9. Paralinguistics
Key Concepts
- The paralinguistic study of speech is concerned with communication of affect or attitude by non-verbal means.
- Much speaking style research has looked at the clarity of speech along a hypo-hyper dimension.
- Speech emotion research is challenging because of difficulty of data collection.
- Activation-valence space is a useful way to model the effects of emotion on speech.
- Physiological effects on speech could lead to important applications, but there is much individual variability.
Learning Objectives
At the end of this topic the student should be able to:
- explain the differences between Linguistic, Paralinguistic and Extralinguistic aspects of speech communication
- describe what is meant by "speaking styles" and give examples of styles and their effect on speech
- explain how speech varies along the hypo-hyper speech dimension
- describe how the emotional state of a speaker can affect their speech
- list some of the problems in conducting emotional speech research
- describe how the physiological state of a speaker can affect their speech
- explain why we should be skeptical about suggestions that deception may be detected from speech
Topics
- Terminology
These definitions are taken from Laver (1994):
- A signal is communicative if it is intended by the sender to make the receiver aware of something of which he was not previously aware.
- A signal is informative if, regardless of the intentions of the sender, it makes the receiver aware of something of which he was not previously aware.
- Linguistic activity is communicative behaviour using the coding system of human language. Linguistic communication exploits both a phonological code (segmental and suprasegmental) and a grammatical code (morphology and syntax). Linguistic communication informs the receiver about the intentions of the sender using explicit verbal forms.
- Paralinguistic activity is communicative behaviour that is non-linguistic and non-verbal, but nevertheless coded. Paralinguistic communication informs the receiver about the speakers feelings, attitude or emotional state.
- Extralinguistic activity is what remains in the speech signal after the communicative elements are removed. Extralinguistic aspects of speech are not coded but contain evidential information such as the identity of the speaker, habitual aspects of the speaker's voice quality, overall pitch range and loudness. Extralinguistic information is thus informative but not communicative in our definitions.
While the linguistic and paralinguistic behaviours are communicative (i.e. can be used deliberately by the speaker) they may also be informative to a listener (i.e. provide the listener with information about the speaker he didn't intend). So a listener might draw conclusions about a speaker using any of these three sources of information. You might judge a person in terms of what he said, how he said it and in terms of the physical character of the speaker's voice.
- Speaking Styles
Introduction
It is a common experience that we can tell from a speech recording some information about the context or environment in which it was spoken. Disregarding the actual words used, we may be able to distinguish, for example:
- Speech directed at a child
- Speech directed at a foreigner or a person with poor hearing
- Speech spoken in a noisy place
- Conversational speech between friends
- A job interview
- A politician's electoral speech
- A sports commentary
- A lecture
- Speech read from text
The study of how the communicative context affects the paralinguistic character of speech is called speaking style research.
Research into the paralinguistics of speaking styles is much less well developed than research into the linguistic aspects of speech. It is still not clear, for example, whether these identifiably different speaking styles listed above are just points in some speaking style space, or are just arbitrary idiosyncratic styles having no relationship with one another. It has been suggested that each style can be positioned in a three dimensional style space having dimensions of intelligibility, familiarity and social stratum (Eskenazi, 1993):
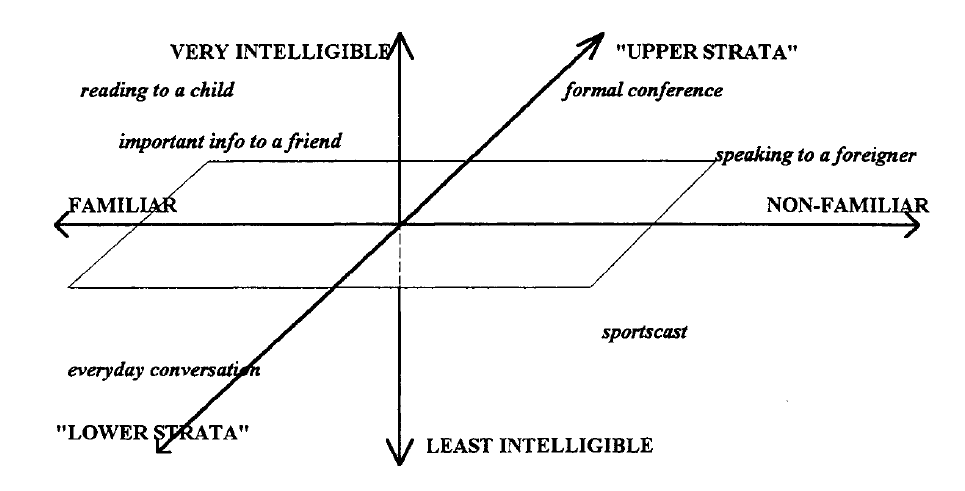
Clear Speech
Recent research has looked at how speech varies in "clarity" according to the communicative context. The idea being that speech itself can be put on an intelligibility dimension: sometimes speech is poorly articulated and hard to understand (hypo-speech) and sometimes it is well articulated and easy to understand (hyper-speech). Hypo-speech is sometimes called "talker-oriented" in that it arises in a situation when the speaker is only concerned with minimising the effort put into speaking; while hyper-speech is called "listener-oriented" since it arises in a situation where the speaker is concerned with whether the listener is getting the message.
