8. Suprasegmentals
Key Concepts
- Suprasegmental effects occur over a hierarchy of domains: turns, prosodic phrases, feet, syllables.
- Syllables can be made more prominent through changes in duration, articulatory quality or pitch. These are often called changes in "stress" or "accent".
- Some languages have pitch movements that help identify words, called "lexical tone".
- The intonation of a phrase provides pragmatic information which guides the listener towards the intended interpretation.
- Speech prosody is an active research area with its own experimental methods for quantifying supra-segmental effects.
Learning Objectives
At the end of this topic the student should be able to:
- describe the different domains over which suprasegmental effects are commonly described
- explain what is meant by "stress" and how it causes changes in prominence
- describe how prominence is achieved through pitch accents
- explain what is meant by a tone language and give an example
- explain the main characteristics of intonation in English
- perform pitch analyses of passages and sentences in the laboratory
Topics
- Suprasegmental Domains
Suprasegmental effects in phonetics operate over a number of different domains: some over stretches of the signal that are syllable-sized, others over domains of many syllables. The most important domains are defined below:
- Syllable: while syllables seem intuitive elements of speech production, it has proven hard to give them a proper definition. We will use a typical phonological definition in terms of a collection of segments arranged in the form of nuclear and marginal elements. The nuclear elements at the centre of the syllable are sonorants, typically vowels. The marginal elements are consonants. So a typical syllable is a vowel surrounded by zero or more consonants. Since the nuclear elements are sonorants, they will be produced with a relatively unobstructed vocal tract and so be a bit louder than the marginal elements on average. This gives the listener the feeling that syllables are 'pulses' of sound, although it has proved difficult to build an algorithmic procedure that parses the signal into syllables.
- Prosodic foot: the prosodic foot is a domain of timing or rhythm. It is of particular value in languages that exploit a difference between "stressed" and "unstressed" syllables. A foot is a sequence of syllables containing a stressed syllable followed by zero or more unstressed syllables (Note: this definition is at odds with the definition of 'metrical foot' used in poetry, which is about the pattern of strong and weak beats in a line of poetry). We can see this domain operating when the size of the prosodic foot is changed. When additional unstressed syllables are added to the end of a foot, the duration of the foot does not increase proportionately. For example, [stɪk] is longest in "stick", shorter in "sticky" and shorter still in "stickiness". This "foot-level shortening" binds the stressed and unstressed syllables together and creates a tendency for prosodic feet to occur at more regular instances of time than they would otherwise - in other words it enforces a certain rhythmical pattern.
- Prosodic phrase: when we speak long utterances, we naturally break them up into parts, just as when we write, we use punctuation to break up long sentences into digestible sections.
- Dialogue Turn: interesting suprasegmental effects occur over domains longer than prosodic phrases. The introduction of a new topic in a conversation can be marked by a general increase in pitch, while the end of a dialogue turn can be indicated by changes in speaking rate, lowering of pitch and creaky voice.
Syllables are domains for allophonic variation, for example plosives are only aspirated in syllable-initial position. They are also domains for stress: compare "content" as [kənˈtent] meaning "pleased", compared to [ˈkɒntent] meaning "contained material". Syllables are domains for timing, with segmental durations varying depending on their position in the syllable and the complexity of the syllable structure. Syllables are also the natural domains of pitch movements: lexical tone and pitch accent as described below.
The term "prosody" | refers to certain properties | of the speech signal ||
This "prosodic phrasing" has multiple functions: it helps the speaker plan the upcoming material, it helps the speaker take breaths, and it helps the listener chunk the material into units for interpretation. In some instances, the phrasing can help the listener choose between alternative interpretations:
One of the ways in which listeners work out the syntactic or grammatical structure of spoken sentences is by using prosodic cues in the form of stress, intonation, and so on. For example, in the ambiguous sentence 'The old men and women sat on the bench,' the women may or may not be old. If the women are not old, then the spoken duration of word 'men' will be relatively long and the stressed syllable in 'women' will have a steep rise in speech contour. Neither of these prosodic features will be present if the sentence means the women are old. (M. Eysenck and M. Keane, Cognitive Psychology. Taylor & Francis, 2005)
The IPA chart recognises two levels of phrase break: major and minor. These may be marked by pauses or intonation, but also may be marked solely by changes in duration that occur leading up to the boundary, "phrase-final lengthening".
