3. Sound initiation in the vocal tract
Key Concepts
- The goal of articulation is to communicate a message: we speak to be understood.
- Phonetics must be interested in sound, hearing and perception as well as articulation.
- Sounds are those small, rapid air pressure fluctuations that can be detected by human hearing.
- The perceptual dimensions of sound are Loudness, Pitch and Timbre.
- Limits to our perception probably influence the character of speech sounds and the phonological inventory.
- We use four key graphs to instrument speech sounds: Waveform, Pitch track, Spectrum, Spectrogram.
- The articulators convert air-flow to sound through: Phonation, Turbulence, Trills and combinations of these.
Learning Objectives
At the end of this topic the student should be able to:
- describe the 'speaking to be understood' model
- explain the nature of sound, and the psychological dimensions of sound sensation
- describe how air flow can give rise to sounds through phonation and turbulence
- list the different air-stream mechanisms that give rise to air-flow in the vocal tract
- describe what can be seen on a waveform, a pitch track, a spectrum and a spectrogram
Topics
- Speaking to be understood
Much Phonetics teaching is about articulation, because Phonetics has, historically, used transcription as a means to catalogue the different sounds used in speech. But of course articulation is not an end itself. We don't articulate speech just to move the tongue around in the mouth.
What is the goal of articulation, then? One might say instead that articulation aims to generate sound, and indeed intelligible speech can be produced by machines simply by creating the right sounds, even in the absence of a vocal tract. Another view might be that articulation aims to generate the right perceptual effect in the hearer - the right output from their auditory system. After all differences in articulation that can't be heard cannot be important for communication.
A better theory than either of these is to say that the goal of articulation is to communicate a phonologically-encoded message. Articulation is successful only when the words you want to communicate (or their meaning at any rate) are recovered by the listener. Sending the right message is more important than the right articulation or the right sound. I call this "speaking to be understood":
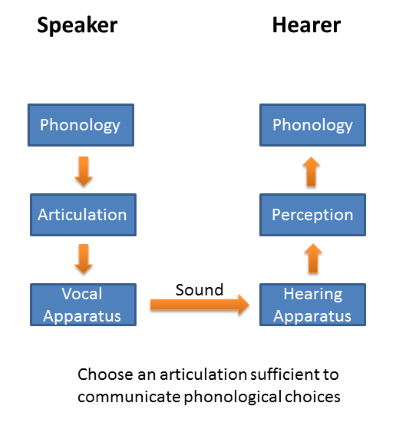
Speaking to be understood implies that our articulation must be adequate to communicate some phonologically encoded information from the mind of the speaker to the mind of the hearer. The process involves not only need articulation and sound and perception but also the recognition of the message in the hearer. This view has important consequences: it sets a minimum quality requirement for the articulation. Articulation must be at least good enough for the hearer to identify the words/meaning in the message. When we articulate we must ensure to create a sound that when processed by the hearer's perceptual system can be interpreted using the phonological code. Any articulation which is unclear may lead to ambiguity in phonological form in the mind of the listener and ambiguity in the communicated message.
How can a speaker know whether his/her articulation is good enough? Fortunately most speakers are also hearers. So it is a relatively simple matter to listen to yourself while you are speaking, checking with the "same" perceptual and phonological system as the hearer whether the message is likely to be communicated successfully. We develop our own internal speech recognition processing over a lifetime of exposure to effective spoken communication with others and so can use it evaluate our own articulatory quality.