Where speech is placed along this hypo-hyper dimension can be seen to be influenced by features of the communicative context, as shown in the diagram below:
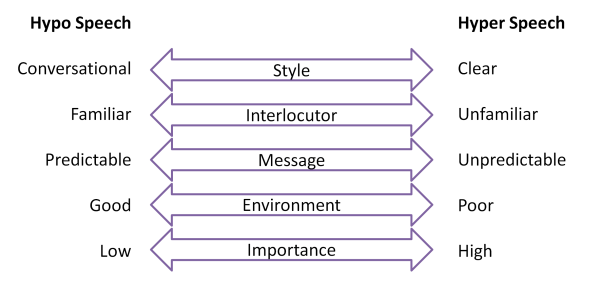
Speech is towards the hypo end of the dimension when you are having a conversation with a friend, the message content is predictable, the acoustic environment is good or the information communicated is not very important. Alternatively, speech is towards the hyper end of the dimension when you are trying to be clear to a stranger, when the message content is novel, the acoustic environment is poor or the information important.
How does speech itself change along the hypo-hyper dimension? To increase the clarity of speech, speakers tend use strategies such as:
- Speaking more slowly
- Articulating segments more carefully
- Raising vocal intensity (by increased lung pressure or by using modal phonation)
- Raising pitch (often an inevitable by-product of increased lung pressure)
- Increasing pitch variation
Which strategies are used to clarify speech can also vary according to further details of the communicative context. In a noisy place one might speak more loudly, but to a child one might speak more slowly.
A recent review of clear speech research can be found in Smiljanić and Bradlow listed in the readings.
Experimental Methods
We can use our instrumental methods to compare the same utterance spoken in different styles if we know that the only difference is one of style. We might record a person chatting to a friend then later ask them to read the same utterances in a formal way.
Data collection for speaking style research can itself be a challenge: the fact that we seek to record speech in very controlled environments means that listeners know they are being recorded which may change how they speak. Recent work in this area has used artificial tasks where a dialogue is recorded from two participants engaged in problem solving, such as map-reading or picture-comparison. By controlling the familiarity of the speakers, the language background of the speakers, the hearing impairment of the speakers, or the quality of the audio channel, the experimenter can force different communication requirements on the speakers and see how that affects their speech.
The acoustic measurements of speech that are collected in this research are generally those which are easy to measure and which can be said to be related to the hyper-hypo dimension. Suprasegmental measures such as speaking rate, pause frequency & duration, pitch variation and the timing of phonetic elements are frequently collected. Information about vowel and consonant reduction is also of interest, with studies looking at formant frequency range as a function of the communicative context.