The prosodic phrase is also the domain over which intonational tunes operate, see below.
One thing that is interesting about this list of domains is that none clearly align with domains of morphology or syntax. Few suprasegmental phenomena operate at the level of words (word-level tone being an exception) and word boundaries are not generally marked by segmental or suprasegmental features. Similarly prosodic phrases do not always align well to syntactical constituents, and prosodic phrases can both subdivide clauses or contain multiple clauses.
One last comment: don't view suprasegmental phenomena as structure imposed on top of the segmental string. You will see in the examples above how information flows both ways. Sometimes the suprasegmental domains define segmental effects (e.g. allophonic variations that depend on syllable position), sometimes segmental effects define suprasegmental domains (e.g. amount of segmental material makes domains longer). The division between segmental and suprasegmental phenomena is a convenient one for the phonetician, but a spoken utterance always has both segmental and suprasegmental properties, since it is still a single articulated entity.
- Prominence
Not all segments, syllables, words and phrases are equal. Speakers make parts of words more prominent in order to help listeners discriminate them from other words. Speakers also change the relative prominence of parts of an utterance to direct the listener to elements which are new, unusual or important. The means for changing prominence are usually described under the headings "stress" and "pitch accent".
Stress
Many languages in the world differentiate "stressed" and "unstressed" syllables. English content words, for example, are made up of a pattern of strong and weak syllables, for example "over", "supper", "China" and "broken" are all of the pattern strong-weak, while "ahead", "before", "suppose" and "career" are of the pattern weak-strong. The strong or stressed syllables tend to be longer in duration and better articulated than the weak or unstressed syllables. (The combination of these two effects should not surprise you given the discussion of undershoot from last week).
When words are composed into utterances, the stress pattern of the words in the lexicon is largely carried over into the stress pattern of the utterance. However there are some interesting exceptions. Grammatical words (function words) tend not to be stressed, although you always have the freedom to stress them for emphasis: "I WAS right!". Also the lexical stress pattern is altered on some words when they are combined into common compounds or phrases. So for example "afternoon" [ɑːftəˈnuːn] becomes [ˈɑːftənuːn] in "afternoon tea". These stress changes in context can be idiosyncratic and hard to predict and a particular difficultly for foreign learners.
Languages vary in how much they realise differences between stressed and unstressed syllables. English has a large difference in prominence between stressed and unstressed syllables, while Italian has a smaller difference (or none). It is sometimes said that languages with a large difference have a "galloping" rhythm, while languages with a small difference have a "machine-gun" rhythm. Experimental research has investigated whether languages can be separated on rhythmical grounds, and whether the difference is due to some underlying phonological cause.
It can be hard to determine what makes stressed syllables more prominent. We observe that stress makes syllables longer and that they are better articulated, but is the increased duration due to the additional time needed for better articulation, or is the better articulation a consequence of increased duration? Although many authorities claim stressed syllables are louder, it is not easy to find evidence of this in the acoustic signal. It is possible that the more peripheral vowel quality, longer duration, greater pitch movement and more modal voice quality in stressed syllables combine to make them appear louder to the listener.
Pitch accent
Another way in which elements of the utterance can be made more prominent is to change their pitch: either by increasing the pitch on the target element compared to its neighbours, or by causing a change in pitch through the element. This change in pitch level makes the given syllable, word or phrase more salient to the listener. When pitch movements occur on or close to stressed syllables, they are sometimes given the name "accented syllables". We shall just use the term "pitch accent" for any kind of functional pitch movement.