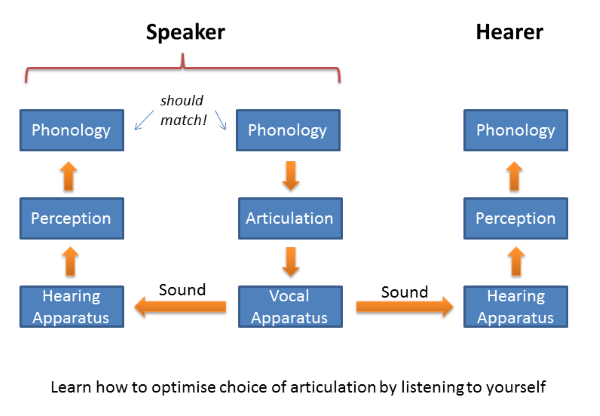
Speaking to be understood is able to explain a range of phenomena, including:
- Why you can "get away with" assimilations and elisions - because the articulation is still good enough to communicate the message
- Why you speak unpredictable words more clearly than predictable words - because unpredictable words are harder for the hearer to guess.
- Why you speak more carefully in a noisy place - because the sounds of articulation may be masked and less reliable.
- Why you speak less clearly to people you know better - because you have a better idea of their competence you can reduce articulatory quality to the minumum.
- Why you speak in a different way to children - because you match your utterances to your expectations about their linguistic competence.
Speaking to be understood does mean, however, that we need to involve processes of hearing and perception in our understanding of Phonetics and speech communication. It will no longer be good enough to study articulation in isolation.
- Air-flow, air-pressure and sound
Speech communication relies on the fact that we live in an environment of high pressure gas, and that we have both a means to modify the pressure of the gas and a means to sense those changes at a distance. When we speak the air pressure in the vocal tract is slightly modified (by vibrations of the larynx or by turbulence) and those pressure fluctuations propagate rapidly through the air from speaker to hearer - where the hearing mechanism translates those fluctuations into a neural code.
Don't confuse the terms air flow, pressure waves and sound: air flow is the physical movement of air (like a wind or when you breathe out) which usually occurs at a slow speed; pressure waves are disturbances in atmospheric pressure that propagate outwards from a vibrating source; these do not require the physical movement of air and they travel very fast (at about 330ms-1); we reserve the term sound for those pressure waves which give rise to a sensation in a human listener. It is only a limited range of air-pressure changes that give rise to an auditory sensation; sometimes the changes can be too slow or too fast, too small or too large to be perceived as sound.
- Sound Perception
We can describe the sensation of steady-state sounds using the perceptual dimensions of Loudness, Pitch and Timbre.
- Loudness is our sense of the quantity of sound. It is analogous to the brightness of a light. In physical terms, loudness is correlated with the size of the pressure fluctuations. The size of the pressure fluctuations for typical sounds is very small. The smallest pressure fluctuations that give rise to sound sensation are about 1/10,000,000,000 of atmospheric pressure. The largest are about 1/1,000 of atmospheric pressure. Between these limits we notice changes in loudness if the amplitude of the fluctuations changes by about 12% (this corresponds to 1 decibel).
- Pitch is our sense of the melodic properties of sound that allow us to order order sounds from low to high. It is analogous to the flickering rate of a light. In physical terms, pitch is correlated with repetition frequency, that is the number of times the sound pattern repeats in one second. We associate a clear pitch to sounds that have repetition frequencies between about 20 and 5000 per second (written as 20-5000Hz). We are very sensitive to changes in repetition frequency: below 500Hz we can hear changes as small as 1Hz or 0.2%.
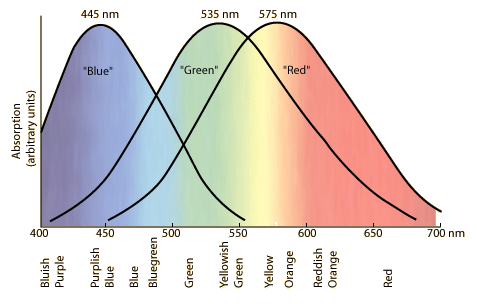
- Timbre is our sense of the quality of sound. It is analogous to the colour of a light. In physical terms it is predominantly correlated with the spectral envelope of the sound, that is the amount of energy in the signal in different frequency regions. This sensitivity to the spectrum comes about because our hearing breaks apart the sound into bands ordered by frequency (analogous to the eye breaking apart light into red, green and blue). There are about 20-30 independent bands in the auditory system, but the higher frequency bands are wider than the lower ones, see diagram below. Generally we notice changes in timbre when the energy in one of the bands changes by about 12% (that is, 1 decibel). In terms of the spectrum of a vowel, this roughly corresponds to a change in F1 of about 60Hz, or a change in F2 by 175Hz (see this week's research article).