- Emotion
Introduction
Speech emotion analysis refers to the use of various methods to analyze vocal behavior as a marker of affect (e.g., emotions, moods, and stress), focusing on the nonverbal aspects of speech. The basic assumption is that there is a set of objectively measurable voice parameters that reflect the affective state a person is currently experiencing (or expressing for strategic purposes in social interaction). This assumption appears reasonable given that most affective states involve physiological reactions (e.g., changes in the autonomic and somatic nervous systems), which in turn modify different aspects of the voice production process. For example, the sympathetic arousal associated with an anger state often produce changes in respiration and an increase in muscle tension, which influence the vibration of the vocal folds and vocal tract shape, affecting the acoustic characteristics of the speech, which in turn can be used by the listener to infer the respective state (Scherer, 1986). Speech emotion analysis is complicated by the fact that vocal expression is an evolutionarily old nonverbal affect signaling system coded in an iconic and continuous fashion, which carries emotion and meshes with verbal messages that are coded in an arbitrary and categorical fashion. Voice researchers still debate the extent to which verbal and nonverbal aspects can be neatly separated. However, that there is some degree of independence is illustrated by the fact that people can perceive mixed messages in speech utterances – that is, that the words convey one thing, but that the nonverbal cues convey something quite different. [Juslin & Scherer, Scholarpedia]
Describing Emotions
As with speaking style, it is hard to know whether we should categorise emotions into basic types (the “big six”: anger, fear, sadness, joy, surprise and disgust) or whether to position emotions in some n-dimensional space. In so far as speech is concerned, we find that the same kinds of speech changes occur in a number of different emotions (increased energy or increased pitch for example), so that the space of emotional states that influence speech is probably limited. Cowie (2001, 2003) proposes just two dimensions, valence and activation. Valence corresponds to the positive or negative aspect of the emotion, while activation relates to “the strength of the person’s disposition to take some action rather than none”. There is some experimental evidence that two-dimensions are necessary, even if they are not sufficient.
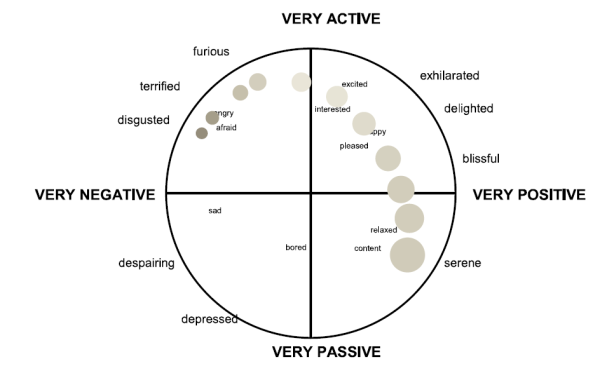
Valence-activation space has proved useful in experimental work, since listeners can reliably position emotional speech in the space, and we can then determine which acoustic features of the signal correlate with their judgments.
Experimental Methods
The study of emotional speech is fraught with methodological and ethical problems: (i) it is difficult to get recordings of genuine emotions since they occur in natural settings which are unlikely to be recorded (and even then we can’t be sure of the actual emotion felt by the speaker), (ii) it is considered unethical to actually make speakers "afraid" or "panicking" just so we can investigate their speech, (iii) acted speech may caricature rather than express genuine emotions (and actors vary in how well they express emotions), (iv) speakers vary in how they express the same emotion in speech, and (v) speakers expressing an emotional “type” will also differ in the degree of emotional "arousal".
Acoustic properties of emotional speech
Most research into emotional speech has focussed on how emotional expressions affect the prosody and voice source characteristics of speech. For example this table from Scherer, 2003:

Note that similar patterns arise for different emotions - mean F0 rises for both Anger and Joy. Also note that changes are correlated across acoustic features - vocal intensity and vocal pitch rise or fall together. These are the kind of facts which support the idea that emotional speech should be described within a simpler "space" of behaviours, such as the valence-activation space suggested by Cowie.
- Physiology
The speech produced by a person will be affected by changes in their physical state or their health. For example we notice if a speaker is out of breath, or has a cold. We can also often get a sense of the age of a person from their voice. Broadly speaking we can differentiate between physiological factors in terms of how they affect production: in terms of articulatory planning and control, airflow, larynx physiology or articulator physiology.
We'll look at four areas where researchers have studied the effect of physiological changes on the voice: Stress, Fatigue, Intoxication and Age.
