
Abstract
The temporal distribution of perceptually relevant information
for consonant recognition in British English VCVs is investigated.
The information distribution in the vicinity of consonantal closure
and release was measured by presenting initial and final portions,
respectively, of naturally produced VCV utterances to listeners
for categorisation. A three-way multidimensional scaling analysis
provided highly interpretable, 4-dimensional geometrical representations
of the confusion patterns in the categorisation data. For initial
as well as final portions, two dimensions of the stimulus space
were associated with manner of articulation and voicing, while
the two other dimensions were associated with place of articulation.
In addition, transmitted information as a function of truncation
point was calculated for the features manner place and voicing.
The effects of speaker, vowel context, stress, and distinctive
feature on the resulting information distributions were tested
statistically. It was found that, although all factors are significant,
the location and spread of the distributions depends principally
on the distinctive feature, i.e., the temporal distribution of
perceptually relevant information is very different for the features
manner, place and voicing.
1. Introduction
During the production of speech, articulatory gestures implementing
successive linguistic units overlap temporally. This phenomenon,
known as coarticulation, causes acoustic information associated
with any linguistic unit to be smeared in time (e.g. Liberman
et al, 1967; Suomi, 1985). From this observation it does not automatically
follow, however, that listeners actually use the entire portion
of the speech signal affected by a linguistic unit to identify
that unit. Stevens and Blumstein in particular argued that, although
coarticulation causes considerable temporal smearing of acoustic
information, listeners actually base their consonantal identifications
on short (20-odd ms) relatively context-independent portions of
the speech signal sampled at instants of great spectral change
(e.g. Stevens and Blumstein, 1981). More recently, Stevens and
co-workers have started building an automatic speech recognition
system, intended to mimic human speech recognition, in which similar
ideas play a central role (Stevens, 1995; Liu, 1996). In the first
step of the recognition process, the system detects instants of
maximum spectral change, called acoustic landmarks, which are
associated with moments at which the vocal tract achieves or releases
maximum constriction. After landmark detection, the system classifies
so-called articulator-free features (roughly corresponding to
manner of articulation), followed by articulator-bound features
(roughly corresponding to place and voicing). Stevens claims it
is relatively straightforward to classify the articulator-free
features on the basis of the speech signal in the immediate surroundings
of the landmark. For the classification of the articulator-bound
features, however, it is still not well quantified which acoustic
measurements, nor where in the acoustic signal they are to be
made (Stevens, 1995, p. 6). Furthermore, the role of phonetic
context and stress in the classification process is unclear.
The present study aims to describe the temporal distribution of perceptually relevant information for consonant recognition. In particular, it is investigated to what extent consonant information is concentrated around acoustic landmarks, whether temporal distributions differ for various distinctive features, and whether there is significant influence of stress and phonetic context on the distributions. These research questions are approached most directly using the well-known gating technique (e.g. Grosjean, 1980). In the gating technique only segments of the complete utterance are presented to listeners. In forward gating the initial part, in backward gating the final part of an utterance is presented. By varying the cut-off point before or after which the utterance is deleted, one can measure the perceptual relevance of various parts of the signal. In order to be able to study the perceptual relevance of signal portions around closure as well as release of consonants, VCV utterances were gated both forward and backward.
In the past, similar studies have been conducted by, amongst others,
Grimm (1966), Öhman (1966) and Furui (1986).1 Grimm (1966)
presented listeners with backward-gated versions of 42 CV syllables
composed of the consonants 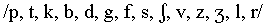 and vowels
and vowels 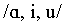 , spoken once by each of four talkers
of American English. The resulting classification data showed
that, when increasing portions of the initial part of the CV were
deleted, correct classification of manner of articulation decreased
on average 25ms earlier than that of voicing, which, in turn,
decreased about 5ms earlier that that of place of articulation.
A more detailed interpretation of Grimm's data for my purpose
is hindered by the fact that the instant of peak intensity in
the syllable, rather than the instant of consonantal release,
is used as temporal reference point in the data analysis.
, spoken once by each of four talkers
of American English. The resulting classification data showed
that, when increasing portions of the initial part of the CV were
deleted, correct classification of manner of articulation decreased
on average 25ms earlier than that of voicing, which, in turn,
decreased about 5ms earlier that that of place of articulation.
A more detailed interpretation of Grimm's data for my purpose
is hindered by the fact that the instant of peak intensity in
the syllable, rather than the instant of consonantal release,
is used as temporal reference point in the data analysis.
Öhman (1966) presented listeners with initial and final parts
from 21 Swedish /aCCa/ utterances spoken by a single talker, with
consonants 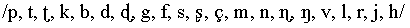 . The first syllable was stressed in all utterances. The
results of the experiment showed that, generally, correct classification
of manner of articulation changes quite abruptly when increasing
amounts of information become available around the closure or
release landmarks. Correct classification of voicing and place
of articulation changed less sharply, and was very different for
the various phonemes used. Unfortunately, Öhman's data analysis
in terms of percent correct per consonant does not tell us to
what extent various portions of the speech signal enables listeners
to correctly make distinctions between consonants.
Another problem with Öhman's study is the relatively small
size of the data set. Only one speaker, one token of each VCCV,
one vowel context, and one stress condition was used. This makes
it difficult to judge the generalisability of the results, especially
given the high level of detail of the analyses.
. The first syllable was stressed in all utterances. The
results of the experiment showed that, generally, correct classification
of manner of articulation changes quite abruptly when increasing
amounts of information become available around the closure or
release landmarks. Correct classification of voicing and place
of articulation changed less sharply, and was very different for
the various phonemes used. Unfortunately, Öhman's data analysis
in terms of percent correct per consonant does not tell us to
what extent various portions of the speech signal enables listeners
to correctly make distinctions between consonants.
Another problem with Öhman's study is the relatively small
size of the data set. Only one speaker, one token of each VCCV,
one vowel context, and one stress condition was used. This makes
it difficult to judge the generalisability of the results, especially
given the high level of detail of the analyses.
Furui (1986) presented forward-gated, backward-gated and simultaneously left- and right-truncated portions of a large set of Japanese V, CV and CjV utterances to listeners for classification of consonant and vowel. The aim of the study was to identify which portion of the signal holds the essential information for the correct recognition of each consonant, and what the relation is between spectral dynamics and perceptual relevance of portions of the speech signal. It was found that for plosives and nasals the interval needed for correct consonant recognition was 50 to 70ms, starting roughly 10ms before release. For unvoiced fricatives the essential interval was on average 120ms long, starting 100ms before voicing onset. The spectrally most dynamic portions of the speech signal appeared to be the most informative to listeners.
The present study differs from the ones discussed above on several points. First of all, it studies production and perception of British English consonants. Secondly, like Öhman (1966), the information distributions around closure as well as release are investigated using intervocalic consonants. As argued by Pickett et al. (1995), intervocalic consonants are much more common in conversational speech than initial or final consonants. Therefore, listeners will generally have access to acoustical information on consonant identity at closure as well as release in more natural settings. Thirdly, rather than concentrating on percent correct scores for individual consonants as in the studies above, the perceptually relevant information for various distinctive features, as well as patterns of confusions themselves are studied. In addition, the significance of various phonetic and experimental parameters are tested statistically. Finally, in order to be able to draw conclusions that have a relatively high degree of generalisability, a large set of classification data is collected, using a relatively large number of utterances.
The remainder of the paper is organised as follows. In the next section the method for the stimulus preparation and experimental testing are presented. A brief description of closure durations in the various consonants is included. Next, the results of the perception experiment is presented. Two analysis methods were adopted: a multidimensional scaling analysis and an information-theoretical analysis. In the final section the results are summarised and discussed.
2. Method
2.1 Stimuli
2.1.1 Original utterances
Two speakers of British English, one male and one female, each
produced four tokens of 51 VCV nonsense words. The vowels and the consonants 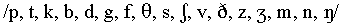 were used. The initial vowel was always identical to the
final vowel. Two out of four tokens of each VCV combination were
spoken with initial stress and two with final stress. Thus, 408
original utterances were obtained. The utterances were spoken
in a soundproof anechoic room, were low-pass filtered at 10kHz
and quantised as 16-bit numbers at a sampling rate of 22.05kHz.