Pitch accents are used to demonstrate focus - where the speaker wants the listener to pay particular attention to one meaningful component of the phrase, for example:
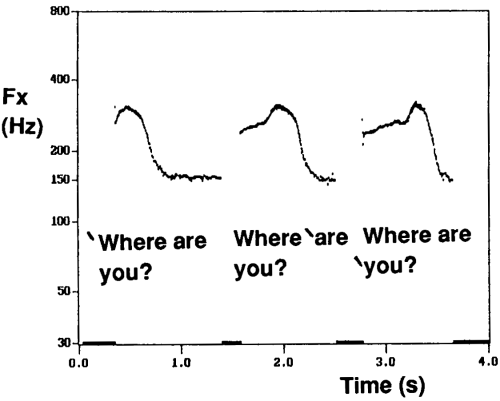
This use of pitch accents can be seen to help the listener choose between alternative interpretations of the utterance.
Sometimes a difference can be made between broad focus and narrow focus. Typically broad focus extends over multiple words and is simply confirming a choice, as in:
"Did you see a grey dog or a cat?" "I saw a grey dog."
While narrow focus is limited to specific information:
"Did you see a grey dog or a grey cat?" "I saw a grey dog."
Contrastive focus is when the speaker makes prominent parts of a phrase in order to demonstrate a misunderstanding by the listener. For example "I wanted the red pen not the blue one". It is a demonstration how prosody is influenced by the pragmatics of dialogue.
- Lexical tone
We have seen how English has "lexical stress" - a marking on words in the mental lexicon which identify some syllables as strong and others as weak.
Some languages have "lexical tone" - a marking on words in the mental lexicon which identify some syllables as having different pitch heights or different pitch movements. In such "tone languages", words can be differentiated by pitch alone.
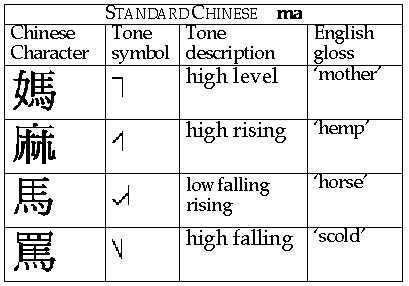
The standard example of a tone language is Chinese, although many east Asian languages and a substantial portion of the languages found in Africa, the Americas and Papua New Guinea have lexical tone. The four Chinese words "ma" can be used to demonstrate the four tones in Chinese:
And you can listen and practise:
In contrast to Chinese which has a syllable-level tone system, a few languages, such as Swedish and Norwegian are said to have a word-level tone system.
In standard Swedish (Stockholm area) accent I, also referred to as acute, is realized by an essentially level or rising F0 in the syllable carrying primary stress, whereas accent II, the grave accent, is realized by a falling F0 in the primary syllable. [Kruckenbeg, 1989]
Thus the two words spelled "anden" can be pronounced [ɑ́nden] "the duck" or [ɑ̀nden] "the spirit".
Above we noted that when words are combined into utterances, lexical stresses can move or change. The same is true of lexical tone. The changes in tone, however, seem surprisingly rule governed, and they have been actively studied. Rule-governed change in lexical tone in sequences is called tone sandhi. For example:
"When there are two 3rd tones in a row, the first one becomes 2nd tone,
and the second one becomes a half-3rd tone. E.g. 你好 (nǐ + hǎo = ní hǎo)" - Intonation
Pitch movements that occur over the domain of a whole prosodic phrase and which are related to the function or meaning of the whole phrase are called "Intonation". The intonation of a phrase provides additional information to the listener about its intended meaning, whether for example the speaker is certain about the facts expressed, or is requesting a response from the listener.
Note: there is no single widely-accepted phonological model of intonation, i.e. no agreement on the basic contrastive elements of intonation or on rules for their combination. Some models treat intonation as a sequence of contrasting high and low tones, others as a superposition of pitch accents and phrasal accents. We present here a model proposed by O'Connor and Arnold (1973) in which the intonation of a prosodic phrase is divided in up to four parts:
- The pre-head - all the initial unaccented syllables.
- The head - between the pre-head and the nucleus.
- The nucleus - the main accented syllable.
- The tail - all the syllables after the nucleus.
O'Connor and Arnold then identified 10 different intonational patterns with different meanings. We present a simplified account of some of these below.