Analysis bands used in seeing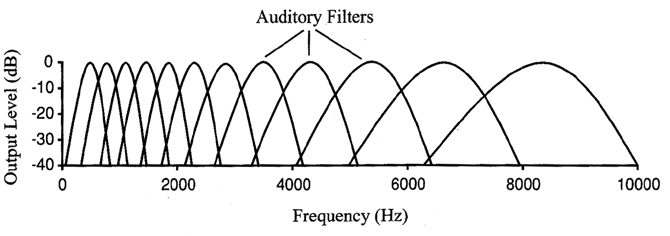
Analysis bands used in hearing
For sounds that change with time, we can also perceive changes in duration and speaking-rate. We measure duration in milliseconds (ms) and rate in syllables per second. Generally our ability to detect changes in the duration of a sound is limited to changes greater than about 10% and overall tempo differences to about 5%.
Our memory for sounds is quite short, only a few seconds (this is called "echoic memory"). If we are to remember a sound for longer than a few seconds we need to extract and remember some of its properties. This has very important consequences for speech perception. After a few seconds we may remember the phonological label for a sound, but not what it actually sounded like.
- Making sounds with the articulators
Broadly speaking we can divide sound generation in the vocal tract into two parts: conversion of air-flow to sound and shaping of sound.
Conversion of air-flow to sound
- Phonation:
- Trilling:
- Turbulence in a constriction:
- Turbulence at an obstacle:
- Turbulence in mixing:
- Combinations:
The dominant method of sound generation is phonation in the larynx. The vocal folds in the larynx are brought together, tensed and a pulmonic egressive air-flow from the lungs is blown between them. This causes a repetitive vibration of the folds which interrupts the flow of air into a series of pulses. When the flow of air is disrupted in this way, low pressure events are caused once per cycle which propagate as sound. [Next week we will look at phonation in detail].
A pulmonic egressive air flow can also create a repetitive vibration of an articulator in the supra-laryngeal vocal tract. If air is blown through a narrowing created by a lightly-tensed articulator, then a different repetitive vibration can be created, called a trill. The IPA recognises trills made by the uvular against the back of the tongue, the tongue-tip against the alveolar ridge, and the two lips.
Air-flow passing through a severe narrowing in the vocal tract can become turbulent. Turbulence is characterised by random or chaotic flow when the air is forced through a channel at too great a velocity to allow smooth flow. The random changes in flow create random pressure changes that give rise to a 'noise' sound.
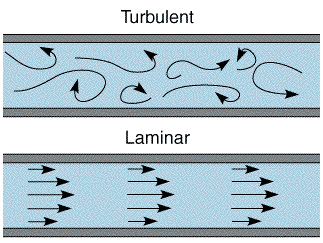
Turbulence can also arise when a jet of moving air hits an obstacle (like blowing onto a sharp edge). This mechanism is thought to be important in the generation of sibilant fricatives, where a jet of air created by a groove in the tongue is directed at the teeth.
Turbulence can also occur when a flow of air mixes with stationary air. This mechanism may be important in the production of plosive bursts, where high-pressure air rushing out from behind a suddenly released obstruction mixes with the stationary air in front of the obstruction.
Sometimes these sound generating processes can occur in combination, for example a mixing of phonation with turbulence generated in a constriction. The air-flow that passes through the larynx causing phonation, continues into the oral cavity and may be used to create another sound source (e.g. /z/).