Next, the speech signals were digitally high-pass filtered at
30Hz using a linear-phase filter.
were used. The initial vowel was always identical to the
final vowel. Two out of four tokens of each VCV combination were
spoken with initial stress and two with final stress. Thus, 408
original utterances were obtained. The utterances were spoken
in a soundproof anechoic room, were low-pass filtered at 10kHz
and quantised as 16-bit numbers at a sampling rate of 22.05kHz.
Next, the speech signals were digitally high-pass filtered at
30Hz using a linear-phase filter.
For each utterance, the closure and release landmarks were located visually using the waveform and wideband spectrogram. Generally, landmarks were put at instants where the amplitude of the first formant decreased or increased most rapidly. In difficult cases, like some of the voiced fricatives, a sudden increase or decrease in the amplitudes of the second and third formants was used as well. For all plosive consonants the release landmark was put at the instant of burst release. An example of an utterance with landmark annotations is given in Figure 1.
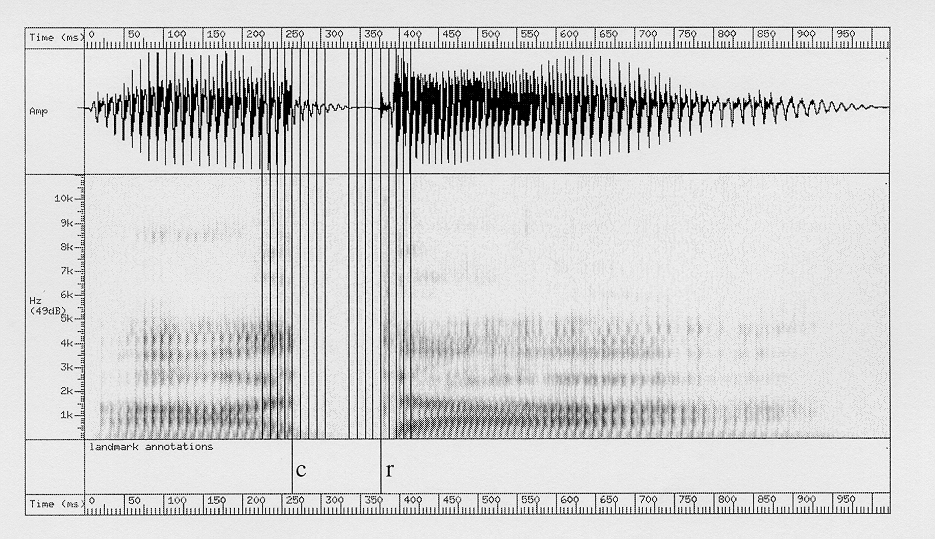
Figure 1. Waveform and spectrogram of utterance /ada/ with closure ("c") and release ("r") landmarks indicated in the bottom panel. The cut-off points for the 9 forward-gated stimuli (around closure landmark) and for the 9 backward-gated stimuli (around release landmark) are indicated by means of vertical lines.
Appendix A presents some statistics on the durations of consonantal closure, defined as the interval between the closure and release landmarks.
2.1.2 Gating techniques
Two types of gating were carried out. The perceptual relevance
of the signal in the vicinity of the closure landmark was tested
using forward-gated stimuli, that is, stimuli in which
the part of the speech signal following an instant relative to
the closure landmark was deleted. The perceptual relevance of
the signal in the vicinity of the release landmark was tested
using backward-gated stimuli in which the part of the speech
signal preceding an instant relative to the release landmark was
deleted. A linear 10ms ramp was applied at the cut-off point to
avoid creating transients. The deleted portion of the speech signal
was replaced by a 500ms pink noise signal which was, like the
speech signals, lowpass filtered at 10kHz and highpass filtered
at 30Hz. The noise was scaled to a fixed level such that its maximum
instantaneous amplitude was 0.031 times (or 30dB below) the maximum
instantaneous amplitude of the speech signals across all utterances.
For each stimulus a different 500ms pink noise portion was selected
randomly from a 10s signal. A linear 10ms ramp was applied at
the edge of the noise adjoining the gated speech signal, and the
two signals were overlap-added such that the envelopes of the
two ramps summed to unity. Both for the forward and the backward-gated
stimuli the cut-off ramp was centred at -80, -60, -40, -20, 0,
20, 40, 60, and 80ms relative to the landmark, thus creating 9
forward-gated and 9 backward-gated stimuli from each original
utterance. The cut-off points for the utterance displayed in Figure
1 are indicated by vertical lines. 7344 gated stimuli were created
in total.
2.2 Subjects
Sixteen subjects took part in the experiments. All subjects were
native speakers of British English and had normal hearing (within
20dB HL for frequencies between 250Hz and 8kHz).
2.3 Procedure
The total set of gated stimuli was subdivided into four subsets:
(1) speaker 1, initial stress; (2) speaker1, final stress; (3)
speaker 2 initial stress and (4) speaker 2, final stress. Four
subjects were assigned to each of these subsets. Each subject
took part in 11 experimental sessions. In the first session, the
subjects were presented with the original utterances. They were
asked to indicate the consonant by pressing one of 17 buttons.
The labels on the buttons were ordered alphabetically: b, d, dh
for 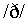 , f, g, k, m, n, ng for
, f, g, k, m, n, ng for 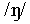 , p, s, sh for
, p, s, sh for
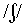 , t, th for
, t, th for 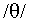 , v, z, and zh for
, v, z, and zh for 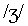 .
All subjects were trained briefly in the
use of the labels dh, th, zh, and sh. Three subjects could not
master the use of these labels with sufficient accuracy and were
replaced. When a subject was sufficiently trained in the use of
the labels, he or she was presented with five replications of
each original utterance of the respective subset ordered randomly.
Each subject classified all consonants with an accuracy of 80%
or higher.
.
All subjects were trained briefly in the
use of the labels dh, th, zh, and sh. Three subjects could not
master the use of these labels with sufficient accuracy and were
replaced. When a subject was sufficiently trained in the use of
the labels, he or she was presented with five replications of
each original utterance of the respective subset ordered randomly.
Each subject classified all consonants with an accuracy of 80%
or higher.
In the next 10 sessions the subjects were presented with the gated stimuli. In every group, two subjects were presented with the forward-gated stimuli in the first 5 sessions and with the backward-gated stimuli in the last 5 sessions. The order for the other 2 subjects in the group was reversed. In one session all stimuli of the particular subset were presented once in random order. In the next session all stimuli were presented again in a different random order, etcetera. The subjects were told that they would be presented with segments of the VCV utterances they had heard earlier, and they were instructed to indicate the consonant in the original VCV they thought the segment was taken from. Before each batch of 5 sessions the subjects were familiarised to the stimuli by a 10-minute practice session, the results of which were discarded. On average each subject spent about 20 hours on the 11 sessions of the experiment. Sessions were spread out over several days. Each session was divided into 3 runs by 10-minute breaks. When all experiments were finished, each gated stimulus had been classified 20 times, resulting in 146,880 classifications in total.
3. Results
3.1 Multidimensional scaling analysis
In order to obtain an easily interpretable representation of the
principal confusion patterns in the data, a multidimensional scaling
analysis was carried out. An additional objective was to establish
which confusions would be resolved at various stages of gating.
No attempts were made to associate acoustic dimensions with the
dimensions emerging from the analyses.
3.1.1 Method
For each gate, a single 17×17 confusion matrix was constructed
by summing across listeners, tokens, vowels and stress. Separate
confusion matrices were calculated for the two speakers and the
two types of gating (forward vs. backward). These confusion matrices
were transformed into symmetrical distance matrices using the
chi-square distance measure D, defined by
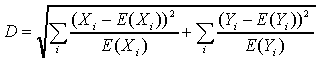
Where Xi and Yi represent
the number of times stimuli X and Y have been assigned
to response i, and E(Xi) and E(Yi)
represent the expected frequencies under the assumption of independence.
In this case 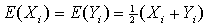 , which leads to
, which leads to
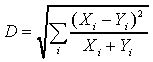
A subset of the 36 distance matrices were selected on the basis of their degree of confusion. As MDS is based on the analysis of confusions, matrices which hardly display any confusion are unsuitable for entry in the analysis. Matrices which display very high levels of confusion, on the other hand, do not hold much information. The matrices for the following gates were selected:
Forward gating: -40, -20, 0, 20, 40ms;
Backward gating: -20, 0, 20, 40, 60ms.
