
SYNCHRONISING SYNTAX WITH SPEECH SIGNALS
1The work was partially supported by the Engineering and Physical Science Research Council (UK), Grant No. GR/K75033.
Introduction
In Huckvale and Fang (1996), we described PROSICE, a corpus of
spoken material specifically designed for the study of the prosody
of read English. This corpus uniquely combines high-quality signals
with a detailed set of annotations. It combines the best ideas
from a number of existing British English spoken corpora: the
anechoic recording conditions of EUROM0 (cf. Fourcin and Gibbon
1994), the balanced source texts of the London-Lund Corpus of
Spoken English (cf. Svartvik and Quirk 1979), and MARSEC aligned
with syntactic descriptions (cf. Knowles 1993, 1994, and 1995).
It also provides an accurate fundamental frequency contour generated
from a simultaneous Laryngograph signal, a set of accurate word
alignments and pause annotations from a novel automated annotation
scheme, and sufficient data from a single speaker to build statistical
models. Additionally, PROSICE contains detailed grammatical annotations,
which have been successfully aligned with the speech signal. This
paper describes these grammatical annotations and suggests how
they might be used for the analysis of English prosody.
In many areas of linguistic science, the study of prosody aims to explain how the observed realisations of an utterance relate to the underlying form the encoding problem, and how the observed realisations aid the appropriate interpretation of the utterance the decoding problem. In prosody a number of intermediate phonological components are often posited: (1) prosodic phrasing the observed breaking of utterances into groups, which appears to be strongly related to syntactic structure, (2) prosodic prominence the observed emphasis placed on certain components, which appears to be related to discourse structure, and (3) intonation the observed changes in pitch throughout an utterance, which appear to be related to discourse function. These components have much more influence in generative studies than in perceptual studies because the mapping from the physical observations to these components seems far from straightforward. In PROSICE we have considered such intermediate descriptions of prosody that straddle between the observed word sequence and the observed physical character of the signal. This means we do not model the two-stage transformation from grammatical structure to realisation. Instead, we rely on the grammatical annotations and the physical annotations alone and use a single mapping. What we aim to do is to explain the lowest level realisations as far as possible from the grammatical annotations. If the physical characteristics can be well explained this way, our approach then actually simplifies both the model itself and any technological applications of the model: in doing so, we are able to avoid the intermediate components of grouping, prominence, and intonation tunes inside the model, which do not appear as an external intermediate representation.
The necessity of combining grammatical analyses with speech modelling has been repeatedly voiced in the past fifty years. Numerous investigations have also been carried out to identify, as an example, the correlation of canonical grammatical categories and prosodic properties in speech (cf. Quirk et al 1964; Goldman-Eisler 1972; Butterworth 1980; Altenberg 1987; Stenstöm 1990; Croft MS.). However, due to the inadequacy of the basic classification of linguistically relevant properties in speech, the grammatical juncture frequently referred to in prosodic studies, as an example, has not yet been carefully defined, nor have degrees of grammatical generality been consistently and systematically distinguished (cf. Crystal 1969: 169). For example, when investigating pauses as linguistic demarcators, Stenström (1990) classifies pauses according to whether they were found between sentences, clauses, clause elements, and phrase elements. The first inadequacy lies with the fact that clause elements subsume both clauses and phrases since, for example, finite and non-finite clauses can function as subject or adverbial in the sentence. Secondly, the so-called clause elements (SVOCA, cf. Quirk et al 1985:49) are realised by the clause and the five major grammatical phrases (NP, VP, AJP, AVP, and PP). Thus identifying the number of pauses between the verb and the object does not readily lend itself to any sound or useful generalisations as variations may be observed with the subdivision of noun objects and clause objects.