The primary intonational distinction in English is between falling and rising pitch patterns expressed on the last lexical stress in the phrase. This is called the "nuclear accent" or "nuclear tone". A falling nuclear tone indicates to the listener that the phrase is complete or definite:
- She lent him her \CAR
- Would you leave the \ROOM
- Do be \QUIET
Note that b. is grammatically a question, but is spoken as a command. A rising nuclear tone indicates to the listener that the phrase is open-ended or indefinite, usually inviting a response:
- She lent him her /CAR (really?)
- Would you leave the /ROOM (polite request)
- Do be /QUIET (lack of authority)
Tonal options of rise and fall can be combined to create rising-falling and falling-rising contours in which the rise can cancel or qualify the definiteness of the fall:
- She doesn't lend her car to \ANYone (falling - definite statement)
- She doesn't lend her car to /ANYone (rising - querying the fact)
- She doesn't lend her car to \/ANYone (falling+rising - qualified statement)
A context for the last might be: "she only lends her car to close friends".
Differences in interpretation can also be found to depend on the size of the fall or rise. A high-falling tone is more definite than a low-falling tone.
We can summarise some common communicative functions and their typical implementation in terms of changes in pitch:
Function Communicative task Typical intonation pattern Example statement convey information low falling it's ˎraining. binary question answer yes/no, agree/disagree, true/false low rising it's ˏraining? wh-question ask for specific information high falling who are ˋyou? alternatives-question choose from list rising on first item, falling on last item ˏred, green and ˎblue. exclamation emphatic statement high falling it's ˋraining! conditional statement agree but with conditions falling-rising I ˇwill (but) challenge express certainty rising-falling I've told you beˆfore. non-final I haven't finished level and a-nother thing Other intonational functions include an indication of attitude ("good ↘morning" is friendlier than "good ↘morning"), and of supporting prosidic phrasing ("the red planet, as it's known, is fourth from the sun"). The pitch movements chosen to implement intonational functions can vary across accents, e.g. the contemporary use of a high-rising terminal pitch ("uptalk") to represent statements by some younger speakers.
You can practise listening to and identifying nuclear tones using the On-line Intonation Practice pages.
Some other aspects of intonation:
- Although the nuclear tone is often associated with the last lexical stress in the prosodic phrase, its execution can continue across any subsequent unstressed syllables to the end of the phrase. This element is sometimes called the "tail" of the contour.
- Although the default location for the nuclear tone is on the last lexical stress, it can move if earlier elements are put into focus: "I have \TWO brothers in Canada". In such a case the tail has a reduced pitch range which re-inforces the earlier word focus ("post-focus compression").
- Imposed on the general pitch contour is an expectation that the pitch will slowly decline anyway while speaking, perhaps as a consequence of a slow fall in sub-glottal pressure as the speaker's breath runs out. This expected declination can mean that even level tones can be interpreted as rising.
- Laboratory methods
There are a number of laboratory techniques which are useful in the study of suprasegmental effects. These include:
- Annotation: It has proven very useful in phonetic research to annotate speech signals such that the location of segments, syllables and phrases may be found automatically. Such labelling of the signal allows for the large-scale analysis of the phonetic form and variation in the realisation of phonological segments, and has been the basis for much experimental phonetics research as well as for technological applications such as speech recognition and speech synthesis.
- Pitch track: methods exist for estimating the fundamental frequency from a recorded speech signal. From this we can derive a fundamental frequency contour or "pitch track". A pitch track shows how the pitch of the voice changes through an utterance which is a key aspect of its intonation. When we look at an Fx contour we can see many features: (i) changes in fundamental frequency that are associated with pitch accents; (ii) the range of Fx used by the speaker; (iii) voiced and voiceless regions; and (iv) regular and irregular phonation.
- Fundamental frequency statistics: We have seen how a pitch track can be estimated from a speech signal. In week 4 we also saw how individual pitch epochs can be located. Once such measurements have been made, it is then possible to calculate summary statistics of fundamental frequency use. So that such statistics are descriptive of the typical speaking habits of the speaker, it is common practice to analyse a read passage of at least 2 minutes in duration.
- Distribution of fundamental frequency is a histogram of how much time was spent by the speaker at each pitch level.
- Mean, median or modal fundamental frequency are measures of the average fundamental frequency (mean=centre of distribution, median=50th percentile, mode=most commonly used).