Stress
Although there is no clear definition of "stress", it has been defined as the physiological response of an individual to external stressors subject to psychological evaluation. Physiological response here refers to the invocation of the 'fight or flight' mechanisms of our nervous system, by which adrenalin levels are increased, cardiovascular output is increased, senses are sharpened, pupils are dilated and so on. Stressors include direct physical effects on the body (e.g. acceleration, heat), physiological effects (e.g. drugs, dehydration, fatigue, disease), perceptual effects (e.g. noise, poor communication channel) or cognitive effects (e.g. perceptual load, cognitive load, emotion). Psychological evaluation allow for the fact that an individual's reaction to these stressors may vary according to the individual's evaluation of their importance.
This focus on the physiological response to stressors makes sense with regard to the assessment of stress through characteristics of the voice. It is to be expected that speech, as a neuromuscular performance, will be affected by the physiological state of the individual. For example increased respiration might increase sub-glottal pressure and hence affect the voice fundamental frequency and spectral slope of the voice spectrum. Increased muscle tension might affect vocal fold vibration or the supra-laryngeal articulation of vowels and consonants. Increased cognitive activity might affect speaking rate, pauses or speaking errors.
Early work on the effect of stress on speech was mainly concerned with identifying vocal characteristics that varied with level of stress, without quantitative prediction from signal measurements. Early studies reported changes in the prosodic elements of speech (pitch, stress, timing and speaking rate). Later studies were based on calibrated speech corpora recorded under real or simulated conditions of stress, for example the SUSAS corpus. Given speech materials labelled for levels of stress, signal processing algorithms could now be evaluated for their ability to extract features correlated with stress. Commonly exploited features included voice fundamental frequency, intensity, duration, plus measures of voice quality and spectral energies. Scherer et al (2002) explored the impact of simulated cognitive load and psychological stress tasks on the voice. Although cognitive load did have a significant effect on aspects such as speech rate, energy contour, voice fundamental frequency and spectral parameters, the main conclusions are that individual variability make these unreliable predictors of load or stress.
A recent review of the effects of stress on the voice can be found in Kirchhübel et al, 2011 (see readings).
Fatigue
Various speech parameters have been observed to vary systematically with increasing fatigue. Changes in pitch height, pitch variation, speaking rate, pause frequency and length, and spectral slope have been reported. Vogel et al (2010) reported an increase in the total time taken to read a passage, and an increase in pause duration after their subjects had been kept awake for more than 22hours.
The figure below (from Baykaner & Huckvale, et al, 2015) shows the results of an experiment to predict time awake from changes in the speaking voice. In this experiment, the speakers were kept awake for 60 hours (three days) and changes to the voice could be used to identify quite accurately whether the speaker had slept in the previous 24 hours. Each point in the graph is a recording of the subject reading from a novel.
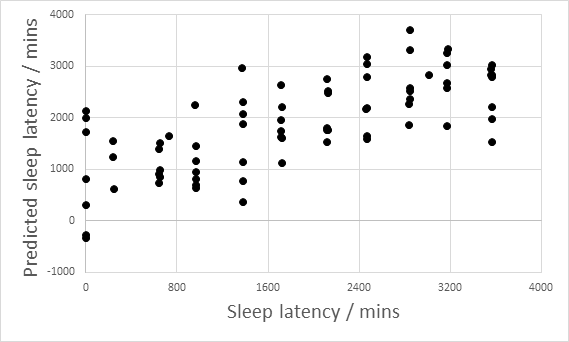
Intoxication
Alcohol and other intoxicants have been seen to affect speech. Hollien et al (2001) report increases in fundamental frequency, increases in time to complete the task and increases in disfluencies with increasing alcohol intoxication. The graph below shows mean changes in fundamental frequency for men and women in the study as a function of breath alcohol concentration.
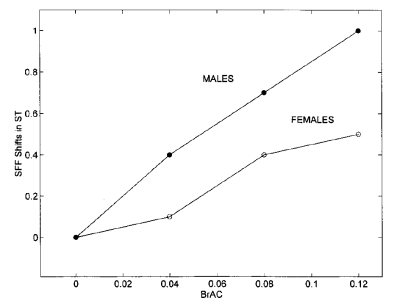
Interestingly, Hollien et al report much variability in how individuals respond to the same level of alcohol intoxication. A significant minority of speakers showed no measurable effects of alcohol intoxication on their speech.