It is thus desirable to annotate speech corpora with a descriptive grammar formalism that can be consistently applied to the kinds of authentic data included in the corpus. Since the analysis of phrase structures alone is known to provide an inadequate basis for the explanation of prosody, the formalism should provide a well-defined dichotomy not only for the categorical classifications of the word class, the grammatical phrase, and the clause, but also their syntactic functions such as subject, verb, and complement. We are aware of other grammatically annotated speech databases. We are also aware, however, that these databases are annotated at a fairly rudimentary level. MARSEC, for instance, is only analysed for phrase information. Our emphasis has thus been to create a set of sophisticated grammatical annotations, which, for example, include explicit indications about the syntactic function of a particular phrase. From this type of detailed analyses, we hope, a more reasoned attempt at the prediction of prosodic phrasing may be made.
We describe in this article such a descriptive grammar formalism whereby PROSICE is analysed. It is a formalism that describes lexical, phrasal, and clausal structures of English and specifies their syntactic functions. It has been empirically tested and duly modified through its application in the mega-word British component of the International Corpus of English (ICE-GB, cf Greenbaum 1988 and 1992) and has been computationally implemented into a fully automatic wordclass tagger and syntactic parser (cf. Fang 1996a, 1996b, and 1996c).
The grammar formalism
The grammar formalism, which includes both wordclass tagging and
syntactic parsing schemes, was initially designed by the TOSCA
research group at Nijmegen University, the Netherlands (cf. Oostdijk
1995 and Aarts et al 1996). It was subsequently adopted by the
Survey of English Usage, University College London, for the ICE-GB
Corpus. In the course of tagging and parsing the corpus, this
formalism was substantially modified for both its terminologies
and analyses. In this paper, we refer to it as the ICE annotation
system, whose wordclass and syntactic components are referred
to as the tagging and the parsing schemes.
Unlike many other grammar formalisms, the ICE annotation system has two closely related but strictly separated systems: form and function. The form describes the internal structure of either a particular word or a phrase (e.g. noun phrase and verb phrase). The function specifies the syntactic roles (e.g. subject, verb, and object) of the formal categories. For a detailed discussion, see Quirk et al (1985: 48ff).
1. Formal categories
1.1 The ICE tagging scheme
The wordclass annotation scheme recognises the following:
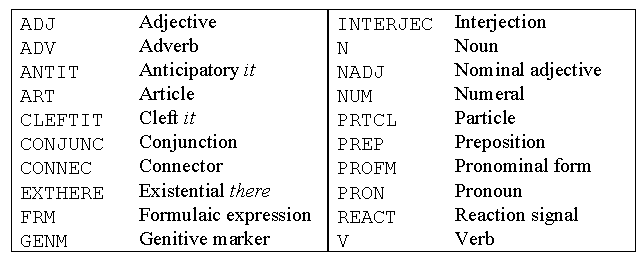
Table 1: ICE wordclass tags
As is immediately noticeable, all the major English word classes are covered and information given about their subcategorisation and form in context. Certain lexical items are analysed for their communicative, semantic, and pragmatic functions. The processing of spoken data made it necessary to introduce special tags for formulaic expressions, such as greetings and expletions, and reaction signals. Adverbs are subcategorised for their semantic roles and duely analysed according to context as intensifiers, particularisers, etc. The connector, as another example, can be subdivided into appositive
[1] The human species is intelligent in its own ways (for example - the use of language for verbal and written communication) and comparatively stupid in others.
and general
[2] Finally, the candidates were criticised for 'woolly answers'.
[3] There are, however, a couple of obstacles to be overcome first.
The scheme also treats some special items that involve a different phrasal, clausal, and even sentential analysis:
Phrasal features: PREP(phras), ADV(phras), etc.
[4] Thus the dogs' behaviour had been changed because they associated
the bell with the food.
[5] I had been filming The Paras at the time, and Brian had had to come down to Wales with the records.
Clausal features: PROFM(so), PRTCL(with), etc.
[6] Similarly, the society that Oedipa Maas is living in has isolated
itself, so too has the world in which Tom Jones inhabits.
[7] The number by the arrows represents the order of the pathway causing emotion, with the cortex lastly having the emotion.
