
Abstract
An experiment was performed to test the perceptual benefits for
non-native listeners of enhancing consonantal regions which contain
a high density of acoustic cues to phonemic contrasts in English.
Groups of Spanish-L1, Japanese-L1 and native English listeners
heard nonsense VCV material produced by two different speakers
and composed of 12 consonants presented in two vocalic contexts.
Both natural and enhanced versions of these stimuli were presented
in a background of speech-shaped noise at 0 dB SNR. All three
groups of listeners obtained significantly higher intelligibility
scores for the enhanced VCVs. They also showed similar speaker
effects. Consonant intelligibility scores are discussed in relation
to the confusions expected on the basis of the phonological system
in the listeners' L1.
1. Introduction
Second language (L2) learners may experience great difficulty
in discriminating and identifying phonemes which are different
to those in their native language. Flege, in his SLM model suggests
that if L2 phonemic categories are too similar to L1 categories,
they will be assimilated to these categories, and new "language-appropriate"
L2 categories will not be formed. The ability to acquire non-native
contrasts is therefore dependent on the nature of the phonetic
contrast itself and the relation between L1 and L2 (e.g., Flege,
1995). Other factors which affect the ability to acquire new phonemic
categories are age of learning and extent of L2 exposure (for
a review see: Strange, 1995).
Non-native listeners have also be found to be more affected by noise and reverberation than native listeners. These studies have typically been carried out with L2-learners who were functioning at a very high level of proficiency and obtaining similar scores as native listeners in quiet. For example, using the Modified Rhyme Test (six-alternative forced choice word identification), Takata and Nabelek (1990) found that Japanese-L1 and native listeners obtained near-ceiling scores in quiet, but scores reduced by 19% for the native listeners in conditions of degradation and by 25% for the Japanese-L1 listeners. Florentine (1985) (cited in Takata and Nabelek) also found that fluent L2 listeners were adversely affected by the presence of noise when perceiving sentence material and that they were less efficient at using contextual information than native listeners. In a more recent study, Florentine and her colleagues extended their study by controlling the factor of age of acquisition in these highly-fluent L2 learners (Mayo, Florentine and Buus, 1997). They found significant differences in the perception of sentences in noise between early (before 6) and late learners (after 14) of English although all scored at least 96% correct in quiet.
The issue of the perception of noise-degraded speech is very much at the core of our concurrent work on cue-enhancement. In this work, we increase the salience of specific acoustic cues in clear speech in order to make the signal more robust to subsequent degradation by noise (e.g. Hazan and Simpson, 1996). Significant increases in intelligibility have been reported for native listeners presented with cue-enhanced speech in noise. As non-native listeners find perception of speech degraded by noise especially problematic, it appeared worthwhile to test the effect of our cue-enhancement techniques on this population as well. In order not to confound the effects of both acoustic and contextual information, these listeners were tested on consonant perception using nonsense word material which is devoid of contextual information.
The main aims of this study were to investigate: (a) whether L2 learners would benefit from cue-enhancement and whether the extent of any benefit differed from that obtained with native listeners; (b) whether L2 learners would show the same vowel and talker effect as native listeners and (c) whether factors such as L1 background, age of learning (AOL) and length of L2 learning (LOL) would be related to the effect of enhancement. In order to evaluate the effect of L1 background on the perception of enhanced English consonants, two subject groups were selected: one of native Japanese listeners and one of native Spanish listeners.
2. Test methodology
2.1 Subjects
The experimental group comprised 22 native Japanese listeners
and 16 native Spanish listeners who were attending a two-week
Summer School in English Phonetics within the Department. All
listeners had their permanent residence in their native country
and had never lived abroad for any significant amount of time.
They completed a short questionnaire which gathered information
about their first and second language background and self-assessment
of fluency and comprehension.