- Range of fundamental frequency is a measure of the breadth of the distribution. This can be measured as the standard deviation (if the distribution is bell-shaped) or in terms of the distance between certain percentiles.
- Percentage regularity is a measure of what percentage of time the speaker was using regular phonation, i.e. for what fraction of time were glottal cycles similar in duration to their neighbours.
Unfortunately the manual labelling of speech signals with time-aligned annotations is slow, expensive and error-prone. Thus a number of automatic "phoneme alignment" tools are now available which automatically make an alignment between a phonological transcription and the recorded signal. While such tools may not make as good an alignment as human labellers, the fact that they are automatic means that much larger quantities of material can be annotated.
The Speech Filing System (SFS) tools contain an automatic alignment tool, demonstrated below:
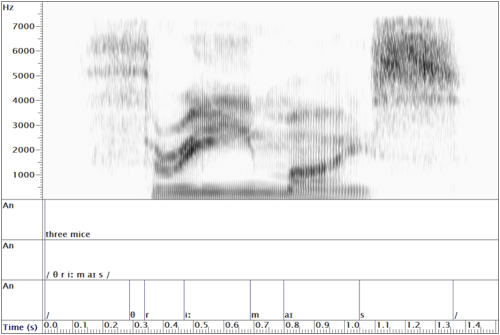
To extract parameters from the pitch track it is common practice to first model the shape of the contour. A common strategy is to sylise the changes in pitch with a sequence of simple shapes, e.g. straight lines:
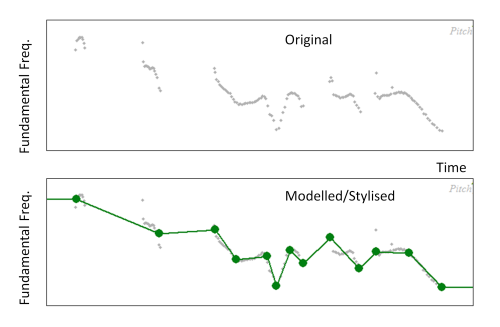
The stylised contour can now be represented in terms of the height and slope of a set of pitch segments.
From the analysis of a passage we an calculate such summary statistics as:
These can be seen in the figure below:

Readings
Essential
- Ladefoged & Johnson, A Course in Phonetics, Wadworth, 2010. Chapter 10: syllables and suprasegmental features.
Background
- Clark, Yallop & Fletcher, An introduction to phonetics and phonology, Blackwell, 2006, Chapter 9 Prosody. [available in library].
Laboratory Activities
In this week's lab class we will look at intonation using your recordings of a passage and a couple of sentences:
- Distributional analysis of read passage
- Analysis of pitch contour of sentence and question
- Prosody manipulation of a statement into a question
- Prosody manipulation of focus
Research paper of the week
Generating Intonation from Text
- Hirose, K.; Fujisaki, H.; Yamaguchi, M., "Synthesis by rule of voice fundamental frequency contours of spoken Japanese from linguistic information" in Acoustics, Speech, and Signal Processing, IEEE International Conference on ICASSP '84. , 9, 597-600, 1984.
This was one of the first papers that described what is now known as the "Fujisaki" model of intonation. The goal of the model was to generate acceptable intonation contours from text. The solution involved a superposition of two pitch movements, one related to the domain of the phrase (phrase commands) and one to the domain of pitch accents within a phrase (accent commands). Rules connected elements of the input text to the firing of the pitch commands, and a mathematical model combined the phrase commands with the accent commands to generate a smooth F0 contour.
The abstract explains the study:
A number of utterance samples of complex sentences of Japanese were analyzed using the model for the process of fundamental frequency contour generation, with special emphasis on the relationship between a fundamental frequency contour and its underlying lexical, syntax and semantic information. Phrase commands of the model were found to be roughly classified into three groups according to the level of corresponding node of the syntactic tree of a sentence, while accent commands were found to be roughly classified into two groups according to the type of accentuation. A set of rules was constructed for generating fundamental frequency contours of complex sentences of Japanese from linguistic information. Perceptual tests of naturalness of intonation using synthetic speech with rule-generated fundamental frequency contours indicated the validity of the rules.
