
FUNDAMENTAL FREQUENCY, AMPLITUDE ENVELOPE AND VOICELESS-NESS AS AUDITORY SUPPLEMENTS TO THE LIPREADING OF CONNECTED SPEECH
Introduction
The perceptual role of temporal structure in speech has until
recently (Rosen, 1992; van Tasell et al., 1992) been rather neglected
in comparison to spectral structure. Temporal speech information
is likely to have especial significance for hearing impaired listeners,
whose frequency resolution is impaired or, where the hearing loss
is profound, may be completely absent (Faulkner et al., 1990).
Temporal information can be considered to have several component elements. We have adopted a classification of temporal components based on the presence or absence of acoustic excitation, the periodicity or aperiodicity of excitation, the variation in frequency of periodic (laryngeal) excitation, and the amplitude variation of periodically and aperiodically excited speech. A further temporal aspect that is not investigated here is the instantaneous frequency of the speech pressure waveform which contains information that is in principle related to vocal tract resonances (Rosen, 1992), but which may not be perceptually accessible.
Applications of such an understanding include the design of hearing aids intended to make optimal use of limited auditory abilities (e.g. Faulkner et al., 1992), and tactile speech communication aids (e.g. Summers, 1992; Spens et al., 1996). Spectral speech information is broadly correlated with visible information from lipreading. However, the patterning in time of laryngeal excitation, silence and aperiodic excitation are invisible, as is the frequency of larynx vibration. The amplitude variation of speech components is correlated both with visible and invisible aspects of speech. Visible aspects include the degree of constriction (at least for more front articulations) which affects the speech amplitude, and the place of articulation of voiceless fricatives and voiceless plosives, which affects the amplitude of voiceless energy. Invisible factors include the opening of the nasal-pharyngeal tract in nasal consonants and nasalized vowels, and the amplitude varif different temporal information elements to segmental consonant identification were investigated in a previous series of studies (Rosen et al. 1995, Faulkner et al., 1996). These studies produced the surprising finding that variations in amplitude envelope do not contribute significantly to consonant identification. Rather, the main contribution from the above temporal information elements came from the duration of voiced and voiceless excitation.
The present study was performed to examine the contribution of these same temporally-coded information elements to the audio-visual perception of connected speech. Here, the perception of supra-segmental prosodic information is likely to contribute to performance through lexically- and syntactically-based stress. While the principal source of prosodic information is generally thought to be intonation, the acoustic correlates of stress include increased amplitude as well as raised intonation.
Previous studies by Risberg and Lubker (1978), and Breeuwer and Plomp (1987) have found that audio-visual perception of connected speech was significantly improved when amplitude envelope variation was added to a signal that conveyed fundamental frequency information. These studies, however, used different signal processing methods that did not have the same degree of accuracy in the measurement of voicing duration and fundamental frequency as in our studies, which used the laryngograph signal for this purpose. In addition, the contribution of andamental frequency as in our studies, which used the laryngograph signal for this purpose. In addition, the contribution of amplitude variation in Risberg and Lubker's study was rather slight. In Breeuwer and Plomp's study, the effect of added amplituuration and fundamental frequency, and that the main effect of adding amplitude envelope variation was to increase the accuracy of the representation of the pattern of voicing, by reducing the signal level at times when the fundamental frequency extraction processing had produced an erroneous output.
In our previous studies of consonant perception, we explicitly examined the contribution of fundamental frequency variation compared to a fixed frequency signal that represented the duration of voicing. In consonant perception, fundamental frequency variation was found to have only a minor role in that it increased the transmission of manner information, but did not lead to a significant increase in the consonant identification scores. In the present experiment, this comparison was not made, as the limited number of sentence test lists constrained the number of conditions that could be employed. However. other studies, notably that of Waldstein and Boothroyd (1994), have clearly established that fundamental frequency variation plays a major role in audio-visual sentence perception.