Sentential features: EXTHERE, PRON(cleftit), PRON(antit), etc.
[8] There were two reasons for the secrecy.
[9] It is from this point onwards that Roman Britain ceases to exist and the history of sub-Roman Britain begins.
[10] Before trying to answer the question it is worthwhile highlighting briefly some of the differences between current historians.
Because of their central role in the subsequent parsing, verbs receive especially detailed treatment in term of their subcategorisation. The verb class is first of all divided into auxiliaries and lexical verbs. The auxiliary class notes modals, perfect, passive and semi-auxiliaries. The lexical verbs are further annotated according to different complementations. There are altogether seven transitivity types: complex transitive, copular, dimonotransitive, ditransitive, intransitive, monotransitive, and trans.
Syntactically, these types can be represented as:
complex transitive (V + Direct Object + Object Complement)
[11] If television was going to be bloody-minded, radio would
keep me busy.
copular (V + Subject Complement)
[12] Of all my broadcasting, the Monday morning spot was
perhaps the best fun.
dimonotransitive (V + Indirect Object)
[13] The pen though, as Shakespeare will tell you is more
Mighty than the sword.
ditransitive (V + Indirect Object + Direct Object)
[14] His parents were then recommended to stop comforting him
as they were giving him positive reinforcement for undesirable
behaviour.
intransitive (V)
[15] As an actor, I had appeared in innumerable schools
broadcasts, in Saturday Night Theatre and in The Dales.
monotransitive (V + Direct Object)
[16] The programme had a biggish audience (in radio terms)
because it followed the Today programme, and because people
listened to it in their cars on the way to work.
trans (V + Clause, V + Direct Object + Object Complement)
[17] Just before Christmas, the producer of Going Places, Irene
Mallis, had asked me to make a documentary on 'warm-up
men'.
[18] They make others feel guilty and isolate them.
[19] I can buy batteries for the tape - but I can see myself spending a fortune!
[20] The person who booked me in had his eyebrows shaved and replaced by straight black painted lines and he had earrings, not only in his ears but through his nose and lip!
The notation trans here is used in the ICE project to tag transitive verbs followed by a noun phrase that may be the subject of the following nonfinite clause. They are so tagged in order to avoid making a decision on their transitivity types (cf. Greenbaum, 1993). In examples [17]-[20], asked, make, and had are all complemented by non-finite clauses with overt subjects, the main verbs of these non-finite clauses being infinitive, present participle and past participle.
1.2 The ICE parsing scheme
Five phrases are analysed for their boundaries and internal structures:
noun phrase (NP), verb phrase (VP), adjective phrase (AJP), adverb
phrase (AVP), and prepositional phrase (PP). While AJP and AVP
are relatively simple and will not be described here, this section
aims at providing a general framework for the treatment of NP
and VP. PP can be conveniently termed as the combination of a
head preposition and its tail, the complement NP or clause.
1.2.1 The noun phrase (NP)
NP is used here in a restricted sense, i.e., it terminates at
the head while excluding the various types of post-modification.
A full NP comprises a determiner group (DT), premodifier (NPPR),
and the head (NPHD). The determiner group consists of pre-determiners
(DTPE), a central determiner (DTCE), and post-determiners (DTPS).
The premodifier is mainly realised by adjective phrases. The noun
phrase head is usually a noun, a pronoun, a nominal adjective,
or a numeral. Figure 2 shows the schema of a noun phrase.
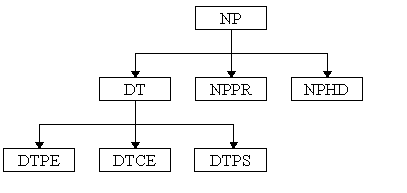
Figure 1: The NP schema
Consider
[21] The functions that can be controlled from the keypad naturally include brightness, contrast, channel selection, volume, and all the other everyday items.
The underlined NP in [16] exemplifies the schema in Figure 2, which has a pre-determiner (all), a central determiner (the), a post-determiner (other), and a premodifier (everyday). The analysis yields a derived syntactic tree in Figure 2.