The figure below shows the model being used to generate a (Japanese) sentence. The phrase commands are drawn as arrows which represent pitch shifts associated with phrase boundaries, while the accent commands are shown as blocks with a given height (strength) and width (duration). The "Glottal Oscillation Mechanism" component applies constraints on the rate of pitch change modelled on how fast the larynx can change pitch. This mechanism integrates the two types of pitch commands to create the actual F0 frequency contour. The dotted lines shows the output with only the phrase commands active.
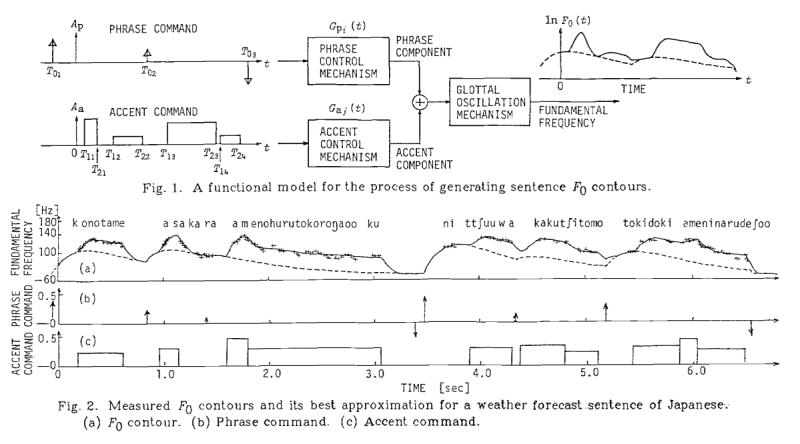
Fujisaki went on to apply the model to many different languages, while other authors looked at automatically generating the underlying commands from the surface contour as a means to "understand" intonation.
Application of the Week
This week's application of phonetics is the automatic generation of the prosody of speech from text in text-to-speech (TTS) conversion systems.
Last week we saw that in so far as segmental elements of speech were concerned, we could build new utterances by gluing together excerpts from existing utterances as long as the excerpts were chosen to match the pronunciation required and as long as they fitted together well.
When reading a new piece of text, a TTS system needs to identify the prosodic structure of the spoken form so that (i) it can select the best matching elements from the corpus, and (ii) it can ensure that the meaning of the utterance is adequately conveyed to the listener.
The pronunciation and lexical stress for words can be found from a dictionary. But the sentence-level prosody: the prosodic phrasing and intonation need to be derived from an analysis of the sentence itself.
Automatic prosodic phrasing
The task in automatic prosodic phrasing is to accept a written text, with punctuation, and to divide it into major and minor prosodic units to emulate the phrasing of human readers. Generally, it is not sufficient just to put prosodic phrase boundaries at punctuation. Partly this is because styles of punctuation vary widely among authors, but also because stretches of text between punctuation marks can still be rather too long to speak as one prosodic group.
When people have studied where human readers place phrase boundaries, it is seen that although one aspect of the choice is to do with meaning (and hence syntactically coherent constituents) another aspect is to do with size and complexity. So a short and simple verb phrase may be spoken as one prosodic unit, while in a long and complex verb phrase, the verb, objects and adverbials might be in different units.
We can describe approaches to automatic prosodic phrasing under three headings:
- Heuristics: a heuristic method is one that works on the basis of some simple rules that have been designed through experience to work well in the general case. One example is the "chinks and chunks" method (See Liberman & Church reading). Each word in the string is marked as either a chink (typically a function word) or a chunk (typically a content word), then phrases are simply sequences of function words (chinks) followed by sequences of content words (chunks). For example:
I asked them | if they were going home | to Idaho |
and they said yes | and anticipated one more stop |
before getting home.It is not difficult to create sentences which are not parsed well by such an algorithm, but that is to miss the point. As long a such an algorithm does not produce objectionable parses, then it can be quite acceptable by users.
