The real-time code guarantees
that the output signal of the hearing aid matches the specified
data of the patient.
In the speech-analytic mode, the output level of the sinusoid is limited within the specified dynamic range of the patient at each measured frequency specified by SiVoSet. The level of the low frequency noise output representing voiceless frication is also limited by the measured threshold and discomfort level for the same noise.
In the conventional amplifying mode, a filter is selected to provide the frequency-gain characteristic required by the POGO fitting rule. The filter parameters are loaded onto the SiVo-3 device. The average discomfort hearing level is also specified and stored onto the device to limit the maximum output level.
4. Speech Signal Processing Strategies for the SiVo-3 Hearing Aid
4.1 The Conventional Amplifying Mode
The speech signal processing task in the conventional amplifying
mode is relatively simple compared with the speech pattern extraction
algorithms employed in the speech-analytic mode of the SiVo-3
device.
The sampling rate of the device in the conventional mode is 4 kHz. The information above 2 kHz is cut off. An LED light on the front panel will be flash if the level of the input signal to the A/D converter is too high. When the multi-purpose switch is at the middle position, a 1 kHz 18dB/octave high-pass filter is applied to the sampled signal. An FIR matching filter that matches the required POGO gains with its parameters specified by the SiVoSet software is applied. After filtering, the positive and negative peaks are limited to ensure the output signal doesn't exceed the averaged discomfort hearing level. The final stage is to apply an earphone compensation filter to flatten the frequency response peaks caused by resonance in the earphone.
4.2 Speech-analytic Pattern Extraction
In the speech-analytic mode of the SiVo-3, the device's sampling
rate is 16 kHz. The voice fundamental frequency/period and voiceless
frication information are extracted from speech. The performance
of these pattern extractors directly affects the overall effectiveness
of the hearing aid. The most important issue is then how to
develop robust and fast algorithms for extracting these speech
patterns.
4.2.1 Real-Time Voice Fundamental Frequency Extraction
Algorithm
The voice fundamental frequency extractor consists of three parts:
1) a pre-processor.
2) a main extractor.
3) a post-processor.
The pre-processor is a 4th order low-pass filter with cut-off frequency at 800 Hz. The input signal to the pre-processor is sampled at 8 kHz. The output from the pre-processor is down-sampled at 2 kHz before it feeds into the main fundamental frequency extractor.
The main fundamental frequency extractor is a multi-layer perceptron pattern classifier (Rumelhart & McClelland, 1988). Pattern classification is the process by which the input vectors are classified into significantly different categories. The system that performs this function is called a pattern classifier. Neural network models are specified by three elements: 1) Net topology; 2) Node characteristics; and 3) Training and learning rules. The nonlinearity used within nodes is one important factor in the capabilities of the neural network models. In supervised training, the neural nets are provided with information or labelling that specifies the correct class for new input patterns during training. Multi-layer perceptrons (MLP) are "feed forward" nets with one or more hidden layers between the input and output nodes.
The MLP fundamental period extractor for the SiVo-3 device as shown in Figure 2 consists of four layers: an input layer, two hidden layers and an output layer. The input layer has 61 nodes, the first hidden layer 20 nodes, the second hidden layer 6 nodes, and the output layer one node. Each layer is fully-connected with the adjacent layer(s).
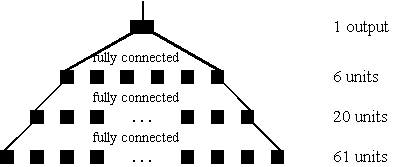
Figure 2: Real-Time MLP Fundamental Period Extractor.
The training data for the MLP algorithm were recorded in a non-acoustically treated room at UCL, with a 50 cm speaker to microphone spacing. They contain two signal channels (speech and Laryngograph). Eight speakers (four male and four female) were asked to read two passages "Arthur the Rat" and "The Rainbow Passage". A speech spectrum shaped noise was added to part of the training data with various SNR (speech max rms over 500 ms window / noise rms) at 20 dB, 15 dB, and 10 dB. Then the mixed training data were attenuated by 0 dB, 6 dB, and 12 dB, in order to present different signal levels to the MLP classifier so that the classifier would be less sensitive to the input signal level.
The target data is a normalised and half-wave rectified Laryngograph signal (Lx).