For each gating type, 10 matrices (5 gates × 2 speakers) were entered in a single nonmetric individual differences MDS analysis using the ALSCAL program (Takane et al, 1977). In nonmetric individual differences MDS, a single multidimensional perceptual space is derived from a set of distance matrices using the assumptions that
Originally, the ALSCAL analysis was designed for a set of matrices obtained for different subjects, leading to a universal underlying perceptual space for all subjects. Like Soli and Arabie (1979), however, I chose to enter matrices for different conditions (gates), rather than subjects. This approach is more suitable here because it causes patterns of confusions that differ between gates to be assigned to separate dimensions. For example, suppose that, for the forward-gated stimuli, place of articulation confusions would become resolved for gates after -20ms, while manner confusions would only become resolved for gates after +20ms. An individual differences MDS analysis carried out on separate matrices for different gates would assign place and manner confusions to different dimensions. That is, VCV stimuli containing consonants with different place of articulation would be close together (confusable) on, say, dimension 1, and well-separated (non-confusable) on dimension 2, while the reverse holds for consonants with different manner of articulation. Inspection of the dimension weights for various gates will reveal which confusions become resolved at which gates. Additionally, differences between speakers in the distribution of consonantal information across the time dimension will be revealed in the dimension weights.
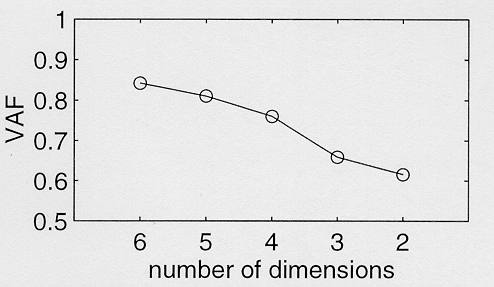
Figure 2. Proportion of variance accounted for (VAF) for dimensionalities 2 to 6 of the ALSCAL analyses of the forward-gated stimuli.
In the ALSCAL program one can choose between several measures to be optimised, which is reflected in the conditionality option (Takane et al, 1977). If comparisons between distances across matrices are meaningful, one should optimise the overall percentage of explained variance across all distance matrices ("unconditional"). If such comparisons are not meaningful, one should optimise the average percentage of explained variance per matrix ("matrix conditional"). In principle, comparisons between distances of different matrices are meaningful in this case. However, the absolute variances of distance matrices with low and high levels of confusion are generally quite different. As a result, the unconditional option caused the various matrices within one analysis to be weighed very differently, which produced results that were difficult to interpret. Therefore I chose the matrix conditional option for the analyses.
3.1.2 Results
Forward-gated stimuli
The proportion of variance accounted for (VAF) for the 2- to 6-dimensional solution for the forward-gated stimuli is displayed in figure 2. Figure 2 suggests that the 4-dimensional solution be selected. Assuming that each perceptual dimension is associated with one binary phonological distinction, a 4-dimensional space can accommodate 24=16 consonants. This number is close to the number of responses in the experiment (17), which gives additional support for the chosen dimensionality.
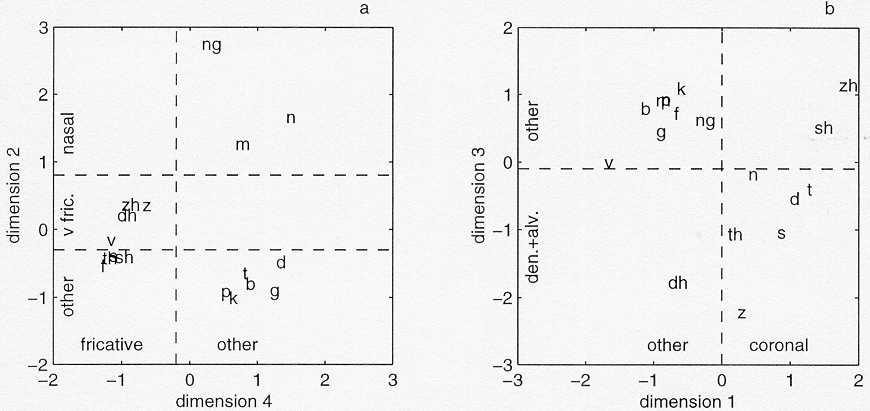
Figure 3. Stimulus configuration in the 4-dimensional ALSCAL solution for the forward-gated stimuli. The dashed lines, which partition the space into regions in accordance with phonological features, were added later. The labels "dh, th, zh, sh, ng" indicate consonants 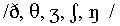 , respectively.
, respectively.
The configuration of the 17 consonants in the 4-dimensional stimulus
space is presented in figure 3. Extra lines were added to the
figure to facilitate interpretation. All four dimensions appear
to be associated with phonological distinctions. Dimensions 2
and 4, depicted in figure 3a, are associated with manner of articulation
and voicing. Dimension 2 can be divided into three separate parts
containing nasals, voiced fricatives and other consonants. Dimension
4 separates fricative consonants from other consonants (plosives
and nasals). Dimensions 1 and 3, depicted in figure 3b, are associated
with place of articulation. Coronal consonants (with the exception
of ) are separated from non-coronal ones along dimension 1.
Along dimension 3, dental and alveolar consonants are separated
from other consonants. Note that in the place-of-articulation
plane defined by dimensions 1 and 3, the consonants are less tightly
clustered into groups than in the manner-and-voicing plane defined
by dimensions 2 and 4.
Figure 4 shows the evolution of dimension weights as a function of gate position for the two speakers. In the matrix-conditional ALSCAL analysis information on the overall level of confusion is lost and only the proportions of the weights are preserved (MacCallum, 1977). The norm of the weight vector, i.e. the sum of squares of the dimensional weights, is made proportional to the percentage VAF. Before plotting, I re-normalised the norm of the weight vector to unity for all matrices. For the interpretation of figure 4 it should be kept in mind that the overall level of confusion decreases rapidly across the gates indicated in the figure, and only the relative importance of the dimensions will be discussed.
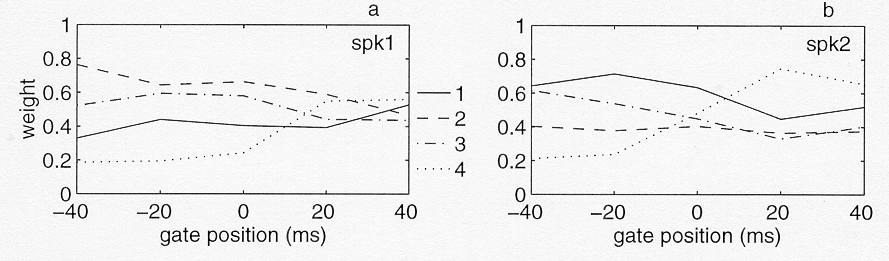
Figure 4. Dimension weights for the 4-dimensional ALSCAL solution for the forward-gated stimuli for speaker 1 (4a) and speaker 2 (4b). The labels for the different line types are given in the figure.
The relative salience of information on manner and place of articulation
for early gates (-40ms to 0ms) is different for speakers one and
two. The confusions for the low gates of speaker one are generally
dominated by dimension 2, which is associated with the {nasal
- voiced fricative - other} distinction. This is not the case
for speaker two, whose weights for the early gates of the "place
dimensions" 2 and 4 are much lower than those for the "manner
dimensions" 1 and 3. For this speaker the role of dimension
4 (fricative versus non-fricative) rather abruptly changes from
insignificant to dominant between the gates at -20ms and +20ms. Apparently,
for speaker two, manner information (in particular frication)
becomes available suddenly at closure. This is less the case for
speaker one, where nasality and frication information is, apparently,
available well before closure. The confusion patterns for palatal
fricatives and are somewhat different for the two speakers.