Shaping of sound
If a sound is generated within the vocal tract, it still must pass along the vocal tract pipe extending between the sound source location and the lips/nostrils. The size and shape of this pipe can affect the spectrum of the sound as radiated from the lips. This gives us further opportunity to manipulate the timbre of the sound. Phonation generates the same sound for every vowel, but differences in the shape of the pipe between larynx and lips modifies the timbre of phonation to create different vowel qualities. We will return to this in lecture 5.
- Measuring sound
To describe and measure sounds we use instruments to capture and display the pressure changes in graphical form. The four key graphs that we use are:
- A Waveform displays the amplitude of a sound as a function of time. The amplitude is usually measured by a microphone and converted to a voltage which is fed into the measuring system. Air pressure fluctuations in sounds are very small and rapid, so microphones need to be very sensitive. Waveforms are useful to see the overall loudness envelope and the timing of individual phones, but less useful to show pitch and timbre since these are related to the size and shape of the waveform cycles.
- A Pitch Track is a graph of the dominant repetition frequency in the sound as a function of time. The repetition frequency is estimated by observing the waveform on a short timescale to look for repeating waveform cycles. A low-pitched vowel sound has waveform cycles with a low repetition rate (say 100/second), while a high-pitched vowel has waveform cycles with a high repetition rate (say 300/second). A pitch track is of use in the teaching and learning of tone and intonation. Sometimes you will see the vertical axis labelled as "Fundamental frequency". Fundamental frequency is just another name for the frequency at which the waveform shape repeats. A pitch track of speech will have gaps in silent and voiceless intervals where the signal is not repetitive and has no fundamental frequency.
- A Spectrum displays an analysis of a section of waveform in terms of the amplitude (quantity) of each frequency component found in the signal. The horizontal axis is frequency in hertz and the vertical axis is amplitude, typically in decibels (dB). The graph shows how much energy is found in the signal in each frequency band. The overall shape of the spectrum (its "envelope") is the main contributor to sound timbre. Two sounds of the same spectral envelope will have the same timbre even if they have different fundamental frequencies. This is analogous to a light of a certain colour flickering at different frequencies.
- A Spectrogram shows how the spectrum of a sound changes with time. A spectrum is a snapshot of the signal; it shows what frequency components are present at one time only. To see how speech evolves in time we need a movie of the signal instead. We do this by calculating and displaying spectra 1000 times per second and plotting them in a 3D graph of amplitude, frequency and time. On a spectrogram, the horizontal axis is time, the vertical axis is frequency and the amount of energy present in the signal at a given time and frequency is displayed on a grey scale (with black=a lot, and white=a little). A spectrogram is the best general method of displaying how the loudness and timbre of a speech signal changes with time. It is easy to see the temporal structure of vowels and consonants, and also the spectral differences that we use to signal phonologically different speech sounds.
- Air-streams (Revision)
Ultimately all sound production in the vocal tract is initiated from a movement of air caused by changes in state of the respiratory system or articulators.
Traditionally the air stream mechanisms used in speech are categorised under the following headings:
- Pulmonic: meaning air movement that arises from changes in the internal pressure in the lungs.
We can lower the diaphragm and contract the external intercostal muscles to increase the volume of the lung cavity and the reduced pressure inside the lungs draws in air through the mouth and nose. We can then raise the diaphragm or contract the internal intercostal muscles to decrease the lung cavity volume and then the increased pressure in the lungs forces air back out. Typically we speak on an outward going or egressive flow of air, but it is also possible to speak on the inward or ingressive flow.
A pulmonic air stream can cause sound generation by causing vibration in the vocal tract, either phonation in the larynx or a trill of the uvular, tongue tip or lips. In addition, a pulmonic flow can be directed through a narrowing or constriction at different places in the vocal tract causing turbulence to arise.
While speech is possible on a pulmonic ingressive air-stream, the ingressive-egressive difference is not thought to operate contrastively in any world language. There are however paralinguistic uses: contrast [j↑ɛ↑s↑] with [j↓ɛ↓s↑] for "yes" (usinɡ ↑ for eɡressive and ↓ for ingressive).