Over the long term, repeated intoxication can have permanent effects on the voice. Alcohol, in particular, causes dehydration of the vocal folds and makes them more susceptible to organic damage.
Age
A speaker's voice changes as they get older to the extent to which we can estimate fairly well the age of a speaker from their voice. The figure below (from Huckvale & Webb, 2015) shows the predicted ages of 52 speakers made by 36 listeners. The mean absolute error of age prediction was about 10years, that is we can often estimate a speaker's age within a decade just by hearing their voice.
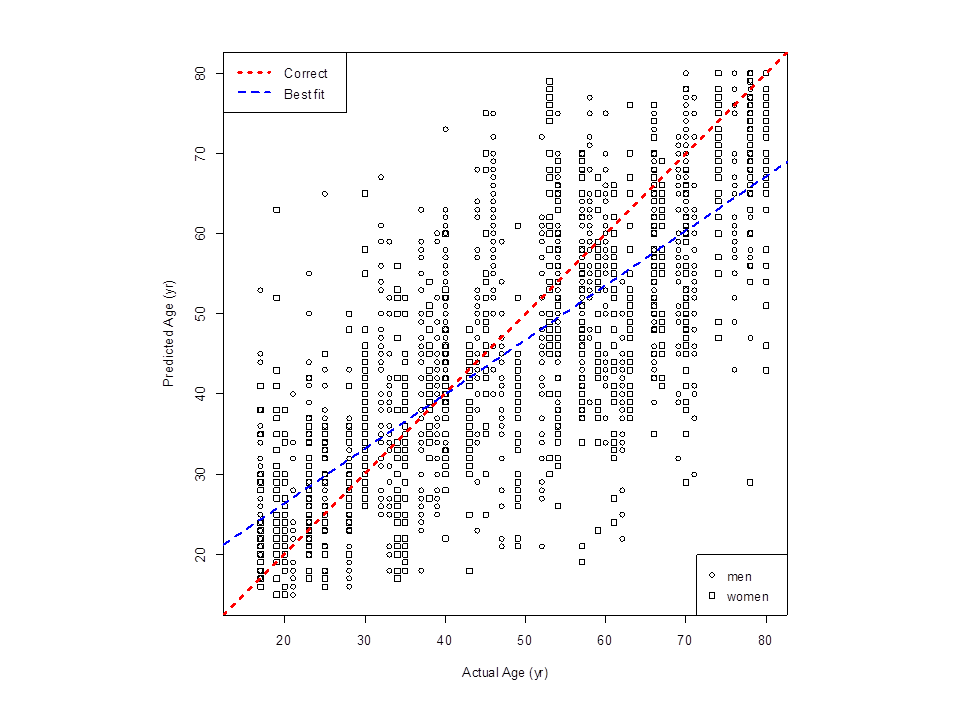
Readings
Essential
- M. Eskenazi, Trends in speaking styles research, Proc. EuroSpeech 1993, Berlin, 501-509.
- R. Cowie, Describing the emotional states expressed in speech, ISCA ITRW Speech and Emotion, Newcastle, Northern Ireland, 2000.
Background
- Rajka Smiljanić and Ann Bradlow, Speaking and Hearing Clearly: Talker and Listener Factors in Speaking Style Changes
- Scherer, K. R., Vocal communication of emotion: A review of research paradigms. Speech Communication, 40 (2003) 227-256.
- Kirchhübel, C., Howard, D., Stedmon, A., Acoustic correlates of speech when under stress: Research, methods and future directions, The International Journal of Speech, Language and the Law, Vol 18.1 (2011) 75-98.
- A.P. Vogel, J. Fletcher, P. Maruff, Acoustic analysis of the effects of sustained wakefulness on speech. J. Acoust. Soc. Am 128 (2010) 3747.
- H. Hollien, G. DeJong, C. Martin, R. Schwartz, K.Liljegren, Effects of ethanol intoxication on speech suprasegmentals, J. Acoustic. Soc. Am. 110 (2001) 3198-3206.