For speaker one, dimension 3 generally dominates over dimension
1, indicating that and are easily confused with non-coronals,
while for speaker two, where dimension 1 is generally more important,
and are easily confused with other coronals. Backward-gated
stimuli
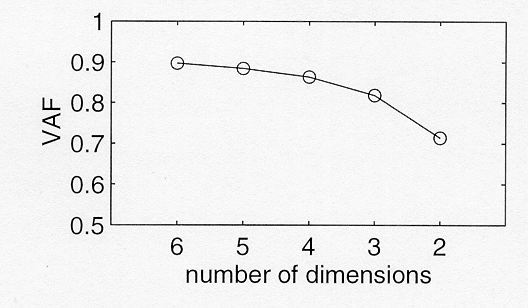
Figure 5. VAF for dimensionalities 2 to 6 of the ALSCAL analyses of the backward-gated stimuli.
Backward-gated stimuli
The proportion of variance accounted for (VAF) for the 2- to 6-dimensional solution for the backward-gated stimuli is displayed in Figure 5. Figure 5 does not suggest the selection of any particular dimension. The 4-dimensional solution was selected to keep the dimensionality compatible with that of the forward-gated stimuli.
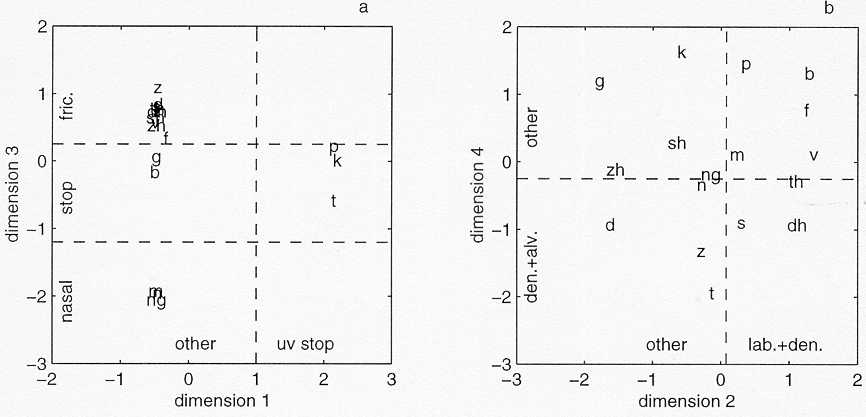
Figure 6. Stimulus configuration in the 4-dimensional ALSCAL solution for the backward-gated stimuli.
The configuration of the 17 consonants in the 4-dimensional stimulus space is presented in figure 6. Again, all four dimensions appear to be associated with phonological distinctions. Dimensions 1 and 3, depicted in figure 6a, are associated with manner and voicing. Dimension 1 separates voiceless plosives from other consonants. Dimension 3 mainly separates nasals from other consonants and to a lesser extent separates fricatives and plosives, with the exception of /d/, which is located in the fricative area. Dimensions 2 and 4 are associated with place of articulation. Labials, labiodentals and dentals are separated from other consonants along dimension 2, with the exception of /s/, while dimension 4 separates dentals and alveolars from other consonants. Note that, like for the forward-gated stimuli, the consonants are much less clustered along the place dimensions than along the manner and voicing dimensions.
The evolution of dimension weights is given in figure 7. The differences
between the two speakers are smaller here, compared to the forward-gated
stimuli. It is striking that for late gates the picture is completely
dominated by dimension 1 for both speakers. When only the final
part of the utterance after closure is presented, listeners can
easily hear the difference between voiceless plosives and other
consonants, presumably on the basis of the aspirated formant transitions.
At closure (0ms) the weights for all four dimensions are not very
different, while for -20ms dimensions 2 and 3 are dominant for
both speakers. Interestingly, when a short portion of the frication
is presented, the fricatives 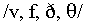 are easily confused.
are easily confused.
3.1.3 Discussion
The principle purpose of the ALSCAL analyses was to describe major
patterns of confusions in the classification data. In terms of
manner of articulation and voicing, the forward-gated stimuli
were clustered as nasal consonants, voiced fricatives, voiceless
fricatives and plosives, while the backward-gated stimuli were
clustered as nasals, fricatives, voiced plosives and voiceless
plosives. The distribution of consonants across the plane associated
with place of articulation was less strongly clustered. However,
the forward-gated stimuli could be partitioned into dentals+alveolars,
palatals, and other consonants, while the backward-gated stimuli
could be partitioned into labials+labiodentals, dentals, alveolars,
and palatals+velars. These patterns will be used in the definition
of classes for the analyses of information transmission presented
in the next section.
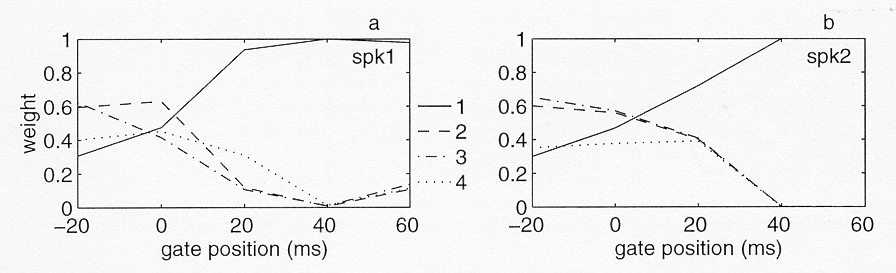
Figure 7. Dimension weights for the 4-dimensional ALSCAL solution for the backward-gated stimuli for speaker 1 (7a) and speaker 2 (7b).
3.2 Information theoretical analysis
3.2.1 Method
As argued earlier, it is the goal of the study presented in this
paper to describe the temporal distribution of perceptually relevant
information for consonant recognition. This objective is achieved
most directly by calculating transmitted information (TI)
as a function of gate position. Usually such analysis is carried
out in terms of distinctive features (e.g. Miller & Nicely,
1955). Many coding schemes of consonants in terms of distinctive
features are possible, however, and it would seem that the suitability
of competing feature-coding schemes for describing a data set
is equally dependent on the particular acoustic manipulation adopted
in the stimulus preparation as on properties of the human speech
perception system. In particular the grouping of consonants according
to place of articulation differs greatly between authors and experiments.
For example, the palatal fricatives 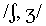 are sometimes assigned
to the "back" place of articulation, along with velar
consonants, sometimes to a "mid" category, along with
alveolars, while at other times they are allocated a separate
place category (for discussions, see Wang and Bilger, 1973; Singh,
1975). The multidimensional scaling study described in the previous
section suggests that a relatively straightforward and intuitively
appealing coding scheme is suitable for the analysis of the current
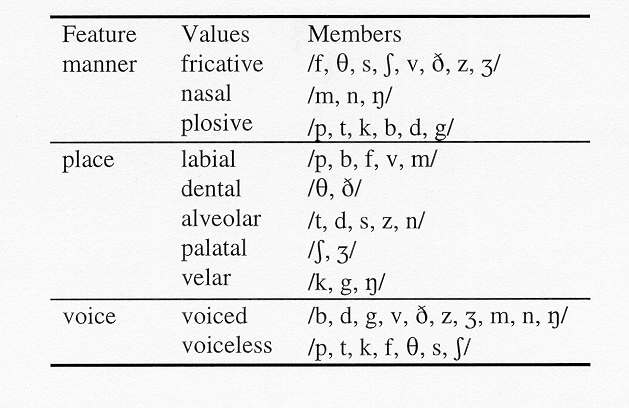
data set. This coding scheme is given in table I.
are sometimes assigned
to the "back" place of articulation, along with velar
consonants, sometimes to a "mid" category, along with
alveolars, while at other times they are allocated a separate
place category (for discussions, see Wang and Bilger, 1973; Singh,
1975). The multidimensional scaling study described in the previous
section suggests that a relatively straightforward and intuitively
appealing coding scheme is suitable for the analysis of the current
data set. This coding scheme is given in table I.
Table 1. Feature coding scheme used in the analysis of information transmission.
TI for place was calculated separately for fricatives, nasals, and plosives, because the ALSCAL analyses, as well as past speech perception studies (e.g. Jongman, 1989; Repp, 1986; Smits et al., 1996) indicate that place information is distributed differently along the time dimension for the three manner classes. As for place of articulation, TI for voicing was calculated separately for fricatives and plosives.