For the Japanese group, the median age was 19 years, the median age of L2 learning (AOL) was 13 years, and the median number of years of L2 study (LOL) was 7 years. On a range of 1 (poor) to 7 (excellent), their mean self-assessment of comprehension of English was 2.45 and of English fluency was 2.14.
For the Spanish group, the median age was 22 years, the median age of L2 learning (AOL) was 11 years, and the median number of years of L2 study was 11 years. On the same scale, their mean self-assessment of comprehension of English was 4.87 and of English fluency was 4.07.
Control data for the stimuli described below was obtained from a group of 18 native English listeners, all first year Speech Sciences students at UCL.
2.2 Test materials
24 vowel-consonant-vowel (VCV) stimuli comprising the consonants
/b,d,g,p,t,k,f,v,s,z,m,n/ in the context of the vowels /a,u/
were recorded by one male and one female speaker. Both speakers
were 29 years old, had south-east British English accents and
had not received any phonetic training. Stimuli were recorded
in an anechoic chamber and were digitised at a 16 kHz sampling
rate with 16-bit amplitude quantisation. Digitised stimuli were
then annotated using a waveform editing tool to mark the regions
for amplification.
When enhancing the stimuli, a distinction was made between the transition regions between vowel and consonant, and the consonantal constriction/occlusion regions, i.e. the burst transient, burst and aspiration, friction or nasality regions. For the transition regions, the reduced amplitude as the consonant constriction/occlusion was formed or released was counteracted by progressively amplifying the final five cycles of the first vowel, or the initial five cycles of the second vowel, by between 1 and 4 dB. The amplitude of the consonant occlusion/constriction region was amplified by either 6 or 12 dB according to consonant category, see below:
| Stops /b,d,g,p,t,k/ | Burst: +12dB Aspiration: +6dB | Transitions: +4 to +1dB |
| Fricatives /f,v,s,z/ | Friction: +6dB | Transitions: +4 to +1dB |
| Nasals /m,n/ | Nasality: +6dB | Transitions: +4 to +1dB |
After manipulation, stimuli were combined with noise which had the same spectral envelope as the long-term average spectrum of speech (conforming to CCITT Rec. G227 and produced by a Wandel and Goltermann RG-1 noise generator). A signal-to-noise ratio of 0 dB was calculated on a stimulus by stimulus basis and took into account any change in the amplitude of the stimulus produced as a result of enhancement. The noise started 200 ms before the onset of the first vowel and lasted 1.5 s, to ensure that all stimuli had the same duration. The noise was tapered using raised cosine ramps 100 ms in duration at the start and end of each stimulus.
2.3 Test procedure
Listeners were tested in a quiet classroom in groups with stimuli
presented through headphones at a comfortable listening level.
First, they were asked to complete the questionnaire and then,
the test itself was introduced in English by one of the experimenters.
Clarifications were given in the native language (Japanese or
Spanish) if necessary. After the explanations had been given,
listeners heard 20 examples of the VCVs before testing began.
L2 listeners heard two blocks of 192 stimuli containing randomly ordered natural and enhanced stimuli (four repetitions per token). They responded by writing their response on the grid provided. The twelve possible consonant responses were printed at the top of each sheet.
2.4 Results
a. Overall scores
Intelligibility scores were calculated for each listener. Mean
scores per listener group are presented in Figure 1. The mean
percentage differences between natural and enhanced conditions
were 6.1% (s.d. 3.2) for the Japanese group, 8.6% (s.d. 3.4) for
the Spanish group and 8.7% (s.d. 3.2) for the control (native
English) group.
Analyses of variance were carried out on the intelligibility data to test for the effects of test condition (natural vs. enhanced), language background (Spanish, Japanese or English) and speaker. The effect of test condition was significant [F(1, 53)=317.80; p<0.0001] with the enhanced stimuli receiving higher intelligibility scores than the natural stimuli. The interaction between test condition and L1-background was not significant which suggest that the three language-background groups did not differ significantly in the way in which they were affected by test condition.