Laboratory Activities
In this week's lab we will take part in an emotional speech rating experiment and investigate what properties of the signal were behind our decisions:
- Rate some emotional speech in terms of emotional valence.
- Rate some emotional speech in terms of emotional activation.
- Analyse class average ratings.
- Correlate class ratings with speech signal properties.
You will have the choice between this lab and last week's lab to form the basis for the second lab report.
Research paper of the week
Detecting Deception in Speech
- J. Hirschberg, S. Benus, J. M. Brenier, F. Enos, S. Friedman, S. Gilman, C. Girand, M. Graciarena, A. Kathol, L. Michaelis, B. Pellom, E. Shriberg & A. Stolcke, Distinguishing Deceptive from Non-Deceptive Speech. Proc. Eurospeech 2005, pp. 1833-1836, Lisbon.
A long standing area of interest and controversy has been the detection of lying from a person's behaviour. "Lie detector" machines are supposed to detect when someone is lying from changes in their skin conductance and other physiological signs. The current scientific wisdom is that these devices do not detect lying so much as signs of physiological and psychological stress. Thus to detect lying, the subject has to be put in a situation in which deception would give rise to stress. However the level of stress exhibited probably depends on the circumstances of the test and the mental character of the individual.
The detection of lying in speech is equally problematic. We don't expect speech to change because of deception per se, rather it will change if the telling of a lie causes some physiological stress.
In this paper the authors collected a new corpus of "deceptive speech" in a novel paradigm. Subjects were interviewed and asked to lie about some areas of their CV, while at the same time pressing a foot pedal if they were not telling the truth. Sentences representing true statements could then be directly compared to sentences representing lies for the same speaker.
The authors analysed the corpus using both linguistic and acoustic-phonetic features. Small but significant differences were observed between deceptive and non-deceptive speech. The best acoustic features worked when differences were studied within a speaker. The authors conclude:
In this paper we have described experiments in distinguishing deceptive from non-deceptive speech in the CSC Corpus, a data collection designed to elicit within-speaker deceptive and non-deceptive speech. Preliminary analyses of this data indicate several statistically significant differences between the two classes of speech: differences in the use of positive emotion words, of filled pauses, and in a pleasantness score calculated using Whissel’s Dictionary of Affect. In pursuit of our primary goal of automatic modeling of deceptive speech, we have also examined three feature-sets for use in machine learning experiments, including acoustic/prosodic, lexical, and speaker dependent sets of features. While neither the acoustic/prosodic nor the lexical feature sets currently perform much above the baseline, their combination does exhibit improved performance. The most dramatic improvement, however, comes with the addition of speaker-dependent features, which reduces the baseline error by over 6%.
It may be worth mentioning that even their best system identified only 66% of the deceptive utterances even though the chance level was 60%.
Application of the Week
This week's application of phonetics is the construction of systems for the automatic recognition of emotional state from speech. It has been suggested that such systems would be of use in improving human-machine spoken dialogue systems, so that the machine would both detect the human's emotional state and react accordingly.
This video gives you an example of what can be achieved currently:
Emotion recognition issues
We begin by summarising the main challenges to building an automated system for the recognition of human emotional states.
- Definition of problem: to recognise a person's emotional state pre-supposes we know what that state is and we know how to describe it. Unfortunately there are competing theories for how to categorise and describe emotions and it is not clear whether it even makes sense to describe them as discrete categories. In any real situation how can we actually tell what emotional state a person is undergoing?
- Availability of speech materials: it has proved difficult to obtain emotional speech materials. Since it is considered unethical to actually make people angry or afraid just so we can collect their speech, we have to rely on actors or artificially contrived laboratory tasks. Many existing corpora are too small or too poorly controlled to use as the basis for building a high-performing emotional speech recognition system.
- Effect of language: ideally, a system should be language-independent, since we are talking about detecting the paralinguistic properties rather than the linguistic properties of the speech signal. However this in turn pre-supposes that emotions are expressed in speech in the same way in all cultures. This seems unlikely to be true.