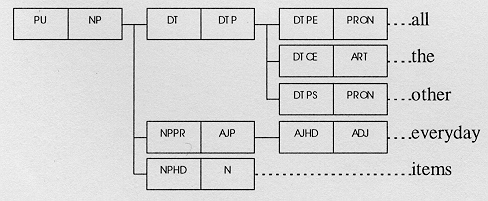
Figure 2: NP structure for [16]
1.2.2 The verb phrase (VP)
A full VP has two immediate constituents: the auxiliary group
and the main verb (MVB). While the main verb is invariably associated
with atomic or terminal symbols-for instance V(cop), V(intr),
or V(montr)-the auxiliary group very often consists of a collection
of modals, semi-auxiliaries, and catenative verbs. Thus, when
there are more than one terminal symbol in the auxiliary group,
the first is analysed as the operator (op) and the rest as the
auxiliary verb (AVB). This analysis of VP thus yields a structure
illustrated by Figure 3.
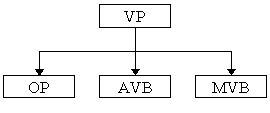
Figure 3: The schema of VP
Example [22] provides an example that contains a VP with both an OP and an AVB. A slight complication is the intruding AVP, which is duly analysed as an adverbial.
[22] But the restaurant was so posh we just couldn't possibly have considered it.
An analysed VP is coupled with one feature describing its transitivity if it is finite, and an additional feature to indicate its form if it is non-finite. The transitivity of VPs is inherited from the main verb except in a passivised construction. The change of transitivity of a passivised VP is necessary to indicate the altered complementation. For instance, found in [23a] is complemented by the following NP while in [23b] it is no longer complemented, despite the fact that this verb is tagged as monotransitive in both examples.
[23a] Someone found the book.
[23b] The book was found.
| complex transitive | copular | |
| dimonotransitive | intransitive | |
| ditransitive | monotransitive | |
| monotransitive | intransitive | |
| trans | monotransitive |
Examples [24]-[27] illustrate these changes.
[24] His language is called Yathoyua and there's a dialect of it that I speak or that I write anyway called Dhamyathua.
[25] You would do if you were given the opportunity.
[26] The opportunities didn't seem to be part of the way I was brought up and educated.
[27] We were recommended to do this at university by one of the lecturers.
Features indicating the form of a non-finite VP include edp (past participle), infin (infinitive), and ingp (present participle). The tree structure for [22] can be seen in Figure 4.
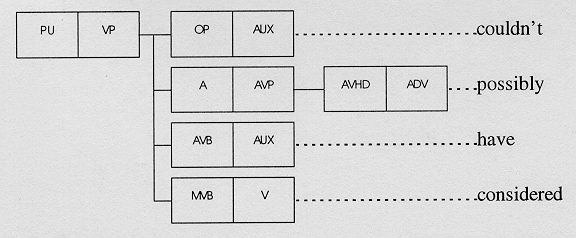
Figure 4: Tree structure for couldn't possibly have considered
[28] The roots of a new police should be firmly grounded in local communities at district council or London borough level with community councils in the cities and parish councils in the rural areas having consultative status.
[29] Fish soon recognise which bait is safe and they learn to avoid the one with the hook in it.
[30] Colonisation by other heterotrophic bacteria is also rapid, with Pseudomonas, Flavobacterium and Alcaligenes among the first to appear.
Verbless clauses introduced by PRTCL(with) as in [28]-[30] are all analysed as having an overt subject and a subject complement, all realised by PPs in the above examples. Another type of verbless clause does not even have a subject. Consider
[31] In accordance with the principles of direct play the ball should be thrown forward where possible.
Example [31] illustrates another exceptional criterion that determines the analysis of a verbless clause, viz., the presence of a subordinating conjunction. The AJP in the verbless clause is analysed as subject complement as where possible has a corresponding subordinate finite clause (cf. Greenbaum 1996: 329):
[31a] ... where that is possible.