- Syntactical: a syntactical method first attempts to create a parse tree for the text (typically one per sentence) then employs some kind of rule to decide which syntactic boundaries are also phrase boundaries. A difficulty, as mentioned above, is that there is no consistent alignment between constituents and phrases. On the whole the prosodic structure is much shallower than the syntactic structure. While the syntactic structure may support multiple embedding, human readers find it hard to exploit more than one level of embedding in the spoken form ("My sister, who also lives in Chicago, has three daughters"). Since a detailed parse of an arbitrary sentence is hard to obtain and since the mapping from parse to prosodic units is difficult, most TTS systems only bother to make a simple parse of the text - sufficient to identify constituent phrase boundaries rather than the relationship between the constituents.
- Statistical: a statistical method is one that has been trained from a corpus of labelled speech. Typically a corpus of read sentences is annotated to identify major and minor pauses. Then some machine-learning algorithm is then applied to the text to try and predict which word boundaries are also phrase boundaries. The machine-learning system might use various properties of the words, such as their position in the sentence, their grammatical class, the number and type of words before and after the word in the string. The output of a statistical method is typically the probability of a phrase break at every word boundary. A search algorithm is then applied to find the best sequence of phrase breaks for the sentence that satisfies some simple criteria, such as average phrase length and most probable boundary locations.
Automatic generation of intonation
There are two stages to generating an intonation contour for a prosodic phrase: (i) deciding the location and type of pitch accents; and (ii) generating a suitable fundamental frequency contour.
It is important to realise that when a TTS system reads a text, it does not understand what it is saying. The system knows about the relationship between words and sounds, but not anything about how language is used to communication meanings and intentions. So although any phrase may have many different possible intonational readings depending on how and when it is used, a TTS system has no means to choose between them. The solution is for the system to use a "default" or "neutral" reading for every phrase. Typically this will be to produce a falling, rising or level nuclear tone on the last lexical stress in the phrase. Falling tones are used for the last phrase in a sentence, rising for the last phrase in a yes/no question, and level tones everywhere else. It is not hard to create a sentence for which such a strategy is inappropriate. Consider the contrastive stress example above. This intonation is just confusing:
Give me the red pen not the blue \ONE. *
What is the solution to this fundamental problem in TTS? I think that we are just wrong in thinking that machines are capable of reading text. Instead we need to ask them to build sentences which convey a given meaning. So instead of text, we give the systems some semantic representation of what we want it to say, and let the system design both the sentence and the prosody at the same time. This area of research is called Natural Language Generation.
Given a specification for which tones are required on which syllables we can now generate a fundamental frequency contour. There are two main strategies for this: a superpositional model, in which pitch movements for the phrase and for pitch accents are superposed to generate a composite contour, and a tone sequence model, in which a sequence of tone movements are connected together in sequence using some kind of smoothing/interpolation from one to the next. The Fujisaki model described in Research Paper of the Week is perhaps the most well-known super-positional model.
Further Readings on TTS Prosody
- Julia Hirschberg, Speech Synthesis, Prosody, Encyclopedia of Language and Linguistics, 2005. A readable high-level overview of the issues.
- Mark Liberman and Ken Church, Text Analysis and Word Pronunciation in Text-to-speech Synthesis, Advances in speech signal processing (1992) 791-831. A more technical discussion of how text-to-speech systems deal with text.
- Alex Fang and Mark Huckvale, Synchronising Syntax with Speech Signals, Speech, Hearing and Language, Work in Progress, UCL, 1996. Description of a syntactic method for predicting pauses.
Language of the Week
This week's language is Standard Chinese as spoken by a young woman from Beijing. [ Source material ].

Details of tone changes in context:

- Identify the phones used in the Chinese passage above not found in SSBE.
- The Chinese tone Sandhi rules listed above seem very complex. How do speakers learn what to do?
Reflections
You can improve your learning by reflecting on your understanding. Come to the tutorial prepared to discuss the items below.
- Why is it hard to define a syllable in phonetic terms?
- What might affect where you put phrase boundaries in a long sentence?
- How can you make a word stand out in a phrase?
- What is declination? Why does it arise?
- What is the difference between "unstressed", "stressed" and "accented" syllables?
- How might focus be indicated in a language with lexical tone?
- How might a statement/question difference be indicated in a language with lexical tone?
Word count: . Last modified: 10:27 03-Dec-2017.