The MLP training is accomplished by sequentially applying input
vectors, while adjusting network weights according to a predetermined
learning procedure. During training, the network weights gradually
converge to values such that each input vector produces the desired
output vector. Supervised training requires the pairing of each
input vector with a target vector representing the desired target
output. The success of the training depends not only on the structure
of the MLP, but also on the accuracy of the target values used
in the training. Figure 3 displays a sample of speech waveform,
the input and output of the MLP extractor and the target data.
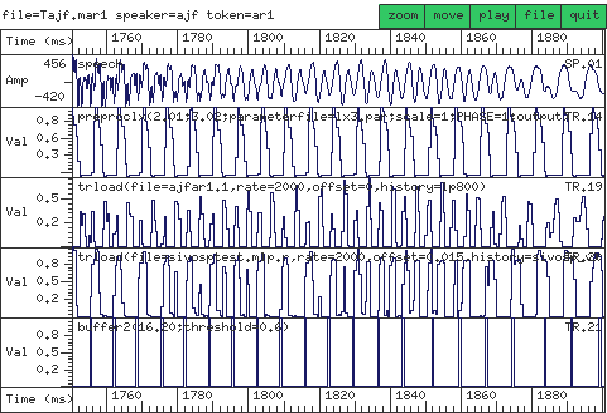
Figure 3:
(1) Speech waveform.
(2) MLP target data: normalised and half-wave rectified Lx signal.
(3) MLP input data.
(4) MLP output data.
(5) output from the post-processor.
After the MLP model was trained on the UNIX machine, a set of weights were obtained which were scaled in order to be loaded onto the SiVo 3 hardware.
The post-processing stage converts the output from the basic extractor into a desirable format for generating the sinusoid output on the SiVo-3 and also performs error correction and smoothing of the raw estimates from the main extractor.
In the SiVo-2 device, the sinusoid generator repeated the previous sinusoid cycle if it had not received a new fundamental period value at the time when the previous sinusoid cycle has finished. This problem has now been overcome on the SiVo-3 by introducing a buffer in the post-processor, which is 20.5 ms in length (i.e. it holds 41 MLP output values), as shown in Figure 4:
.
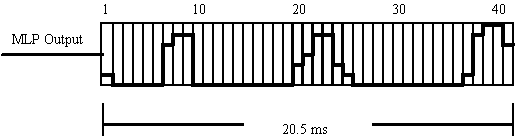
Figure 4: Buffer Post-Processor.
The MLP fundamental frequency extractor and the buffer processor introduce 35 ms delay in total between the input and output signals of the SiVo. However, studies using normal listeners have shown that if the time delay of the acoustical signal is within 40 ms, it will not affect performance in aided lipreading. (McGrath & Summerfield, 1985).
The MLP fundamental period extractor was compared with other algorithms such as peak-picker(Howard & Fourcin, 1983), Gold-Rabiner method (Gold & Rabiner, 1967), Cepstral analysis (Noll, 1967), the SIFT algorithm and Sub-harmonic Summation method (Hermes, 1988). It performed better in noisy conditions than the other methods (Wei et al, 1993b).
4.2.2 Real-Time Voiceless Frication Detector
The SiVo 3 hardware samples the input speech at a much wider sampling
frequency range than the SiVo 2 device. This enables the real-time
implementation of the frication detection algorithm since they
were initially developed on the SUN SPARC station at UCL using
16 kHz sampling rate. The real-time frication detection algorithm
currently implemented on SiVo 3 is a spectral-balance algorithm
shown in Figure 5.
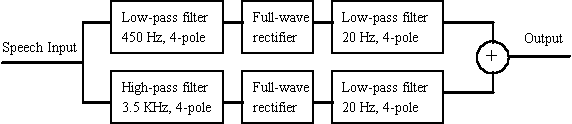
Figure 5: Spectral-Balance Frication Detection Algorithm.
When the frication information is detected using the spectral-balance algorithm, it is important to encode the information in an appropriate way in order to match individual patient's residual hearing ability. At present, the noise is software-generated using an on-line noise generator. The spectrum of the noise is determined by the patient's matching filter specified by the SiVoSet software. The level of the noise is also determined by the SiVoSet measurement of the patient's dynamic range for this noise.
If the voice fundamental period extractor has detected a fundamental period, the output of the frication detector is ignored.