The main effect of L1 background was significant [F(2,224)=90.32 p<0.0001] and Duncan's multiple range test showed that the three listener groups differed significantly from each other (in the following order: native listeners, Japanese-L1 listeners, Spanish-L1 listeners). Language-group scores do not therefore appear to be correlated with self-assessments of comprehension or fluency as these scores were higher for the Spanish-L1 group than for the Japanese-L1 group.
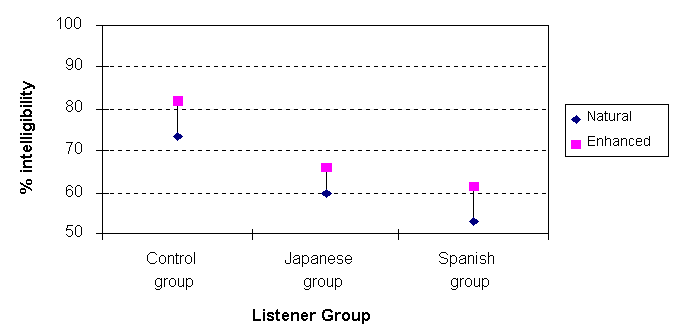
Figure 1: Mean intelligibility scores per listener group for the natural and enhanced test conditions
b. Effect of Speaker
Mean data is presented below for the three listener groups for
female speaker AO and male speaker MS. The effect of speaker was
significant [F(1,49)=230.75; p<0.0001] with female speaker
AO obtaining higher scores on average than male speaker MS. All
listener groups showed much higher increases in intelligibility
in the enhanced condition relative to the natural condition for
Speaker MS. The speaker effect was therefore similar whatever
the language background of the listener and whatever the intelligibility
score for the natural condition.
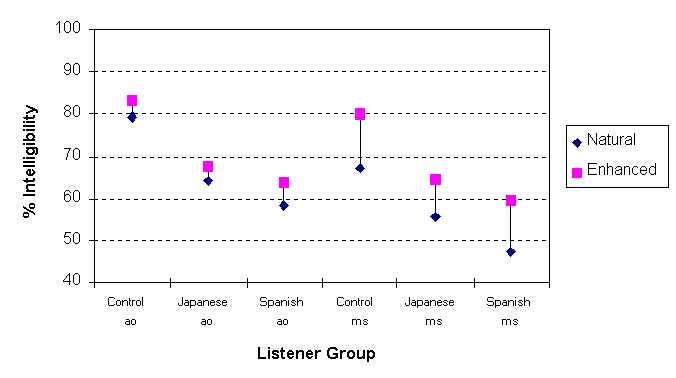
Figure 2: Mean intelligibility scores for Speakers AO and MS for all listener groups.
c. Effect of individual listener
As can be seen in Figure 3, the effect of enhancement was consistent
for a large majority of listeners: only two listeners showed less
than 2% improvement and none obtained lower scores for the enhanced
condition. Increases in intelligibility ranged from 0.5 to 12.2%
in the Japanese-L1 group, 3.2 to 16.25% in the Spanish-L1 group,
2.3 to 13.7 % in the control group.
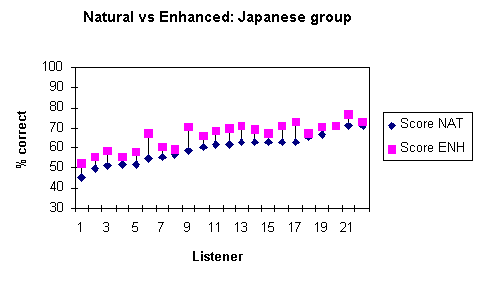
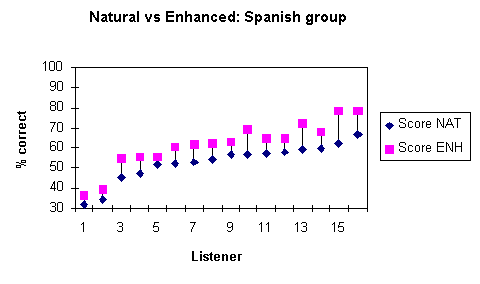
Figure 3: Intelligibility scores for individual listeners in the Japanese-L1and Spanish-L1 groups averaged over both speakers.
d. Effect of L1 background
In order to look at the effect of native-language background on
consonant intelligibility, it is necessary to examine the kinds
of features that might be confusable on the basis of the L1 background
and to see whether these were resolved as a result of the enhancements.