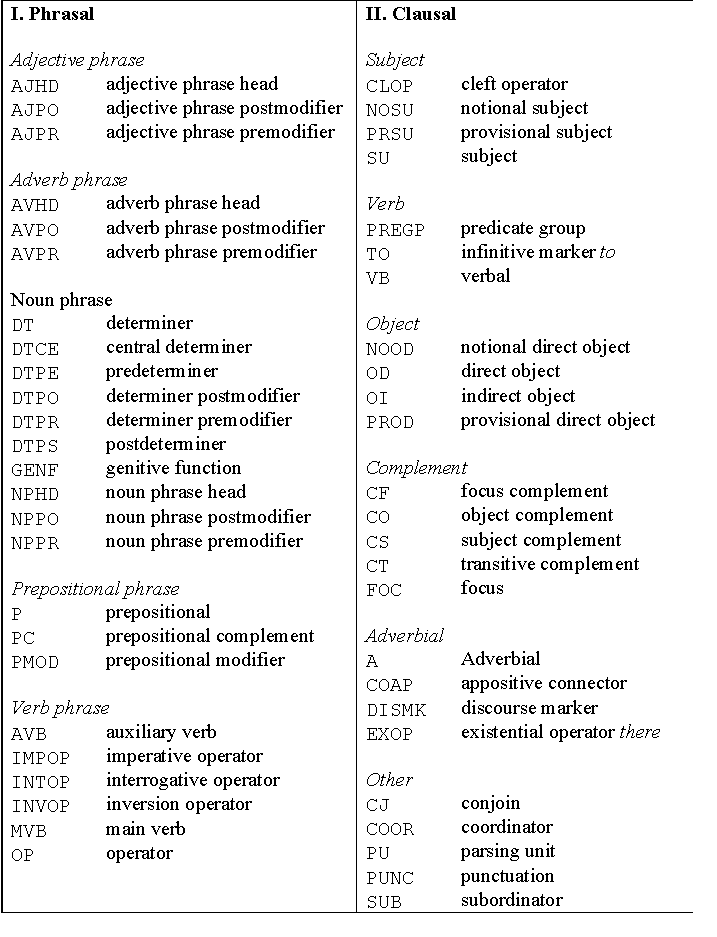
Quirk et al (1985) identify five such items: subject (S), verb (V), object (O), complement (C), and adverbial (A). All the five are captured by the present formalism, with further divisions. The object is divided into direct and indirect objects. The complement is subcategorised into object complement, subject complement, and transitive complement. There are other syntactic functions in the scheme, but they mainly specify inter-phrasal relationships such as AJP, AVP, and NP postmodifications (AJPR, AVPR, and NPPR) and thus do not have a direct sentential role. For a list of all the syntactic functions, see Appendix. Figure 5 represents the clause schema.
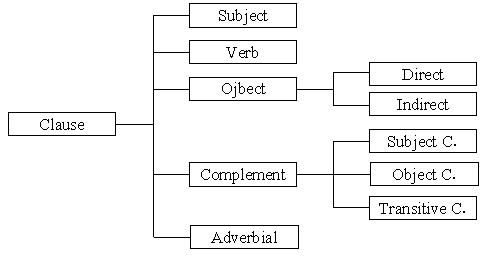
Figure 5: The clause elements
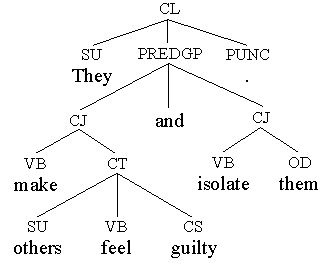
Figure 6: The analysis for [18]
The CT in [18] is performed by a bare infinitival clause, which is determined by the infinitive copula verb feel, with an overt subject (SU: others) and a subject complement (CS: guilty). Internal phrasal structures have been omitted in Figure 6 for clarity reasons.