In order to have measures of location and spread of consonantal
information along the time axis directly available for statistical
testing, it was considered useful to fit a parametric curve to
each set of TI points for 9 gates, and enter the estimated parameters
into a MANOVA. After inspecting the general shape of the TI-versus-time
curves it was decided to fit the following 4-parameter sigmoid-based
model to the data:
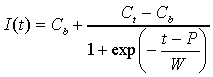
where I represents transmitted information, t represents time (gate position), Cb and Ct represent the bottom and top asymptotes of the sigmoid function, and P and W represent the position and width of the sigmoid, respectively. For the data for the forward-gated stimuli W is positive, for backward-gated data W is negative. For the purpose of interpretation I introduce the concept of equivalent width We of the sigmoid function I(t). We is defined as the interval between the two points where the tangent of I(t) in the point t=P intersects the bottom and top asymptotes of I(t). This leads to We=4W.
In order to be able to carry out statistical tests for the influence of feature, vowel, stress, speaker and listener on the TI-versus-time curves, 288 separate fits were made of the function defined in (1) to the forward-gated data, and 288 to the backward-gated data. Function (1) generally fitted the TI-versus-time data very well. The RMS error computed across all sigmoid fits was 5.2%. In 23 out of the 288 fits for the forward data the position and width parameters assumed meaningless values because the TI values for all gates were very close to zero. These parameter values were not used in the statistical analysis.
Separate MANOVAs were carried out on the forward and backward data, with the parameters Cb, Ct, P and W as dependent variables and feature, vowel, stress, speaker and listener as independent variables. Listener was defined as a random factor nested under speaker and stress. All two-way and three-way interactions between feature, vowel, stress and speaker as well as the two-way interactions feature×listener and vowel×listener were used in the MANOVA model. Besides calculating separate ANOVAs for all dependent variables, the MANOVA also tests for the significance of main effects and interactions on the 4 dependent variables simultaneously.
3.2.2 Results
3.2.2.1 Descriptive data.
Before the results of the statistical analyses are given, first
some summary data are
presented. Figure 8 gives the percentage transmitted information
as a function of gate position for the forward- and backward-gated
stimuli. Here, TI is calculated on the basis of a number of 17×17
consonant confusion matrices pooled across vowel, stress, speaker
and listener.
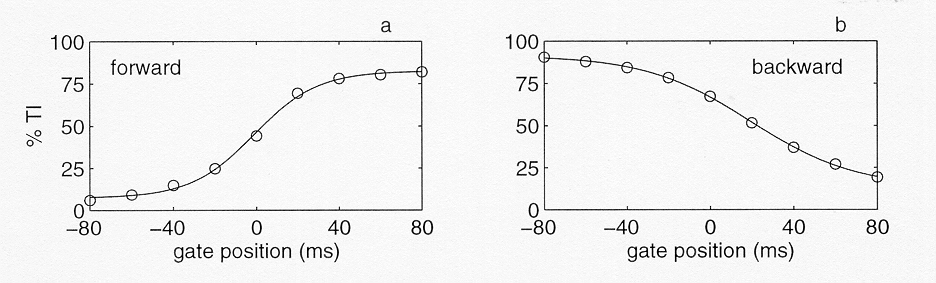
Figure 8. Percentage transmitted information as a function of gate position for the forward-gated (a) and backward-gated (b) stimuli. The solid lines represent the sigmoid function fitted on the data. The origins on the time axes are set to coincide with the relevant landmarks.
Figure 9 represents the percentage transmitted information as a function of gate position for the forward- and backward-gated stimuli calculated separately for the earlier defined distinctive features. Again, the classification data were pooled across vowel, stress, speaker and listener. As in figure 8, solid lines indicate the fitted sigmoid functions. Figures 9a and b suggest that manner information becomes available very abruptly around closure and more gradually around release. The distribution of place information (9c and d) is more similar around closure and release. In both cases place information for fricatives is more spread-out than for plosives and nasals. Figure 9d suggests furthermore that the transition regions of plosives are more informative on place than those of nasals and fricatives. Finally, figures 9e and f show large differences in voicing perception for plosives and fricatives. Voicing information for plosives seems to be largely cued by the formant transitions after release. For fricatives, on the other hand, voicing perception seems to be based almost exclusively on the frication portion between the two landmarks.
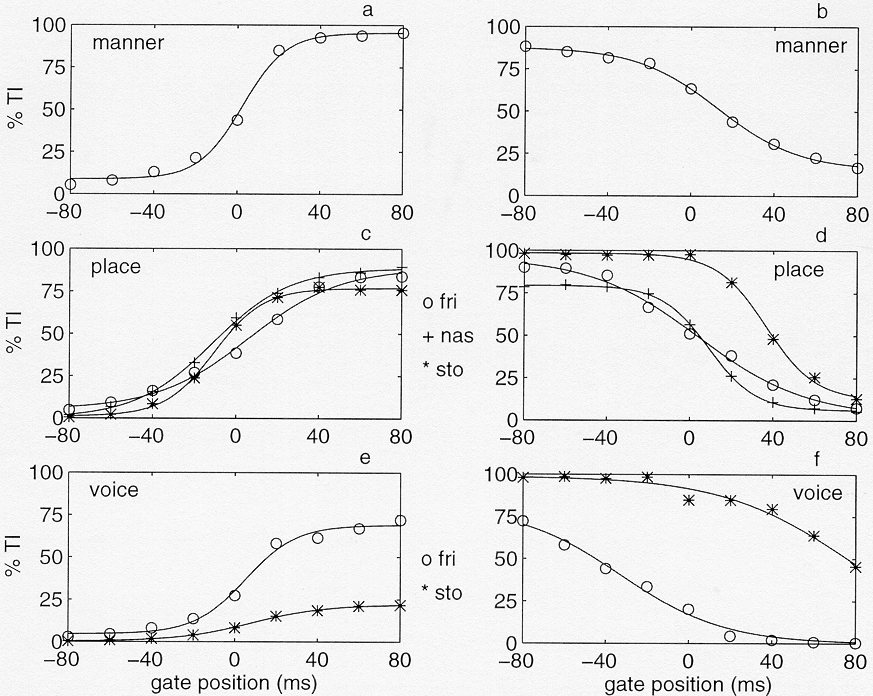
Figure 9. Percentage transmitted information as a function of gate position for the forward-gated (a, c, e) and backward-gated (b, d, f) stimuli, calculated separately for the manner place and voice. Again, the solid lines represent the sigmoid functions fitted on the data and the temporal origins coincide with the relevant landmarks. "fri", "nas" and "sto" indicate fricatives, nasals and stops, respectively.
3.2.2.2 Statistical analyses.
The MANOVA on the parametrized sigmoid functions for the forward-gated
stimuli (around closure) showed that vowel, feature, and listener
were highly significant main effects (p<0.0001). Speaker was
not significant (p>0.2), neither was stress (p>0.7). The
only significant interactions were speaker×feature (p<0.0001),
stress×feature (p<0.01) and listener×feature (p<0.0001).
Figure 10 shows the means of dependent variables position and
width for all main effects, except listener.
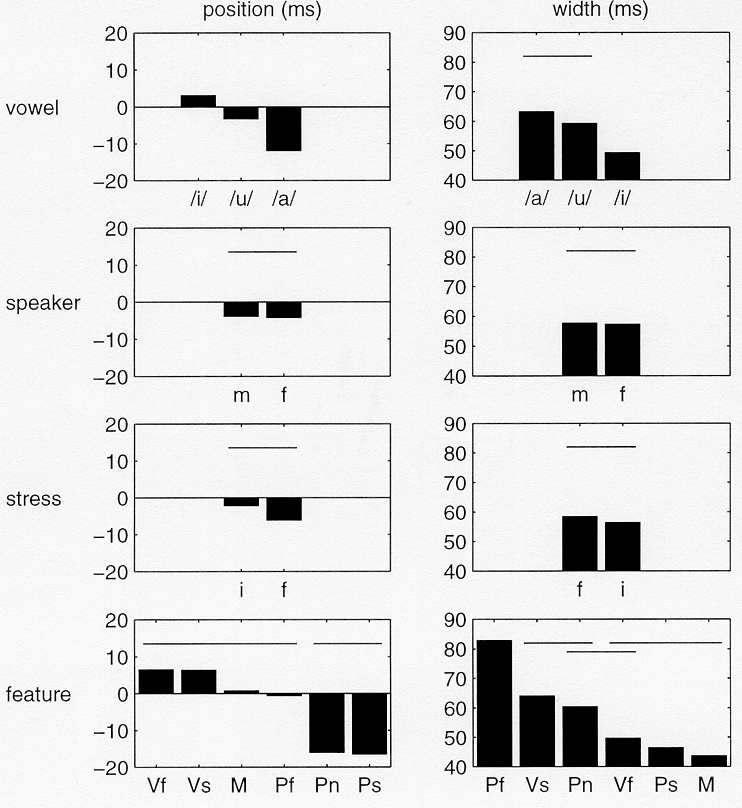
Figure 10. Forward-gated stimuli: Means of position and equivalent width, both expressed in ms, of the sigmoid functions for the as a function of the factors vowel, speaker, stress, and feature. Non-significant differences, as revealed by Duncan post-hoc tests, are indicated by lines above the bars. Male and female speaker are indicated by "m" and "f", initial and final stress by "I", "f", manner, place for fricatives, nasals and plosives, and voicing for fricatives and plosives are indicated by M, Pf, Pn, Ps, Vf, Vs, respectively.
