Wells, A study of the formants of the pure vowels of British English [SAMPA] [Unicode]
Subjects were seated in an anechoic chamber about four feet from a microphone and asked to read a list of test sentences twice through. Their utterances were reported on a Reflectograph tape-recorder running at 7½ i.p.s., from which they were later also played back into the spectrograph.
There were twelve test sentences, each consisting of the frame: "Number... The word is ..." plus one of the words heed, hid, head, had, hard, hod, haw'd, hood, who'd, Hud, heard, hide. The first eleven of these exemplify the vowels /i ɪ ɛ æ ɑ ɒ ɔ ʊ u ʌ ɜ/. It had been found that subjects tended to use a special intonation, with associated changes in amplitude and duration, for the last sentence in a list; so an extra dummy sentence with hide was added to the sentences containing the vowels being studied.
The frame /h-d/ is particularly suitable for studies of English vowels, since (i) /h/ has so little influence on following vowels, and (ii) it so happens that a real English word results for nearly every "pure" vowel in this sequence.
Subjects were requested to use the same intonation (low-fall) for each of the sentences, and this intonation was demonstrated to them; it is, however, unrealistic to expect people - particularly people without phonetic training - to be able to restrict themselves at will to one same intonation-pattern for twelve consecutive sentences, and they did not usually do so. Instead, one or more of the sentences were usually given a high-fall or low-rise intonation. One subject regularly user an intonation-pattern with two nuclear tones, one on "word" as well as one on the test word.
The whole list of sentences was recorded twice over, giving two samples of each of the eleven vowels for each subject.
Twenty-five subjects were used, two lecturers and twenty-three students of University College or the School of Oriental and African Studies of the University of London. All were male, aged 18 or over, and speakers of that dialect of British English generally known among phoneticians as RP (Received Pronunciation) and referred to by the layman in such terms as "speaking perfect English" or "speaking English without any accent". That is, there were no regional characteristics in their speech which might suggest what part of England they came from (but see p. 37). This dialect enjoys very high social prestige in England and the Commonwealth; perhaps the major group of RP speakers consists of those English families whose men-folk are educated at public schools [23 p. 3-4; 20 § xv ff].
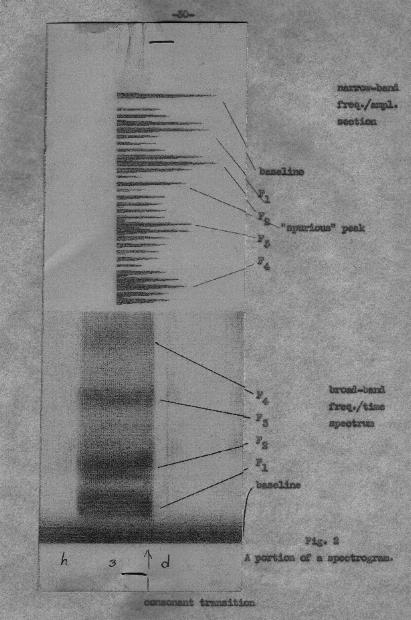
The actual test words (recorded on magnetic tape) were excised from their carrier sentences and spliced together to make a tape consisting of nothing but the 550 test words. Broad-band spectrograms were then made of the whole of this tape by means of a spectrograph built by SRDE Christchurch and JSRU Eastcote (see Acknowledgements). A narrow-band frequency/amplitude section ws also made at a point within the duration of each vowel, as far as possible at the mid-point of the vowel, so as to avoid consonant transitions, but sometimes slightly earlier or later if the formant structure was not well-marked at the midpoint. Each part of the spectrogram, the frequency/time display and the frequency/amplitude section, covered the range from zero to about 3500 or 4000 cps. Each spectrogram represented a stretch of about four seconds, and so accommodated two to five test words.
Measurements of formant frequency and relative amplitude (formant level) were made from the narrow-band sections, except where a formant frequency could not be determined from the section, in which case it was measured, where possible, fromthe broad-band spectrum display. Measurements of duration were made from the frequency/time spectrogram.
It happened from time to time that the section was made at a moment in the vowel duration that was evidently not typical of the vowel. This may often have been due to inconstancies in the larynx tone. Such a section could be seen to be untypical by comparison with the frequency/time spectrogram; usually one or more formants were missing, or very poorly defined, or at unlikely frequencies, or there was no proper formant structure apparent at all. In cases where such factors made it impossible to measure the formant frequencies from the section, it was discarded and the frequencies were measured from the frequency/time spectrogram instead; the centre of a formant was judged by eye, and its distance from the baseline measured.
Particular vowels are regularly characterized by formants at or around certain frequencies. Sometimes, however, it happened that in addition to the normal formants at the expected frequencies there were other apparent formants at other frequencies. On occasion, indeed, the unexpected, "spurious" formants were of greater intensity than one or even both of the "genuine" formants on either side. In particular, several instances of /ɑ/ occurred where there was a "spurious" formant between F2 and F3, in the region of 1700-1800 cps. Peterson [34] has found this feature to be typical of nasalized [ɑ̃], compared with oral [ɑ]. With a few instances of /ʌ/ and /ɜ/ it was difficult to decide which of two rival formants was genuine and which spurious. No doubt the ear would average the two if they were close together.
One speaker has a great deal of "incidental" nasalization, that is nasalization that was neither intentional nor linguistically relevant, but was presumably caused by the speaker's inability to make a tight closure between the soft palate and the pharyngal wall at the entrance to the nasal cavity. As might be expected, in the spectrograms of the vowels pronounced by this speaker there were numerous "spurious" formants: nasality of vowels is regularly manifested in the presence, among other things, of extra peaks and troughs in the spectrum [25 p.95-96]. The first formant often appeared to be split into two peaks.
Figure 2 shows an example of a spectrogram of the word heard /hɜd/.