In order to aid this task, Information Transfer analyses (Miller
and Nicely, 1955; Wang and Bilger, 1973) were carried out in order
to determine how well consonants were recognised in terms of the
features of voicing, place and manner of articulation in the different
conditions.
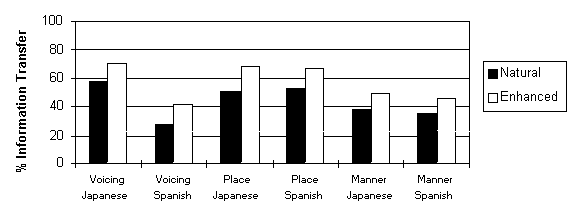
Figure 4: Information transfer scores showing the perception of place, manner and voicing features for Japanese-L1 and Spanish-L1 listener groups.
In Figure 4, it can be seen that overall, the information transfer score for the features of manner and place of articulation are remarkably similar across both groups of L2 learners. The greatest difference between the two listener groups was in the perception of voicing for which much lower scores were obtained for the Spanish-L1 group.
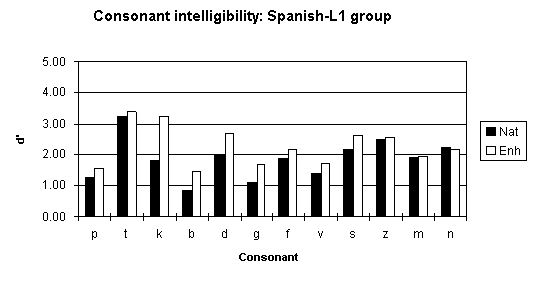
Figure 5: Intelligibility scores (d') for individual consonants for the Spanish-L1 group. These scores are averaged over speakers and vowel contexts.
For Spanish listeners, the following L1-linked confusions were predicted on the basis of the differences between the phonological systems of Spanish and English: voiced plosives perceived as voiceless plosives, /v/ confused with /b/, /z/ confused with /s/ as /z/ is an allophone of /s/. Aspirated plosives do not occur in Spanish so, according to Fleges's SLM model, it is more likely that the English /p,t,k/ phonemes would be acquired as new categories than the English /b,d,g/ which will suffer interference from the Spanish /p,t,k/ categories. In summary, low scores would be predicted for consonants /b,d,g,v,z/ as would an decrease in correct identification in terms of the features of voicing and manner of articulation relative to the control group. Intelligibility scores were transformed to d' measures, calculated as the difference between z scores for hits and false alarms for a given consonant (see Figure 5). These are shown in Table 1. Results show that the lowest ranked consonants were: /b,g,p,f,v/. Information transfer percentages (Wang and Bilger, 1973) obtained for the features of the voicing, place and manner of articulation show a large increase of voicing and manner errors relative to the control group (See Figure 4).
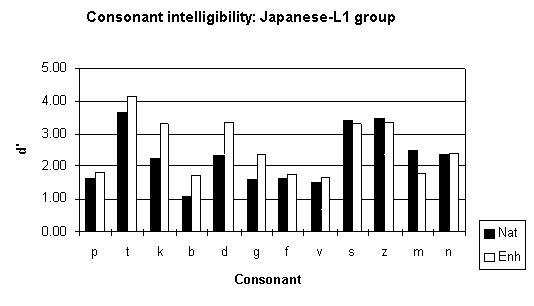
Figure 6: Intelligibility scores (d') obtained for individual consonants for the Japanese-L1 group. These scores are averaged over speakers and vowel contexts.