The MANOVA on the data for the backward-gated stimuli (around release) showed that vowel (p<0.0001), speaker (p<0.005), stress (p<0.04), feature (p<0.0001), and listener (p<0.0001), that is, all main effects, were significant. The only significant interactions were speaker×feature (p<0.0001), speaker×stress×feature (p<0.04) and listener×feature (p<0.0001). Figure 11 shows the means of dependent variables position and width for all main effects.
Overall, the effects of vowel context, speaker identity and stress on the position and width of the information distributions around closure and release are small. Although the effect of vowel is significant for both position and width around closure, the effect is not large (in the order of 10ms). The effects of speaker identity and stress, which are only significant for position around release, are even smaller. By far the most striking effect is that of feature. Around closure, the perceptually relevant information on place for nasals and plosives is available earlier than information on all other features. Place information for plosives and nasals is concentrated around roughly 15ms before closure, while information for other features is concentrated around roughly 5ms after closure. Place information for fricatives is more spread-out than that for other features. The equivalent width of the sigmoid representing the place information for fricatives is some 80-odd ms, while the equivalent width for the other features is roughly 50ms. Around release the situation is different. As noted in the multidimensional scaling analysis, voicing information for plosives is available well into the second syllable. On average the information is concentrated around 70ms after release. Information on place in plosives is concentrated at 40 ms after release.
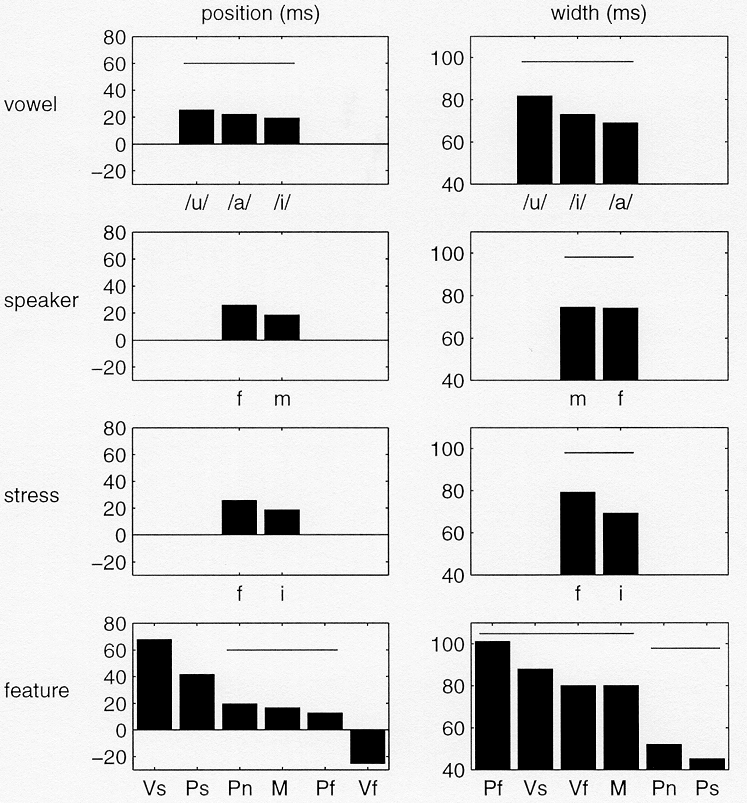
Figure 11. As Figure 10, but for the backward-gated stimuli.
Information on place in nasals and fricatives and on manner is located at roughly 15ms after closure, and voicing information for fricatives is located some 25ms before closure. The equivalent width of place information for plosives and nasals is roughly 50ms, while that for the other features is almost 90ms.
Finally, in order to get an easily interpretable summary of the results of the above analysis, the average of the sigmoid parameters was calculated separately for the six features (manner, place for fricatives, nasals and plosives, and voicing for fricatives and plosives). The time derivatives of the resulting sigmoid functions for closure and release were summed, taking into account the average interval between closure and release for the relevant feature. The resulting "information density" functions (expressed in %TI/ms) are presented in Figure 12. Note that the functions plotted in figure 12 are quite different from the derivatives of the functions plotted in figure 9. The functions in figure 9 were calculated on the basis of data pooled across vowel, stress, speaker and listener. The functions in figure 12, on the other hand, were calculated on the basis of averages of the parameters of the sigmoid functions fitted to separate data sets for vowel, stress, speaker and listener.
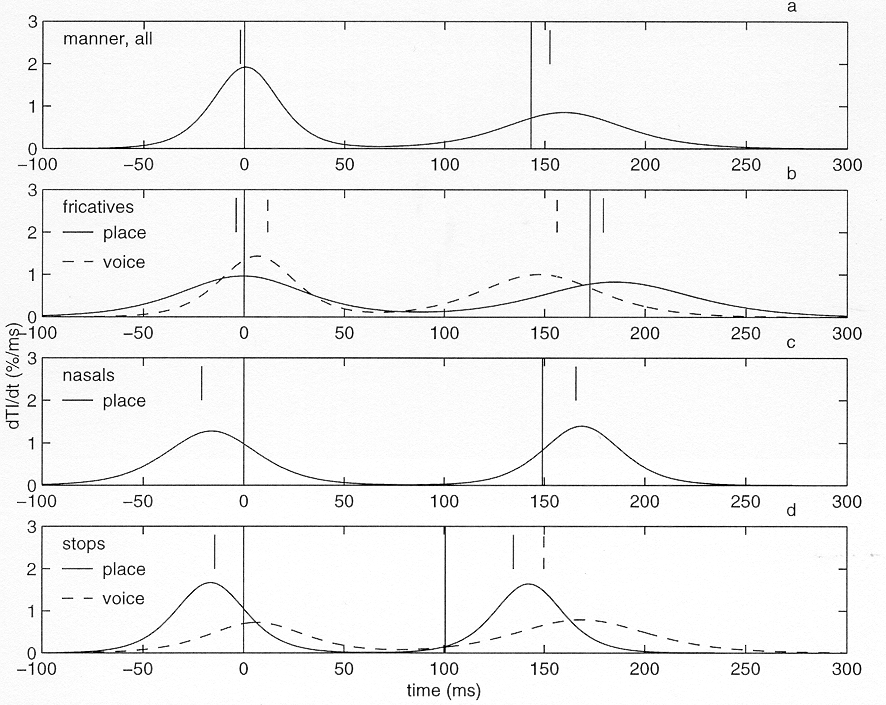
Figure 12. "Information density functions". Derivatives of the sigmoid functions specified by the average of the sigmoid parameters for the six features (manner, place for fricatives, nasals and plosives, and voicing for fricatives and plosives). The time derivatives of the resulting sigmoid functions for closure and release were summed, taking into account the average interval between closure and release for the relevant feature. The vertical lines in the figure represent closure and release landmarks, and the line segments above the functions indicate the 50%TI points for the various functions.
Although figure 12 gives a useful summary of the experimental data, it needs to be interpreted with care. In the gating experiments cumulative portions of the VCVs were presented to listeners (albeit in random order). As a result, points on the left-hand part of the "information density" functions in figure 12 represent the information growth at a point in time, given that the preceding part of the speech signal is available. Similarly, points on the right-hand part of the functions give the information growth given that the following part of the speech signal is available. Therefore, if the middle portion of a function (between the two landmarks) is close to zero, this does not mean that there is no perceptually relevant information in that part. It just means that it contains no information in addition to the information in the preceding or following part.