- Glottalic: meaning air movement that arises from changes in the height of the larynx (with the glottis closed). A typical sequence of events would be (i) lower the larynx and close the glottis, (ii) form an oral closure, (iii) raise the larynx (compressing the trapped air), (iv) suddenly release the oral closure. Sounds made with an egressive glottalic air-stream mechanism are called ejectives. The diagram below shows the steps in the production of [kʼ]. (source: Ladefoged, 1993)
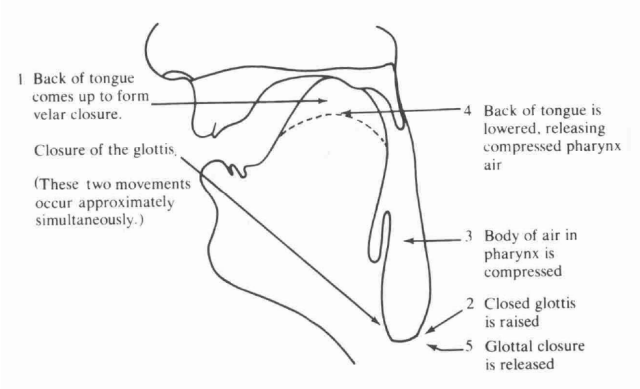
A glottalic ingressive air-stream can be combined with a pulmonic egressive air-stream to achieve voiced implosives. In a voiced implosive the larynx is raised and the glottis closed; then an oral closure is made and the larynx descends. The oral closure is then released and a pulmonic egressive airstream mechanism is initiated to start phonation. Voiced implosives are found to contrast with voiced plosives in some languages, for example in Zulu:
[ɓɪːza] call [bɪːza] have concern [ɓuːza] ask [buːza] buzz Symbol Description Listen ɓ Voiced bilabial implosive ɗ Voiced dental or alveolar implosive pʼ Voiceless bilabial ejective plosive ʄ Voiced palatal implosive tʼ Voiceless dental or alveolar ejective plosive ɠ Voiced velar implosive kʼ Voiceless velar ejective plosive ʛ Voiced uvular implosive sʼ Voiceless alveolar ejective fricative - Velaric: meaning air movement that arises from the rarefaction of air trapped above the tongue between the velum and some anterior location. A typical sequence of events would be (i) make a velar closure with the back of the tongue, (ii) make a second closure forward of the velum using the tip or blade of the tongue, or the lips, (iii) draw the tongue body down reducing the pressure in the air cavity between tongue and palate, (iv) suddenly release the forward closure causing a rapid inward flow of air. Sounds made with an ingressive velaric air-stream mechanism are called clicks. Although an egressive velaric air-stream mechanism would be possible, there are no reports of its linguistic use.
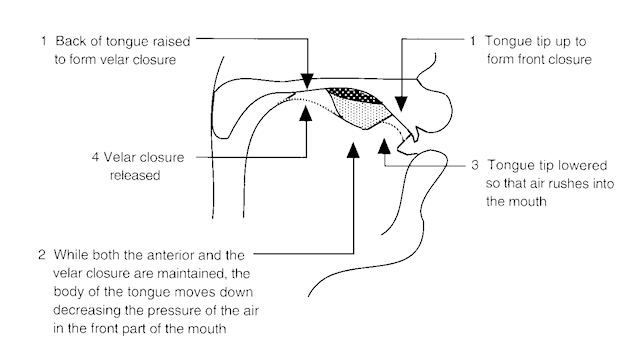
Clicks are used contrastively in a number of languages, including the Khoisan and Bantu languages of Southern Africa, and the Sandawe and Hadzapi languages of East Africa. The IPA recognises five clicks:
Symbol Description Listen ʘ Labial ǀ Dental ǃ (Post)alveolar ǁ Alveolar lateral ǂ Palatal In writing, the letters c, x and q are often used to stand for the dental, lateral and post-alveolar clicks. So the language Xhosa is pronounced [ǁoʊsə].