Clause elements are realised by different formal categories:
| Syntactic functions | Formal categories |
| Subject Verb Direct object Indirect object Complement, subject Complement object Complement, transitive Adverbial | NP, clause VP NP, clause NP AJP, AVP, NP, PP, clause AJP, AVP, NP, PP non-finite clause AVP, NP, PP, clause |
All clauses are further described by the following features:
| coordination | coordn |
| main verb form | edp, ingp, infin |
| main verb type | intr, cop, montr, ditr, dimontr, cxtr, trans |
| missing element | -su, -op, -v, incomp |
| mood | exclam, inter, imp, subjun |
| pragmatic function | appos, voc, comment, |
| subordination | sub, rel, zsub, zrel, indrel |
| tense | pres, past |
| type | main, depend |
| voice | act, pass |
| word order | inv, preod, preoi, precs, preco, prepc, presu, extsu, extod, exist, cleft, pushdn |
Representation in PROSICE
Sentences accordingly analysed have their constituent structures
indicated by indentations and function and form labels. Each line
contains information about the function and the category of a
certain node. Features are listed between brackets to give detailed
descriptions about a particular category. Consider
[32] Hannah is not a putative feminist who wants equal opportunities with men.
which has the formal representation in Figure 7.

Figure 7: The functionally labelled syntactic tree of [32].
Thus, according to Figure 7, we know that [32] is a parsing unit (PU) realised by clause (CL) which has the following features:
| main | main clause |
| cop | copula verb |
| pres | present tense |
Hannah in is labelled as SU NP, indicating that categorically it is a noun phrase (NP) and functionally the subject (SU). Within this NP, the word form is enclosed between curly brackets, with the indication that it is a singular proper noun (N(prop,sing)) and that functionally it is the head of the NP (NPHD). The relative clause in is explicitly indicated by NPPO CL, which means that this clause functions as an NP postmodifier, with features such as montr (monotransitive), rel (relative), etc.
Each aligned syntactic tree is preceded by three numbers indicating: serial number, number of nodes, and number of leaves (see Figure 8). For instance, we can read in Figure 8 that this tree is the fifth in the whole text (<#5>), that there are 14 nodes altogether, and that there are 6 leaf nodes. Each leaf node is annotated with a digit indicating the number of lexical items occupying this node. This indication is especially helpful in the case of compound nouns (Judge Meyer, The Hague ), complex prepositions (in accordance with, by means of ), certain conjunctions (rather than, as if), certain marginal modal auxiliaries (need to, ought to ), and semi-auxiliaries (appear to, be about to ), which are treated as single units and ditto-tagged. Each item in the leaf node is followed by a time value that indicates its position in the actual digital recording and also indexes the other phonetic annotations.

Figure 8: A sample output of temporal and syntactic alignment
Applications of PROSICE and concluding remarks
In Huckvale and Fang (1996), we investigated the correspondence
of pause locations with grammatical categories (the sentence,
the clause, and the phrase). We described how the location of
most major and minor pauses - and hence indirectly prosodic phrasing
- could be explained from syntactic grounds alone. Table 4 lists
the frequencies of these categories and the pauses that co-occur.
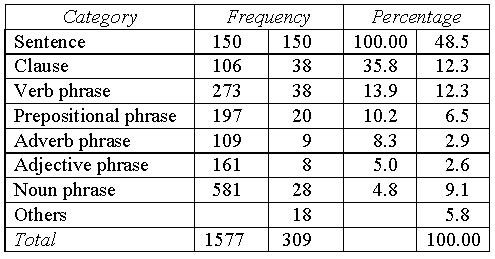
Table 4: Frequency distribution of pauses among major formal categories
The first column, Category, lists the types of syntactic categories, i.e., sentence, clause, etc. Frequency is divided into two columns: the first column indicates the observed frequency of a certain category and the second column the frequency of that category with initiating pauses. Percentage also has two columns, the first one displaying the percentage of a certain category that has initiating pauses and the second indicating the proportion of pauses falling into that category. Thus, we can read, for instance, that there are altogether 161 adjective phrases, 8 of which have initiating pauses. These eight occurrences occupy 5% of the total number of adjective phrases and 2.6% of the total number of pauses.