For the Japanese-L1 group, confusions would be predicted between
/b/ and /v/ as no such opposition occurs in Japanese; /f/ might
also be poorly identified as it only appears in loan-words. Other
consonants have similar phonological status in Japanese although
vocalic contexts may influence consonant intelligibility as certain
oppositions such as /du/-/zu/ are neutralised. In summary, low
scores would be expected for /b/,/f/,/v/ and the /b/-/v/ confusion
could lead to an increase in manner errors relative to the native
group. Results broadly confirm expectations: information transfer
scores for the manner feature around 25% lower than for the control
group (see Table 4) and the lowest ranked consonants were /b,f,v,g,p/
(See Figure 6).
The significant difference in consonant intelligibility found
between the Japanese-L1 and Spanish-L1 groups appears therefore
to be mainly related to greater confusion in the perception of
the voicing feature by Spanish listeners, due to the similarity
between English voiced and Spanish voiceless plosives.
Intelligibility scores for individual consonants for the native-listener group (see Figure 7) broadly replicate previous results with native listeners obtained with a different speaker (Hazan and Simpson, 1996)
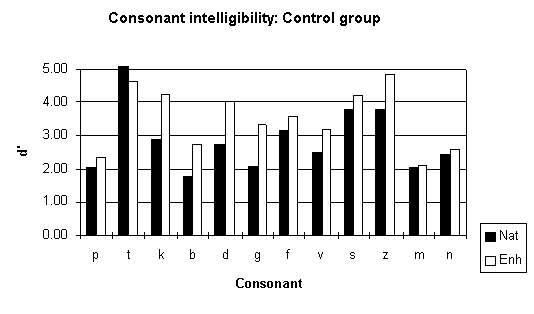
Figure 7: Intelligibility scores (d') obtained for individual consonants for the control group. These scores are averaged over speakers and vowel contexts.
The next question to address is the degree to which the enhancement techniques were successful in improving the intelligibility of individual consonants (see Figure 8). In all listener groups, the enhancement techniques were most successful in increasing the intelligibility of plosive consonants.
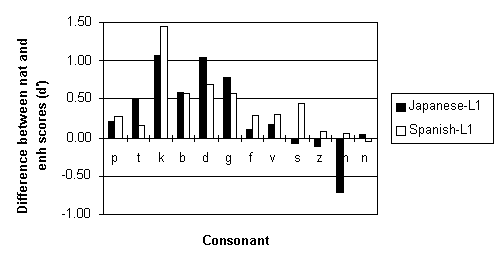
Figure 8: Difference in consonant intelligibility scores between the enhanced and natural conditions for Spanish-L1 and Japanese-L1 listener groups.
2.5Discussion
A first point to note is that the non-native listeners did indeed
obtain significantly lower scores than native listeners for this
simple consonant intelligibility task which did not involve any
lexical or other contextual knowledge. This occurred even though
the set of English consonants chosen did not include certain consonants
which are particularly problematic for L2 learners with these
L1 backgrounds (e.g. 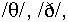 /l/ /r/). Nevertheless, the enhancements applied
did lead to a significant improvement in performance for both
groups of L2 listeners. These listeners showed the same speaker
effect as the native-English listeners: female speaker AO was
more intelligible than male speaker MS, but due to a greater effect
of enhancement for speaker MS, the difference between speakers
was considerably narrowed in the enhanced condition.
/l/ /r/). Nevertheless, the enhancements applied
did lead to a significant improvement in performance for both
groups of L2 listeners. These listeners showed the same speaker
effect as the native-English listeners: female speaker AO was
more intelligible than male speaker MS, but due to a greater effect
of enhancement for speaker MS, the difference between speakers
was considerably narrowed in the enhanced condition.