5. Field trials of the SiVo-3 device
The SiVo-3 device is currently being tested in field trials as
part of the OSCAR project: an EC funded TIDE (Technical Initiatives
for the Disabled and Elderly) project. This involves partners
in France, the Netherlands, Sweden, and the UK and field trials
are and will be taking place in each of these four countries.
The aims of the field trials are as follows:
1. Investigate the value of a dual-mode aid which is designed for both general use and face-to-face communication.
2. Examine the added benefit of speech analytic processing over and above conventional amplification.
3. Compare unimodal and bimodal (i.e. both auditory and tactile) stimulation.
4. To investigate how well the speech analytic processing method performs in noise during audio visual consonant identification tests and sentence identification tests. Previous research in the STRIDE project (Faulkner, 1994, 1996) gave good results for SiVo II in noise in similar tests. It is hoped that SiVo-3 will give better results because of the post-processing buffer now present.
There will be two phases of the field trials. Aims 1 and 2 will be looked at during the first phase and this is currently underway. The third aim will be investigated during the second phase and the fourth aim throughout the trials.
The basic outline of the first phase of the field trials is shown below.
Table 2: Outline of the first phase of the field trials
| 1 month | 3 months | 1 month |
| Pretraining assessments | Training in both the conventional and analytic modes and home use of the aid - a minimum of 6 sessions | Posttraining assessments |
5.1 Pretraining Assessments
Both speech perception and speech production are assessed. During
the pretraining assessment, each subject is assessed in 4 conditions:
a) No hearing aid.
b) Own hearing aid.
c) Analytic mode of SiVo-3.
d) Conventional mode of SiVo-3.
The speech perception tests are as follows:
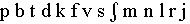 . The lists are presented twice in each condition.
. The lists are presented twice in each condition.
Speech production changes are also measured. Recordings are made
during the pretraining and posttraining assessments and also half
way through the training period. The subject is recorded producing
a sustained vowel on a level tone, reading a short passage and
reading a word list.
5.2 Selection Criteria for Subjects
Subjects are selected according to the following criteria:
6. Preliminary results
At the time of writing, only results from the pretraining assessments
carried out in the UK are available. These are from four subjects
selected according to the above criteria. Table 3 shows these
results.
More detailed results from the vCv identification test using SINFA analysis are shown in Table 4. No analysis of frication has been done yet.
The speech production results are as yet unanalysed.
As each subject's results are so different, they will be considered
separately.
Table 3: Preliminary results from UK subjects - pretraining
speech perception tests
| Patient | Hearing device | VCVs % overall corr. | She should try. % corr. | We all know. % corr. | BKB sentences % |
| BH | Anal. mode | 70.25 | 97.5 | 71.4 | T=64 L=66 |
| Conv. mode | 65.5 | 50.0 | 35.7 | T=68 L=71 | |
| Own aid | 58.5 | 57.1 | 35.7 | T=43 L=49 | |
| No aid | 37.0 | _________ | _________ | T=36 L=39 | |
| IK | Anal. mode | 44.0 | 19.0 | 42.9 | T=19 L=32 |
| Conv. mode | 52.4 | 33.3 | 40.5 | T=63 L=76 | |
| Own aid | 57.2 | 71.4 | 50.0 | T=63 L=80 | |
| No aid | 33.4 | _________ | _________ | T=41 L=49 | |
| PR | Anal. mode | 35.7 | 38.1 | 45.3 | T=6 L=10 |
| Conv. mode | 26.2 | 26.2 | 33.3 | T=18 L=19 | |
| Own aid | _________ | _________ | _________ | _________ | |
| No aid | 38.1 | _________ | _________ | T=4 L=5 | |
| BW | Anal. mode | 39.3 | 21.4 | 28.6 | T=37 L=41 |
| Conv. mode | 50.0 | 31.0 | 19.0 | T=48 L=52 | |
| Own aid | _________ | _________ | _________ | _________ | |
| No aid | 46.5 | _________ | _________ | T=54 L=58 |
Table 4: More detailed analyses of the vCv results
| Patient | Hearing device | Voicing % info. transfer | Place % info transfer | Manner % info transfer |
| BH | Anal. mode | 76.3 | 95.6 | 58.8 |
| Conv. mode | 57.2 | 90.0 | 43.5 | |
| Own aid | 24.2 | 87.0 | 57.0 | |
| No aid | 9.7 | 85.5 | 41.1 | |
| IK | Anal. mode | 23.2 | 79.0 | 32.9 |
| Conv. mode | 34.4 | 79.6 | 39.9 | |
| Own aid | 29.9 | 88.5 | 52.1 | |
| No aid | 4.9 | 69.8 | 30.3 | |
| PR | Anal. mode | 12.4 | 59.1 | 27.3 |
| Conv. mode | 3.8 | 52.1 | 21.9 | |