Our discussions based on Table 4 first of all confirmed that the pause is a reliable indicator of clause boundaries in read speech. Heavy subjects, complex prepositions, and the use of adverb phrases as sentential disjuncts were also found to co-occur consistently with pauses. These findings formed an important input into the development of SpeechMaker, an automatic computer system that predicts prosodic phrasing for text-to-speech purposes (cf. Svartvik and Fang 1996). We plan to develop similar models of timing and fundamental frequency, which would make a reasonable attempt at a neutral reading of an utterance (a reading that does not presuppose some understanding of the utterance). These models would describe statistical relationships between the form of the text of an utterance and its realisation that might well make similar predictions to a model that used an intermediate phonological model of prosody. This approach of speech modelling would not require a prior labelling of the corpus with prosodic annotations.
What we also find worth investigating next is to examine the category-pause correspondence while considering the syntactic functions realised the formal categories. Table 5 exemplifies the kind of function-category combinations we can observe in PROSICE given the syntactic annotations we described in the previous sections.
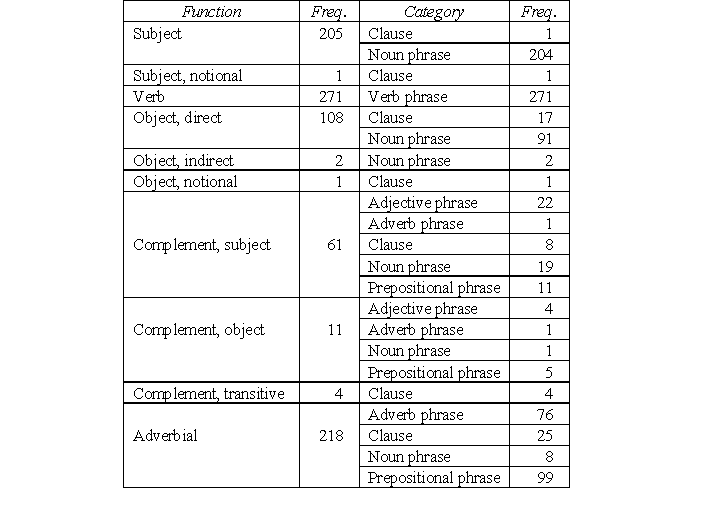
Table 5: Function-category combinations observed in PROSICE 3
A study of pauses through the syntactic functions of formal categories allows us to make refined generalisations. As a simple and easily observable example, we may safely generalise that subjects realised by heavy NPs usually co-occur with pauses. Without introducing the syntactic function, we can hardly draw any useful conclusions about heavy NPs. A similar remark may be made about adverbs, which can be sub-classified into adjuncts, conjuncts, and disjuncts in terms of their adverbial use at the sentence level. They serve different discourse functions and thus have their distinctive prosodic features.
To conclude our attempts in the construction and application of PROSICE for the study of English prosody, we would like to quote Svartvik (1990:69):
As for predictability, while a speaker is of course a free agent in his choice of linguistic behaviour, there is still enough evidence of a connection between grammar and prosody to make it worthwhile to explore more fully in which areas such patterning exists.
Appendix: A list of major ICE syntactic functions
References
Aarts, J., H. van Halteren and N. Oostdijk (1996). The TOSCA analysis
system. In Proceedings of the First AGFL Workshop, ed.
by C. Koster and E. Oltmans, Nijmegen: CSI. pp 181-191.
Altenberg, B. (1987). Prosodic Patterns in Spoken English - Studies in the Correlation between Prosody and Grammar for Text-to-Speech Conversion. Lund: Lund University Press.
Butterworth, B. (1980). Evidence from pauses in speech. In Language Production Vol. 1: Speech and Talk, ed. by B. Butterworth. London: Academic Press.