In view of our consonant identification findings, we sought here to examine the additional information from amplitude variation in sentence perception using speech processing methods. Since we had also found that consonant identification was significantly enhanced by the availability of a cue to the presence and duration of voiceless excitation, we also wanted to examine the significance of this factor in sentence-level speech perception.
Experiment
1. Method
1.1 Experimental Conditions
The three auditory supplements employed were:
Fx: a fixed-amplitude signal that represented the presence and duration of voiced excitation and the natural variation of voice fundamental frequency. The acoustic signal was a narrow pulse-train band-limited to 5 kHz whose rate followed the voice fundamental frequency.
Fx(A): as Fx, but with an amplitude envelope measured from voiced speech imposed on the signal.
Fx(A) + Nz(A): as Fx(A) with the presence and duration of purely voiceless excitation represented, together with an amplitude envelope measured from voiceless speech. Voiceless excitation was represented by a 5 kHz band-limited random noise.
The fourth condition was unaided lipreading (L).
1.2 Speech Processing
1.2.1 Fundamental frequency and voicing
Fundamental frequency and the duration of laryngeal excitation
were derived from an electro-laryngograph signal. For voiced speech,
voicing was represented by the presence of a pulse signal whose
rate was controlled cycle-by-cycle to represent voice fundamental
frequency. The pulse signal, from a Pulsetek pulse generator,
had a width of approximately 2 s which resulted in a spectral
envelope that was flat from the fundamental frequency up to 5
kHz. The flat spectrum was required to match the spectrum of
the white noise used to represent voiceless excitation and so
to eliminate any possibility of spectral cues that may distinguish
the pulse and noise stimuli. Both pulse and noise signals were
band-limited to 5 kHz.
1.2.2 Voiceless excitation
Voiceless excitation was detected by a spectral balance circuit
comparing the amount of energy above and below 3 kHz in the speech
signal. The detection of voiceless excitation controlled a gate
that turned on a white noise signal. Voiceless excitation was
only represented in the absence of laryngeal vibration, so that
mixed excitation was represented only by the pulse signal. The
voiceless noise signal was then mixed with the voicing pulses,
and the combined signals were lowpass filtered at 5 kHz.
1.2.3 Amplitude envelope
The amplitude envelope for both voiced and voiceless speech was
derived by fullwave rectifying the broadband speech signal and
smoothing the result using a 30 Hz, 24 dB/octave lowpass filter.
The envelope signal was then multiplied in hardware with the summed
pulse and noise signals.
1.3 Speech materials
Speech materials were taken from the UCL EPI audio-visual recording
of the BKB sentences. The speaker was an adult female. Normative
data have been established for these recordings (Foster et al.,
1993), which confirm that, with the exception of one list, there
are only minor differences in difficulty between lists both in
unaided lipreading and lipreading aided by Fx information. Each
of the 21 sentence lists comprises 16 sentences, each with four
or five "key" content words that are scored for correctness.
1.4Subjects
Six normally hearing subjects took part. All were Speech Science
students at UCL aged between 21 and 35. All had normal hearing
and normal or corrected-to-normal vision. The subjects were all
familiar with the test speaker and had taken part in lipreading
tests previously. They had not, however, been exposed to the BKB
sentences before.
1.5 Procedure
Each subject first received an unscored practice sentence list
in each of the four conditions. Because of the limited number
of available lists, the same list was used in each condition.
This was List 1, which according to Foster et al. (1993) differs
most in difficulty from the mean difficulty of the 21 lists. Subjects
subsequently received five test sessions comprising one test list
in each of the four conditions. The order of four conditions was
counterbalanced over five testing sessions. The subjects were
split into two groups, and the two counterbalanced orders were
used to distribute the BKB lists more evenly between the test
conditions. The video image was presented on a 18" Panasonic
colour monitor, and the audio signal was presented free-field
through a QUAD PRO-63 electrostatic loudspeaker.