| Own aid | _________ | __________ | ___________ | |
| No aid | 19.7 | 69.0 | 28.4 | |
| BW | Anal. mode | 20.1 | 71.1 | 42.1 |
| Conv. mode | 16.9 | 71.9 | 46.6 | |
| Own aid | __________ | __________ | __________ | |
| No aid | 14.9 | 75.0 | 45.9 |
BH: This subject found the information conveyed by the analytic mode most beneficial in both the vCv identification tests and the stress placement tests. Closer examination of the vCv results (Table 4) shows more clearly that the benefits are particularly in perception of manner and most strikingly voicing information. In comparison with his own aid the voicing % information transfer scores are approximately three times better with the analytic (as opposed to just twice as good with the conventional mode). He is a good lipreader and so , although he shows an improvement in place % information transfer with the analytic mode, this is quite small because his scores are all high in this area.
The extracted elements of voice fundamental frequency and amplitude available in the analytic mode of the SiVo seem to greatly enhance BH's ability to correctly detect nuclear stress. In fact, his scores are almost twice as good in this mode compared to either the conventional mode of the SiVo or his own aid. It was apparent during the testing session that he was more relaxed when using the analytic mode.
There is little difference, in the BKB results, between those obtained with the analytic mode of the SiVo and those with the conventional mode. However, these are considerably better than the two other conditions suggesting that both modes give more information than his own aid.
IK: This subject gained better results on the vCv tests and stress placement tests with his own hearing aid. This is not uncommon at the pretraining testing stage despite subjects' apparent dislike of their own aid(s). Often, subjects have many years of experience with a particular device and have learnt to use it to the best of their ability even if this is not satisfactory. Therefore, when they switch to a new aid the sound is unfamiliar and the subject has to learn to use the new information presented to them. In IK's case he has been wearing his current aid in his left ear for 2 years.
Comparison of the two modes of the SiVo reveals interesting results. When IK was first fitted with the SiVo he reported that he did not like the analytic mode at all. This subjective judgement is very much reflected in his results. His scores are considerably higher with the conventional mode, particularly in the voiceless stress placement tests and the BKB sentence tests.
PR: This subject has no hearing aid of her own and has not worn aids for 30 years. Table 3 shows that at present she is not able to make use of the extra information presented in either mode of the SiVo to help her in the identification of consonants. In fact, her vCv results are better when she is using no aid at all. This is true even for the amount of voicing she is able to detect. It could be that following 30 years of no auditory stimulation she finds any sounds she hears confusing. It is felt that with sufficient training she could learn to interpret the new auditory cues.
This hope is not unfounded as the results for the stress placement tests are approximately 12% higher with the analytic mode than the conventional mode of the SiVo. This suggests that she is making some use of the voice fundamental frequency and amplitude cues delivered through the analytic mode, even though it shows a small effect at present.
Her BKB results are best with the conventional mode of the SiVo. However, these are still very low and so it is not possible to draw any conclusions from these results.
BW: This subject has not worn hearing aids for 7 years. Table 3 shows that BW is best able to identify consonants with the conventional mode. A breakdown of the vCv results in Table 4, however, shows that she gains slightly more voicing information with the analytic mode. This is to be expected with the cues presented.
Her stress placement results are low in both modes and are inconclusive. She found this particular set of tests very difficult.
Her BKB results show a slight improvement from the analytic mode to the conventional mode and then to unaided. As with subject PR it is possible that the addition of auditory cues has actually detracted from BW's ability to lipread. Again, it is felt that with training these extra cues will enhance BW's ability to lipread.
7. Conclusions
At this stage it is very difficult to show conclusive results.