Croft, W. (MS.). Intonation units and grammatical knowledge.
Crystal, D. (1969). Prosodic Systems and Intonation in English . Cambridge: Cambridge University Press.
Fang, A.C. (1996a). AUTASYS: Grammatical tagging and cross-tagset mapping. In Greenbaum (ed). pp 110-124.
Fang, A.C. (1996b). The Survey Parser: design and development. In Greenbaum (ed). pp 142-160.
Fang, A.C. (1996c). Automatically generalising a wide-coverage formal grammar. In Synchronic Corpus Linguistics: Papers from the Sixteenth International Conference on English Language Research on Computerized Corpora, Toronto 1995, ed. by C. Percy, C. Meyer, and I. Lancashire. Amsterdam: Rodopi. pp 207-222.
Fourcin, A.J., and D. Gibbon (1994). Spoken language assessment in the European context. In Literary and Linguistic Computing 9, pp 79-86.
Goldman-Eisler, F. (1972). Pauses, clauses, sentences. In Language and Speech 15. pp 103-113.
Greenbaum, S. (1988). A proposal for an international computerized corpus of English. In World Englishes, 7, 315.
Greenbaum, S. (1992). A new corpus of English: ICE. In Directions in Corpus Linguistics: Proceedings of Nobel Symposium 82, Stockholm 4-8 August 1991, ed. by J. Svartvik. Berlin: Mouton de Gruyter. pp 171-179.
Greenbaum, S. (1996). The Oxford English Grammar. Oxford: Oxford University Press.
Greenbaum, S. (Ed) (1996). Comparing English World Wide: The International Corpus of English. Oxford: Oxford University Press.
Huckvale, M. and A.C. Fang (1996). PROSICE: a speech database for prosody study. In S. Greenbaum (ed). pp 262-279.
Knowles, G. (1993). From text to waveform: Converting the Lancaster/IBM spoken English corpus into a speech database. In Corpus-based Computational Linguistics, ed. by C. Souter and E. Atwell, Amsterdam: Rodopi. pp 47-58.
Knowles, G. (1994). Annotating large speech corpora: building on the experience of Marsec. In Journal of Linguistics, 13 . pp 87-98.
Knowles, G. (1995). Recycling an old corpus: converting the SEC into the MARSEC database. In Spoken English on Computer: Transcription, Mark-up, and Applications, ed. by G.N. Leech, G. Myers, and J.A. Thomas, London: Longman. pp 208-219.
Mair, C. (1990). Infinitival Complement Clauses in English . Cambridge: Cambridge University Press.
Oostdijk, N. (1995). The TOSCA analysis system applied to the domain of computer/software manuals. In International Workshop on Industrial Parsing of Software Manuals 1995, ed. by H.-D. Koch and R. Sutcliffe, Limerick: University of Limerick. pp 5-24.
Quirk, R., A.P. Duckworth, J. Svartvik, J.P.L. Rusiecli, and A.J.T. Colin (1962). Studies in the correspondence of prosodic to grammatical features in English. In Proceedings of the Ninth International Congress of Linguists, Cambridge, Mass., 1962. pp 679-691.
Quirk, R, S. Greenbaum, G. Leech, J. Svartvik (1985). A Comprehensive Grammar of the English Language. London: Longman.
Stenström, A.-B. (1990). Pauses in monologue and dialogue. In Svartvik (ed). pp 211-252.
Svartvik (Ed) (1990). The London-Lund Corpus of Spoken English - Description and Research. Lund: Lund University Press.
Svartvik and Fang (1996). SpeechMaker. To appear in Festschrift for Matti Rissanen, ed. by T. Nevalainen.
Svartvik, J., and R. Quirk (1979). A Corpus of English Conversation . Lund: Lund University Press.
© 1996 Alex Chengyu Fang and Mark Huckvale
 Back to SHL
9 Contents
Back to SHL
9 Contents
 Back to Phonetics and Linguistics
Home Page
Back to Phonetics and Linguistics
Home Page