4. General discussion
The present study investigated the temporal distribution of perceptually
relevant information for consonant recognition in British English
VCVs. The information distribution in the vicinity of consonantal
closure was measured by presenting forward-gated portions of naturally
produced VCV utterances to listeners for identification. Backward-gated
stimuli were used to study information distribution around release.
The classification data from the experiment were analysed in two ways. First a three-way multidimensional scaling analysis was carried out. This provided highly interpretable, 4-dimensional geometrical representations of the confusion patterns in the data. It was found that, for backward-gated as well as forward-gated stimuli, the dimensions of the stimulus space were associated with distinctive features. For both types of gating, two dimensions were associated with manner of articulation and voicing, while the two other dimensions were associated with place of articulation.
The patterns of confusions were different for the two types of gating. The forward-gated stimuli (focusing on consonantal closure) were clustered as plosives, nasals and fricatives. In the fricative group, voiced and voiceless fricatives were slightly separated. The backward-gated stimuli (focusing on release) were clustered as unvoiced plosives, nasals and other consonants, while the other-consonants group was divided into a subgroup containing /b, g/ and a subgroup containing all fricatives plus /d/. With respect to place of articulation, the forward-gated stimuli could be more or less separated into the three groups labial+velar, dental+alveolar, and palatal, while the backward-gated stimuli could be subdivided into labial, dental, alveolar, and palatal+velar. For both types of gating, the stimuli were distributed much more evenly along the place dimensions than along the manner/voicing dimensions.
The patterns of confusions made explicit in the multidimensional scaling representations were used to define a set of distinctive features to be used in further analyses. These were manner, place, and voicing, where place and voicing were analysed separately per manner class. The subsequent analysis consisted of 3 steps. First the percentage TI as a function of gate position was calculated separately for different features, vowels, syllable stress, speaker and listener. Next, a sigmoid function was fitted to each of 288 sets of TI data thus obtained for each type of gating. Finally, the sigmoid parameters were entered into MANOVAs which tested the influence of feature, vowel, stress, speaker and listener on the position and width of the distribution of perceptually relevant information for consonant identity. It was found that, although vowel, stress, speaker and listener had significant effects on the distribution of information, feature was the dominant factor both in backward and forward gating. This means that the location and spread of the information is very different for the different distinctive features. I will briefly review the major findings reported in earlier studies and compare these to the findings of the current study.
Closure
Far fewer studies have been done on information distribution around
consonantal closure than around release. Öhman's gating study
on Swedish VCCVs (Öhman, 1966) showed an overall rapid rise
in correct manner identification when signal portions after
closure becomes available. Plosive manner was well identified
for all gates, probably because truncated voiced utterances generally
sound like stop closures. The instant of most rapid increase in
correct identification of fricative manner is about 30ms after
closure, while for nasal manner it is roughly at closure.
Place information from only closure transitions seems to be comparable for fricatives, nasals and plosives. When portions after closure become available, correct place identification for fricatives slowly rises, for nasals rapidly rises, and for plosives hardly rises at all (Malécot, 1958; Öhman, 1966; Sharf and Hemeyer, 1972; Pols, 1979; Ohde and Sharf, 1981; Schouten and Pols, 1983; Recasens, 1983; Repp and Svastikula, 1988).
The main source of voicing information around closure for plosives is the presence or absence of a voice bar (Lisker, 1978), but the use of this information by listeners seems to be different in different languages. Swedish listeners make good use of this information, resulting in rapidly growing correct voicing recognition when portions after stop closure are presented (Öhman, 1966). American English listeners, on the other hand, do much worse with similar signal portions (Malécot, 1958). Not much is known about voicing perception in intervocalic and postvocalic fricatives. Öhman (1966) showed that correct voicing identification increases rapidly with increasing postvocalic frication portions, reaching near-perfect levels when about 50ms of frication after closure is included. This is corroborated by Jongman's (1989) finding that voicing identification in initial portions of syllable-initial frication noise reaches its ceiling at a duration of about 60ms.
The present study shows that, around closure, place information
for nasals and plosives is available earlier (instant of maximum
increase roughly 15ms before closure), than information on any
other features (instant of maximum increase roughly 5ms after
closure). This generally agrees with the findings discussed above,
where correct manner as well as voicing identification was reported
to increase at or after closure. The increase in information transfer
for fricative place in our data is somewhat later than in earlier
studies, where it was found that pre-closure formant transitions
were equally informative for the different manners of articulation.
Possibly, this discrepancy is caused by using 4 (rather than 3)
distinct fricative places of articulation, and assigning the consonants
to a separate place class (palatal) rather than the velar
class (Öhman, 1966, for example, assigned palatal and velar
consonants to the same place class). The present study also showed
that the information distribution for fricative place is wider
(equivalent width of 80ms) than that of any other feature (on
average 50ms). This also agrees with the findings of earlier studies.
Finally, the present study shows that British English listeners
have great difficulty in identifying plosive voicing when only
signal portions preceding release are available, that is, they
hardly make use of the information present in the voice bar during
closure. Inspection of the individual data revealed that there
were great differences between subjects in this respect. Some
listeners simply classified all forward-gated plosives as unvoiced,
while others did a reasonable job in identifying plosive voicing.
The American English listeners tested by Malécot (1958)
seemed generally to be doing somewhat better than our listeners,
while Öhman's (1966) listeners appeared to make very effective
use of the voice-bar information. The difference with the Swedish
listeners may be caused by Öhman's V-plosive-V utterances
being unaspirated (Swedish plosives are aspirated only in stressed
syllables), which necessarily shifts the perceptual weight to
other cues, such as the presence or absence of a voice bar. In
the present study, all voiceless plosives were aspirated.
Release
The understanding of information distribution around release is
better developed than around closure, although this is mostly
based on studies with CV rather than VCV utterances. The gating
study by Öhman (1966) showed that correct manner identification
changes abruptly around release, with nasal manner changing roughly
at release, fricative manner changing before release and plosive
manner after. Other studies indicate that fricative-vowel syllables
with frication removed and nasal-vowel syllables with murmur removed
are generally perceived as plosives (Manrique and Massone, 1981;
Kurowski and Blumstein, 1984; Repp, 1986).
A large number of experiments have shown that removal of the release
burst has a significant effect on correct place identification
in plosives (Sharf and Hemeyer, 1972; Pols, 1979; Ohde and Sharf,
1981; Schouten and Pols, 1983; Smits et al, 1996). Additional
truncation of portions of the subsequent formant transitions results
in a rapid decline in correct place identification, reaching chance
level at about 100ms after release (Öhman, 1966; Pols, 1979;
Furui, 1986). For correct place identification in fricatives,
the frication portion is generally thought to be of greater importance
than the formant transitions, except for the distinction between
/f/ and (Harris, 1958). However, the level of correct place
perception in fricative-vowel syllables from the vocalic portion
only is comparable to place perception for the same portion in
(voiced) plosive-vowel syllables (Sharf and Hemeyer, 1972; LaRiviere
et al, 1975; Manrique and Massone, 1981; Jongman, 1989). For place
identification in nasals it is generally found that the formant
transitions are somewhat more informative than the nasal murmur,
although the murmur does carry significant perceptual weight.
However, a very short signal portion around release including
both some murmur and some of the formant transitions is enough
for good place recognition. Again, place recognition from transitions
alone is comparable to plosive transitions (Kurowski and Blumstein,
1987; Repp, 1986).
Many cues around release are perceptually relevant for voicing identification in plosives, but VOT is generally dominant (Lisker, 1978). Gating studies generally show that if the instant of voicing onset is not included in the stimulus, the level of correct voicing identification is low. When increasing portions preceding the instant of voicing onset are included, correct identification gradually increases. The situation for fricatives is similar in that correct voicing identification gradually increases when increasing portions of frication (preceding release) are included.