In fact, the purpose of the pretraining tests is to provide a
basis for comparison with later tests once a program of training
has been completed. However, it is possible to see a few interesting
trends emerging. One such trend is that 3 out of the 4 subjects
gain more voicing information with the analytic mode of the SiVo
than the conventional mode albeit still a small amount in three
of them. This increase is to be expected with the presentation
of fundamental frequency as one of the extracted elements. Another
trend shown is that all four subjects perform better on the BKB
sentence tests with the conventional mode than the analytic mode.
In fact, in three subjects' results, the conventional mode yields
the best results against all the other conditions. This could
be because the sound is more natural with the conventional mode.
8. Future Work
Following these tests, each subject will now partake in a minimum
of six sessions of training. During this time the subjects will
be trained to make the best use of the information available to
them with the analytic and conventional modes of the SiVo. Training
covers consonant identification, stress placement, sentence work
and Connected Discourse Tracking (CDT). The subjects will be asked
to keep a daily diary in which they will record the situations
they use each mode in and what sounds they can hear. From these
it will be possible to assess the benefit for the subjects of
having a dual-mode aid. When the training is completed, the subjects
will undergo more testing. This will consist of a more extended
period of the same type of tests carried out as above.
The field trials are in the early stages and still much work has to be done. However, these preliminary results are promising and suggest an encouraging outcome.
Acknowledgement
This work is supported by the European Commission's OSCAR (Optimal
Speech Communication Assistance for Residual
Abilities) project within the TIDE (Technology for Integration
of the Disabled and Elderly) program.
References
Bamford J and Wilson I (1979) Methodological considerations and
practical aspects of the BKB Sentence Lists. In Speech-Hearing
Tests and the Spoken Language of Hearing-Impaired Children
(Bench J and Bamford J eds) Academic Press, London, Toronto and
Sydney.
Faulkner A, Ball V, Rosen S, Moore BCJ and Fourcin A (1992) Speech pattern hearing aids for the profoundly hearing-impaired: Speech perception and auditory abilities. J. Acoust. Soc. Am., 91, 2136-2155.
Faulkner A (on behalf of the STRIDE consortium) (1994) The STRIDE project, in Speech, Hearing and Language: work in progress, Department of Phonetics and Linguistics, University College London, 8, p 163-179.
Faulkner A (on behalf of the OSCAR consortium) (1996) The TIDE project OSCAR. PROC. ISAC-96.
Gold B and Rabiner L (1969) Parallel processing techniques for estimating pitch periods in the time domain. J. Acoust. Soc. Am., 46, 442-448.
Hermes D. J. (1988) Measurement of pitch by subharmonic summation, J. Acoust. Soc. Am., 83, 257-264.
Howard D.M. and Fourcin A. (1983) Instantaneous voice period measurement for cochlear stimulation" Electronics Letters, 19, 776-778.
Markel J.D. (1972) The SIFT algorithm for fundamental frequency estimation, IEEE Trans. AU-20, 367-377.
McCandless G. and Lyregaard P.E. (1983) Prescription of gain/output (POGO) for hearing aids, Hearing Instruments, 34(1), 16-21.
McGrath M and Summerfield Q (1985) Intermodal-timing relations and audio-visual speech recognition by normal-hearing adults", J. Acoust. Soc. Am., 77, 678-685.
Miller G. A. and Nicely P.E. (1955) An analysis of perceptual confusions among some English consonants, J. Acoust. Soc. Am., 27, 338-352.
Noll A. M. (1967) Cepstrum pitch determination, J. Acoust. Soc. Am., 41, 293-309.
Rosen S., Moore B.C.J. and Fourcin A (1979) Lipreading connected discourse with fundamental frequency information. British Society of Audiology Newsletter, Summer Issue, 42-43.
Rumelhart D, McClelland J and the PDP Research Group (1988) Parallel Distributed Processing, The MIT Press, Cambridge, Massachusetts.
Wei J (1993a) A speech pattern processing method for Chinese listeners with profound hearing loss, Ph.D thesis, University of London.
Wei J , Howells D, Fourcin A, and Faulkner A (1993b) Larynx period and frication detection methods in speech pattern hearing aids, Speech Hearing and Language, Work in Progress, Dept. of Phonetics and Linguistics, University College London, 7, 269-276.
© 1996 Jianing Wei and Kerensa Smith
 Back to SHL 9 Contents
Back to SHL 9 Contents
 Back to Phonetics and Linguistics Home Page
Back to Phonetics and Linguistics Home Page