Clicks are also used paralinguistically, as in blowing a kiss (labial click), making a sound of disapproval (dental click), or encouraging a horse (alveolar lateral click).
A video reward for working through the above (James Harbeck):
Remarkably, other air-stream mechanisms do occur. Sometimes people who have undergone a laryngectomy learn to use esophageal speech. In esophageal speech, air is swallowed and then expelled in a controlled burp through the neck of the esophagus. The passage of air can cause the esophageal sphincter to vibrate and hence act as a source of sound for speaking. Watch a video of esophageal speech.
Finally, some talkers have learned to store air in their cheeks and expel it at the back of the mouth into the oral cavity, causing a turbulent sound. This is called buccal speech, and its most famous practitioner was Donald Duck as voiced by Clarence Nash. Watch a video of when Donald called in Clarence to complain about his voice.
- Pulmonic: meaning air movement that arises from changes in the internal pressure in the lungs.
We can lower the diaphragm and contract the external intercostal muscles to increase the volume of the lung cavity and the reduced pressure inside the lungs draws in air through the mouth and nose. We can then raise the diaphragm or contract the internal intercostal muscles to decrease the lung cavity volume and then the increased pressure in the lungs forces air back out. Typically we speak on an outward going or egressive flow of air, but it is also possible to speak on the inward or ingressive flow.
Readings
Essential
- Hewlett & Beck (2006) An introduction to the Science of Phonetics, Chapters 8-12 [available in library]. Part II of the book gives a comprehensive introduction to sound signals and graphs.
- Ladefoged & Johnson (2010) A Course in Phonetics, Chapter 6, Airstream Mechanisms and Phonation Types. [available in library]. Gives a good introduction to the air-stream mechanisms.
Background
- Laver (1994) Principles of Phonetics, Chapter 6 [available in library]. Comprehensive account of air-stream mechanisms and their exploitation in languages.
Supplementary
As a supplement to the reading, you can watch a 15min E-Lecture on air-stream mechanisms from the Virtual Linguistics Campus.
Laboratory Activities
Spectrographic form of speech sounds in contrast.
In this weeks lab you will use a program called ESection which allows you to record some speech and look at its waveform, spectrum and spectrogram.
Use ESection to contrast the signal analyses of these pairs of phonetic contrasts:
| 1 | 2 | Contrast |
|---|---|---|
| ɑ | i | Vowel Quality |
| ɑ | ɑnɑ | Vowel vs Nasal |
| ɑsɑ | ɑnɑ | Alveolar vs Nasal |
| ɑsɑ | ɑʃɑ | Alveolar vs Alveopalatal |
| ɑsɑ | ɑzɑ | Voiceless vs Voiced (fricative) |
| ɑsɑ | ɑdɑ | Fricative vs Plosive |
| ɑtʰɑ | ɑdɑ | Voiceless vs Voiced (Plosive) |
| ɑɾɑ | ɑdɑ | Tap vs Plosive |
| ɑǀɑ | ɑdɑ | Click vs Plosive |
Research paper of the week
Just Noticeable Differences for Vowels
- P. Mermelstein, "Difference limens for formant frequencies of steady-state and consonant-bound vowels", Journal of the Acoustical Society of America 63 (1978) 572-580.
In this classic paper, artificial vowel sounds were generated by electronic means and listeners asked to judge whether pairs of sounds were the "same" or "different". The goal was to determine by how much vowel formant frequencies had to change for listeners to detect a difference. The term "difference limens" is an old fashioned term for what we now call "just noticeable difference" (JND). Two types of stimuli were used: vowels in isolation and vowels in a consonantal context (CVC). In a consonantal context, the formant pattern changes as the articulators adjust position and this makes the judgement of vowel quality more difficult.