- Effect of speaker: ideally a system should be speaker-idependent so that it works for everyone. However since emotional states are expressed as changes to the normal speech for the speaker, it seems likely we shall need to characterise the normal speech for each speaker first. Of course different speakers may well vary in how they express their emotion in speech, and to what degree.
- Effect of audio environment: the system should work in everyday environments: in noisy, reverberant rooms or over the telephone network. However such audio environments are challenging for reliable estimation of voice parameters.
Emotional Speech Corpora
Broadly speaking there are three ways in which we can collect corpora of emotional speech:
- Acted emotional speech: we can obtain recordings of simulated emotions from actors. Typically actors are asked to read neutral sentences in different emotions. Most emotional speech corpora are of this kind. Problems arise in that actors tend to "go over the top" and produce more extreme emotional reactions than may be typical in everyday life.
- Elicited emotional speech: emotional speech can be elicited by involving a listener in some task, perhaps a dialogue with an experimenter, which causes the subjects to change and express different emotions in their speech. This can be quite demanding on the experimenter, and success will vary across subjects. Some attempts have been made to elicit emotions from interactions with a computer spoken dialogue system. A general problem is that when subjects know they are being recorded they may change the way they speak.
- Found emotional speech: while recordings of emotions in natural situations may be the most authentic, there are many problems. We need to obtain the permissions of the speaker, we may not know what emotion is being expressed, or at what level of arousal. The audio quality may be poor and variable in quality. Generally recordings are hard to obtain, although the increasing use of video sharing on social media may help.
Emotional Speech Features
The phonetic features estimated from the speech signal are unsurprising, being related to the properties of the signal known to encode paralinguistic information:
- Prosody features: pitch height and range, energy level and range, speaking rate.
- Source features: irregularity & breathiness of voice quality.
- Filter features: size and structure of spectral "space" used in speech, rate of change of spectrum.
Performance of Emotional Speech Recognition
These performance figures come from Ramakrishnan & El Emary (see further reading) and are based on the Berlin Emotional Database (EMO) corpus.
| Type of Emotion | Probability of correct detection |
|---|---|
| Anger | 0.84 |
| Boredom | 0.69 |
| Disgust | 0.60 |
| Fear | 0.64 |
| Joy | 0.85 |
| Neutral | 0.54 |
| Sadness | 0.75 |
You can see that some emotions (Anger, Joy, Sadness) are better identified than others, perhaps because they show a greater difference to the speaker's normal voice.
Applications of Emotional Speech Recognition
Possible applications of emotional speech recognition systems might be:
- Tutoring systems: so that computer aided learning systems detect when students are becoming frustrated.
- Lie detection: to detect increasing levels of stress in police interviews.
- Telephone dialog systems: such as used in telephone banking, may be helpful to detect when user is angry or frustrated so that they can be passed to a human operator.
- In-car monitoring: to detect increasing stress or fatigue in drivers.
- Call centres: to monitor whether the operators are aggravating customers.
- Computer games: so that the difficulty level of the game can change with the player's involvment.
- Clinical applications: to monitor and assess a person's emotional state or their health through their everyday lives.
- Robots: to make robots react to the emotional state of their owners or operators. Robot pets or robot companions might change their behaviour to make them seem more sympathetic, for example.
Further Reading
- S. Koolagudi, K. Sreenivasa Rao, "Emotion recognition from speech: a review", International Journal of Speech Technology, 15 (2012) 99-117.
- S. Ramakrishnan, Ibrahiem El Emary, "Speech emotion recognition approaches in human computer interaction", Telecommunication Systems 52 (2013) 1467-1478.
Reflections
You can improve your learning by reflecting on your understanding. Come to the tutorial prepared to discuss the items below.
- Suggest two utterances which vary in paralinguistic terms but not in linguistic terms.
- Suggest two utterances which vary in extralinguistic terms but not in paralinguistic or linguistic terms.
- How is "read speech" different from "spontaneous speech"?
- Give an everyday example of extreme hypo-speech; of extreme hyper-speech.
- Why are the dimensions of valence and activation more useful to phonetic research than just a list of emotional categories?
- What problems might there be in making authentic recordings of emotional speech or of intoxicated speech?
Word count: . Last modified: 09:57 04-Dec-2020.