2. Results
Each sentence list was scored according to the "key-word
tight" (KW-T) procedure (Bamford and Wilson, 1979). This
was preferred to the "key-word loose" method since it
requires the key words to be identified exactly, and hence was
expected to reflect more accurately the perception of detailed
phonetic information such as the presence of detection of voiceless
/s/ in indicating plurality. Data analysis was performed both
for the raw scores, and using the correction factors for the KW-T
scoring given by Foster et al. (1993). They give correction factors
for each list both for unaided lipreading and for lipreading aided
by Fx information. The unaided lipreading corrections were here
applied to scores from condition L, and the corrections for lipreading
aided by Fx were applied to all three audio-visual conditions.
The group results are shown in Figure 1. It is evident that the correction factors have no major effect on the scores. Since all the correction factors are positive, the corrected score means are slightly higher, but the variability seems to be essentially unchanged..
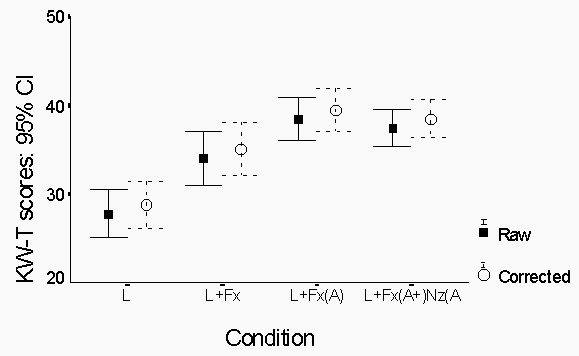
Figure 1. Mean number of key words identified by condition. The error bars are simple 95% confidence intervals for each mean. Both raw KW-T scores and scores corrected according to the factors determined by Foster et al. (1993) are shown.
2.1 Analysis
Because scores from some subjects approached the upper bounds
of the test in some audio-visual conditions, an arcsine transformation
was applied to the data prior to an analysis of variance that
was carried out using SAS. Comparisons between conditions were
made using Tukey Studentized range tests with a significance criterion
of p<0.05. As expected, all three of the audio-visual conditions
showed significantly higher scores than the visual only condition.
Scores in conditions L+Fx(A) and L+Fx(A)+Nz(A) did not differ
significantly, while both showed a significantly higher score
than condition L+Fx. There was also a significant practice effect
over sessions; [F(4,20) = 10.55], p<0.001, but no significant
interaction of condition and session; [F(12,60) = 1.82]. An ANOVA
using the corrected scores showed the same pattern and levels
of significance.
The group average scores by condition and test session are shown in figure 2. The score in condition L+Fx was substantially lower in session one than in later sessions. This is likely to be because the counterbalancing of list number and test condition resulted in all subjects receiving the L+Fx condition first in session 1. Clearly the pre-test practice was insufficient to bring the subjects up to a stable performance level. Nevertheless, the rank order of scores for the four conditions is the same in each session, and the condition by session interaction was not statistically significant.
Figure 3 shows the mean score by condition for each subject There are differences in the rank ordering of conditions L+Fx(A) and L+Fx(A)Nz(A) between subjects. S3 and S4 perform slightly better with the additional voiceless information, but the other three show slightly lower scores.
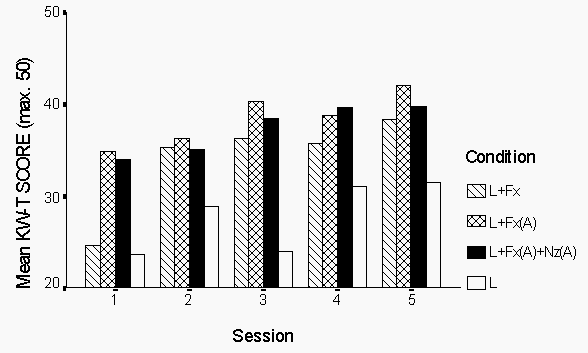
Figure 2. Mean scores by condition and session.