In the present study it was found that, when increasing portions of the final part of the VCVs were presented, first plosive voicing information becomes available (70ms after release), then plosive place (40ms after release), then manner and nasal and fricative place (15ms after release) and finally fricative voicing (25ms before release). This partially agrees with findings reported in the literature. Plosive voicing being available well after release agrees with the reported finding that some information preceding voicing onset is generally enough for correct voicing identification. The finding that place information is available further after release for plosives than for fricatives and nasals seems somewhat contradictory to earlier studies reporting that the place information in post-release transitions is similar for plosives, nasals and fricatives. However, while for fricatives and nasals the formant transitions start at release, plosives have a burst between the instants of release and (voiced or aspirated) transitions, which roughly accounts for the 25ms difference. With respect to the spread of information for the various features, the present study found that the width of the information distribution for plosives and nasals (50ms) is greater than for other features (90ms). The fact that the place distribution is wider for nasals and plosives than for fricatives is supported by earlier studies. An explicit comparison with the manner and voicing features does not seem to be available in the literature, though.
Acknowledgements
This research was supported by a grant from NATO and the Netherlands
Organisation for Scientific Research (NWO) and by a Marie Curie
fellowship granted by the European Commission. I am grateful to
Valerie Hazan and Stuart Rosen for help, encouragement and very
useful discussions.
References
Furui, S. (1986) On the role of spectral transition for speech
perception. Journal of the Acoustical Society of America 80,
1016-1025.
Grimm, W.A. (1966) Perception of segments of English-spoken consonant-vowel syllables. Journal of the Acoustical Society of America 40, 1454-1461.
Grosjean, F. (1980) Spoken word recognition processes and the gating paradigm. Perception & Psychophysics 28, 267-283.
Harris, K.S. (1958) Cues for the discrimination of American English fricatives in spoken syllables. Language and Speech 1, 1-7.
Jongman, A. (1989) Duration of frication noise required for identification of English fricatives. Journal of the Acoustical Society of America 85, 1718-1725.
Kurowski, K., and Blumstein, S.E. (1987) Acoustic properties for place of articulation in nasal consonants. Journal of the Acoustical Society of America 81, 1917-1927.
LaRiviere, C., Winitz, H., and Herriman, E. (1975) The distribution of perceptual cues in English prevocalic fricatives. Journal of Speech and Hearing Research 18, 613-622.
Liberman, A.M., Cooper, F.S., Shankweiler, D.P., and Studdert-Kennedy, M. (1967) Perception of the speech code. Psychological Review 74, 431-461.
Lisker, L. (1978) Rapid vs. rabid: A catalogue of acoustic features that may cue the distinction. Haskins Laboratories Status Report on Speech Research SR-54, 127-132.
Liu, S. (1996) Landmark detection for distinctive feature-based speech recognition. Journal of the Acoustical Society of America 100, 3417-3430.
MacCallum, R.C. (1977) Effects of conditionality on INDSCAL and ALSCAL weights. Psychometrika 42, 297-305.
Malécot, A. (1958) The role of releases in the identification of released final stops. Language 34, 370-380.
Manrique, A.M.B. de, and Massone, M.I. (1981) Acoustic analysis and perception of Spanish fricative consonants. Journal of the Acoustical Society of America 69, 1145-1153.
Miller, G.A., and Nicely, P.E. (1955) An analysis of perceptual confusions among some English consonants. Journal of the Acoustical Society of America 27, 338-352.
Ohde, R.N., and Sharf, D.J. (1981) Stop identification from vocalic transition plus vowel segments of CV and VC syllables: A follow-up study. Journal of the Acoustical Society of America 69, 297-300.
Öhman, S.E.G. (1966) Perception of segments of VCCV utterances. Journal of the Acoustical Society of America 40, 979-988.
Pickett, J.M., Bunnell, H.T., and Revoile, S.G. (1995) Phonetics of intervocalic consonant perception: Retrospect and prospect. Phonetica 52, 1-40.
Pols, L.C.W. (1979) Coarticulation and the identification of initial and final plosives. In: J. Wolff and D. Klatt (Eds.), ASA 50 Speech Communication Papers, New York: Acoust. Soc. Am., 459-562.
Recasens, D. (1983) Place cues for nasal consonants with special reference to Catalan. Journal of the Acoustical Society of America 73, 1346-1353.
Repp, B.H. (1986) Perception of the [m]-[n] distinction in CV syllables. Journal of the Acoustical Society of America 79, 1987-1999.
Repp, B.H., and Svastikula, K. (1988) Perception of the [m]-[n] distinction in VC syllables. Journal of the Acoustical Society of America 83, 237-247.
Schouten, M.E.H., and Pols, L.C.W. (1983) Perception of plosive consonants - The relative contributions of bursts and vocalic transitions. In: M.P.R. van den Broecke, V.J.J.P. van Heuven, and W. Zonneveld (Eds.), Sound structures: Studies for Antonie Cohen, Dordrecht: Foris, 227-243.
Sharf, D.J., and Hemeyer, T. (1972) Identification of consonant articulation from vowel formant transitions. Journal of the Acoustical Society of America 51, 652-658.
Singh, S. (1975) Distinctive features: A measure of consonant perception. In: S. Singh (Ed.), Measurement procedures in speech, hearing and language. Baltimore: University Park Press, 93-155.
Smits, R., Ten Bosch, L., and Collier, R. (1996) Evaluation of various sets of acoustical cues for the perception of prevocalic stop consonants: 1. Perception experiment. Journal of the Acoustical Society of America 100, 3852 - 3864.
Soli, S.D., and Arabie, P. (1979) Auditory versus phonetic accounts of observed confusions between consonant phonemes. Journal of the Acoustical Society of America 66, 46-59.
Stevens, K.N. (1995) Applying phonetic knowledge to lexical access. Proc. Eurospeech 95 vol.1, 3-11.
Stevens, K.N., and Blumstein, S.E. (1981) The search for invariant acoustic correlates of phonetic features. In: P.D. Eimas and J.L. Miller (eds.), Perspectives on the study of speech, Hillsdale: Lawrence Erlbaum Associates, 1-39.
Suomi, K. (1985) The vowel dependence of gross spectral cues to place of articulation of stop consonants in CV syllables. J. Phonetics 13, 267-285.
Takane, Y., Young, F.W., and de Leeuw, J. (1977) Nonmetric individual differences multidimensional scaling: An alternating least squares method with optimal scaling features. Psychometrika 42, 7-67.
Wang, M.D., and Bilger, R.C. (1973) Consonant confusions in noise: a study of perceptual features. Journal of the Acoustical Society of America 54, 1248-1266.
Appendix A. Durations of consonantal closure
The duration of consonantal closure is defined as the interval
between the closure and release landmarks. The average duration
of consonantal closure across all original utterances was 143
ms. An ANOVA was carried out on the closure durations for all
original utterances. The factors consonant, vowel, speaker, and
stress were used in the analysis, as well as all possible interactions.
All main effects were highly significant (p<0.001). So were
all interactions, except speaker×stress (p=0.2), stress×vowel
(p=0.4), and speaker×stress×vowel (p=0.2). Bonferroni
post-hoc comparisons of means revealed that:
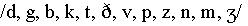 (90, 94, 98, 103, 104,
108, 115, 116, 125, 131, 133, 138 ms, respectively) < (183ms) <
(90, 94, 98, 103, 104,
108, 115, 116, 125, 131, 133, 138 ms, respectively) < (183ms) <
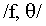 (210, 212 ms, respectively) <
(210, 212 ms, respectively) <
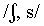 (230, 243
ms, respectively). Note that the first group, with the shortest
durations, contains all plosives, voiced fricatives and the nasals
/m, n/, while the last 2 groups contain the voiceless fricatives.
Inspection of means for the two-way interactions showed that the
nasal being significantly longer than the other nasals is mainly
caused by one of the speakers.
(230, 243
ms, respectively). Note that the first group, with the shortest
durations, contains all plosives, voiced fricatives and the nasals
/m, n/, while the last 2 groups contain the voiceless fricatives.
Inspection of means for the two-way interactions showed that the
nasal being significantly longer than the other nasals is mainly
caused by one of the speakers.
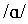 (138 ms) < /i, u/ (144, 147 ms, respectively).
(138 ms) < /i, u/ (144, 147 ms, respectively).
© Roel Smits
 for comments
for comments