The JND for the CVC stimuli was found to be significantly greater than those for the steady state vowels. For steady-state vowels the JND was about 35Hz for F1 and 75Hz for F2, while for the CVC context the JND was about 60 Hz for F1 and 176 Hz for F2. The conclusion was that this effect was caused by limitations of the auditory system rather than limitations of memory or phonetic perception.
The fact that there are limits to our perception of vowel quality differences is important in our study of the development of vowel systems - one would not expect two phonologically distinct vowels to have very similar formant frequencies, unless that is, they differed in some other way, such as pitch, voice quality or duration.
Application of the week
Mechanical Speaking Machines
This week's application of Phonetics is the construction of mechanical artefacts which speak. Here is a potted history of some mechanical speaking machines. For a more orthodox account see Flanagan (1972).
| Date | Machine |
|---|---|
| 1771 | Erasmus Darwin (Charles Darwin's grandfather) reported:
I contrived a wooden mouth with lips of soft leather, and with a vale back part of it for nostrils, both which could be quickly opened or closed by the pressure of the fingers, the vocality was given by a silk ribbon about an inch long and a quarter of an inch wide stretched between two bits of smooth wood a little hollowed; so that when a gentle current of air from bellows was blown on the edge of the ribbon, it gave an agreeable tone, as it vibrated between the wooden sides, much like a human voice. This head pronounced the p, b, m, and the vowel a, with so great nicety as to deceive all who heard it unseen, when it pronounced the words mama, papa, map, pam; and had a most plaintive tone, when the lips were gradually closed. [Darwin, 1806] |
| 1779 | Russian Professor Christian Kratzenstein demonstrated a set of vowel resonators in St. Petersburg in 1779. The resonators, shown below, produced vowel like sounds on constant pitch when they were excited by a reed.
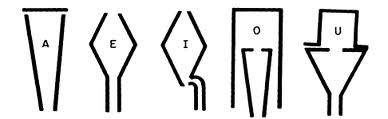 You can follow some instructions of mine to make your own vowel resonators from plumbing supplies. |
| 1791 | Von Kempelen's speaking machine was a complex device consisting of bellows, a reed, whistles and a leather cup which could be manipulated to make speech like sounds. We know its basic design from a reconstruction by the English scientist Charles Wheatstone (~1890). Wheatstone's reconstruction is shown below:
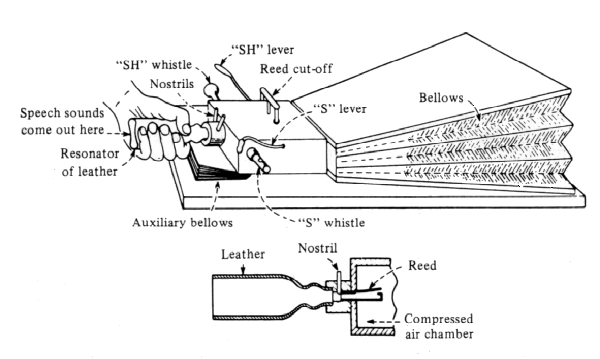 Von Kempelen was a colourful character, his most infamous exploit was the creation of The Turk, a chess playing automaton in 1770 (which was actually controlled by a midget chess master). |
| 1845 | The Euphonia: Joseph Faber's Amazing Talking Machine
Sixteen levers or keys "like those of a piano" projected sixteen elementary sounds by which "every word in all European languages can be distinctly produced." A seventeenth key opened and closed the equivalent of the glottis, an aperture between the vocal cords. "The plan of the machine is the same as that of the human organs of speech, the several parts being worked by strings and levers instead of tendons and muscles." [Henry, 1845]  |
| ~1860 | Alexander & Melville Graham Bell: physical working model of the human vocal tract.