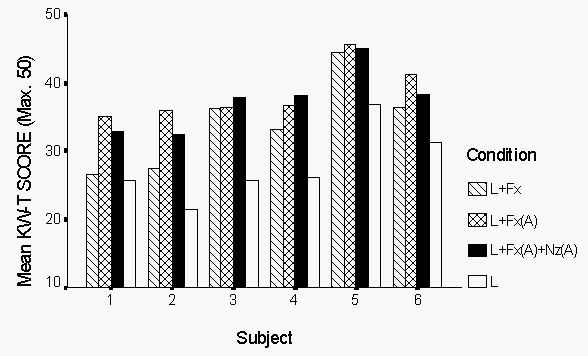
Figure 3. Mean scores by condition and subject.
2.2 Discussion
In showing a significant contribution of amplitude envelope variation,
the results of experiment 4 are consistent with other results
in the literature. Since we have found no significant contribution
of amplitude variation at the level of segmental (consonant) perception,
we attribute the effect of amplitude variation here to supra-segmental
factors.
A contribution of voiceless excitation information is not apparent here, despite it being consistently significant in consonant identification. The effect of the additional voiceless information varied between subjects. Presumably the contribution it can make in consonantal manner perception and the enhancement of voicing contrasts is made less significant here by the availability of syntactic and lexical context. The sentence materials used here are relatively simple and predictable. It may be that more complex and less predictable sentence materials would show more effect of the representation of voiceless excitation.
Acknowledgements
Supported by TIDE project TP1217 (OSCAR). Athena Euthymiades carried
out the experimental work as a final year undergraduate project
in the department.
References
Bamford, J., and Wilson, I (1979) "Methodological considerations
and practical aspects of the BKB Sentence Lists". In: Bench,
J., and Bamford, J. (Eds) Speech-hearing Tests and the Spoken
Language of Hearing-impaired Children. London: Academic Press,
pp. 147-187.
Breeuwer, M. and Plomp, R. (1985) "Speechreading supplemented by auditorily presented speech parameters". J. Acoust. Soc. Am., vol. 79, pp. 481-499.
Faulkner, A., et al. (1992) "Speech pattern hearing aids for the profoundly hearingimpaired: Speech perception and auditory abilities", J. Acoust. Soc. Am., vol. 91, pp. 21362155.
Faulkner, A., Rosen, S., and Moore, B. C. J. (1990) "Residual frequency selectivity in the profoundly hearing impaired listener". Br. J. Audiol., vol. 24, pp. 381-392.
Foster, J. R., et al. (1993) "Lip-reading the BKB sentence lists: corrections for list and practice effects". Br. J. Audiol., vol. 27, pp. 233-246.
Risberg, A., and Lubker, J. L. (1978) "Prosody and speechreading" Rep. STL-QPSR 4, Dept. of Linguistics, University of Stockholm, Stockholm, Sweden, pp. 1-16.
Rosen , S. et al. (1980) "Lipreading connected discourse with fundamental frequency information". Brit. Soc. Audiol. Newsletter (Summer), pp. 4243.
Rosen, S. et al. (1979) "Lipreading with fundamental frequency information". Proc. Inst. Acoust. Autumn Conf., pp. 58.
Rosen. S (1992) "Temporal information in speech: acoustic, auditory and linguistic aspects". Phil. Trans. Royal Soc. London B, vol. 336, pp. 367373.
Spens, K-E., Huss, C., and Dahlquist., M. (1996). "Characteristics and preliminary results of a two-channel tactile speech communication aid". Proc. ISAC-96.
Summers, I. R. (Ed) Tactile Aids for the Hearing Impaired, Whurr publishers, London.
Van Tasell, D. J. et al. (1992) "Temporal cues for consonant recognition: Training, talker generalization, and use in the evaluation of cochlear implants". J. Acoust. Soc. Am., vol. 92, pp. 1247-1257.
Waldstein, R. S. and Boothroyd, A. (1994) "Speechreading enhancement using a sinusoidal substitute for voice fundamental frequency". Speech Communication, vol. 14, pp. 303-312
© 1996 Andrew Faulkner and Athena Euthymiades
 Back to SHL 9 Contents
Back to SHL 9 Contents
 Back to Phonetics and Linguistics Home Page
Back to Phonetics and Linguistics Home Page