In trying to interpret consonant confusions in noise, it is important
to consider the interrelation between errors linked to the L1
background of the listener and errors linked to the noise degradation.
L2 listeners achieved scores close to those for native-listeners
for certain consonants such as the nasals /m,n/ which had similar
phonological status in their L1 but were performing predictably
worse than native listeners for consonants which had a different
phonological status in their native language. This occurred despite
the fact that these listeners had been learning English in their
native country for a minimum of 6 years, and in many cases considerably
more. This data supports the SLM model of Flege (Flege, 1995)
which predicts that the degree of difficulty in the acquisition
of non-native phonological contrasts will be related to the relation
between the phonological systems of the L1 and L2.
All listeners in this study can be considered to be 'late learners'
as they had started learning English after the age of 6. Their
AOL and LOL were too homogeneous within groups to be able to evaluate
the effects of these variables on consonant intelligibility
but it is noteworthy that the Japanese-L1 group generally obtained
higher scores despite having started learning English at a later
age, having a lower number of years of English education and lower
self-assessment scores of fluency and comprehension. This appears
to indicate that language-background factors, i.e. the disadvantage
of the Spanish-L1 group in terms of greater distance between the
phonological systems of the two languages, at least for the consonants
under investigation in this study, had a greater bearing on results
than listener factors such as length of study or age of learning.
This study therefore further demonstrates the difficulty of predicting
levels of performance of L2 learners due to the complex interrelation
of listener-related and language-related factors.
It is also noteworthy that our enhancement techniques lead to improved intelligibility by non-native listeners for consonants degraded by noise even though the listeners received no training nor prior exposure to these stimuli. This was achieved even though the enhancements themselves were based on our knowledge of acoustic cues used by native-listeners which may differ from acoustic cues used by L2 listeners. It is likely that enhancements more carefully targeted to L2 listeners and based on cue-weighting perceptual experiments with these listeners may be even more successful in improving intelligibility.
Acknowledgements
We wish to thank Dr Masaki Taniguchi and Dr Mercedes Cabrera-Abreu
for their help in recruiting participants in this experiment.
This work was funded by an EPSRC project grant (GR/L25639).
References
Flege, J.E. (1995) Second language speech learning: Theory, findings,
and problems. In W. Strange (Ed.) Speech perception and linguistic
experience. Baltimore: York Press.
Hazan, V. And Simpson, A. (1996) Enhancing information-rich regions of natural VCV and sentence materials presented in noise. Proceedings of International Conference of Speech and Language Processing, Philadelphia, October 1996, vol. 1, 161-164.
Simpson, A.S. and Hazan, V. (1997) Enhancing the intelligibility of VCVs in noise: speaker effects. Speech Hearing and Language:Work in Progress, vol. 10.
Jamieson, D.G. and Morosan, D.E. (1986) Training non-native contrasts in adults: Acquisition of the English /D/-/T/ contrast by francophones. Perception and Psychophysics, 40, 205-215.
Mayo, L.H., Florentine, M. and Buus, S. (1997) Age of second-language acquisition and perception of speech in noise. Journal of Speech, Language and Hearing Research, vol. 40, 686-693.
Miller, G.A. and Nicely, P.E. (1955) Analysis of perceptual confusions among some English consonants, Journal of the Acoustical Society of America, vol. 27, pp. 338-353.
Strange, W. (1995) Phonetics of second language acquisition: past, present and future. Proceedings of the XIIIth International Congress of Phonetic Sciences, vol. 5, 76-83.
Takata, Y. and Nabelek, A.K. (1990) English consonant recognition in noise and in reverberation by Japanese and American listeners. Journal of the Acoustical Society of America, vol. 88, pp. 663-666.
Wang, D.M. and Bilger, R.C. (1973) Consonant confusions in noise: a study of perceptual features, Journal of the Acoustical Society of America, vol. 54, pp. 1248-1266
© Valerie Hazan and Andrew Simpson
 for comments
for comments