Following their father's advice, the boys attempted to copy the vocal organs by making a cast from a human skull and moulding the vocal parts in guttapercha. The lips, tongue, palate, teeth, pharynx, and velum were represented. The lips were a framework of wire, covered with rubber which had been stuffed with cotton batting. Rubber cheeks enclosed the mouth cavity, and the tongue was simulated by wooden sections - likewise covered by a rubber skin and stuffed with batting. The parts were actuated by levers controlled from a keyboard. A larynx 'box' was constructed of tin and had a flexible tube for a windpipe. A vocal-cord orifice was made by stretching a slotted rubber sheet over tin supports. [Flanagan, 1994] |
| 1937 | R. R. Riesz's talking mechanism
In 1937, R. R. Riesz demonstrated his mechanical talker which, like the other mechanical devices, was more reminiscent of a musical instrument. The device was shaped like the human vocal tract and constructed primarily of rubber and metal with playing keys similar to those found on a trumpet. The mechanical talking device ... produced fairly good speech with a trained operator ... With the ten control keys (or valves) operated simultaneously with two hands, the device could produce relatively articulate speech. Riesz had, through his use of the ten keys, allowed for control of almost every movable portion of the human vocal tract. Reports from that time stated that its most articulate speech was produced as it said the word 'cigarette'. [Cater, 1983] 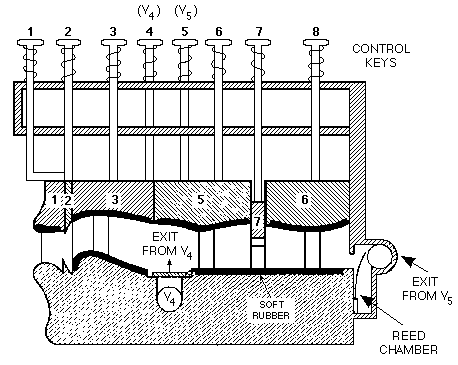 |
| 1989 |
The Talking Machine (1989-1991): 32 pipes and air valves, wind chests, magazine bellows, blower, computer. 230cm. The white box at the bottom is a sound-proof casing enclosing the blower. The flat white box above that is a magazine bellows which evens out the air pressure no matter how many pipes are being played. The air goes up the red hoses to the four wind chests which carry the pipes. The wind chests are transparent so the movement of the electromagnetic valves can be seen and this is further reinforced by LEDs attached to each valve. The black cables carry the signals from the computer with the user interface to the valves. |
| 2001 | Takayuki Arai has built many working physical models of the vocal tract for teaching and learning.
 |
| 2009 | Waseda University Mechanical Talkers - a series of robot talkers by Atsuo Takanishi.
We developed WT-7RII (Waseda Talker No. 7 Refined II) in 2009, which have human-like speech production mechanism. WT-7RII consists of the mechanical models of the lung, the vocal cords, the tongue, the jaw, the palate, the velum, the nasal cavity and the lips. These mechanical models are designed based on human anatomy and they have same size as an adult human male to have similar acoustic characters. [Atsuo Takanashi]  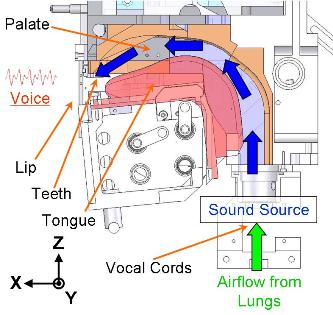 |
 The
The Language of the week
This week's language is Sandawe, a language spoken in the Kondoa district of central Tanzania. [ Source material ].

- What varieties of click sounds do you notice in the Sandawe passage above?
- Identify the meaning of all the diacritics used in the Sandawe transcription.
Reflections
You can improve your learning by reflecting on your understanding. Come to the tutorial prepared to discuss the items below.
- What constrains which air pressure waves are called sound?
- Produce two speech sounds that only differ in loudness. In pitch. In timbre.
- What differences do you hear between speaking on a pulmonic ingressive air-stream compared to a pulmonic egressive air-stream?
- What sounds are generated using a glottalic egressive air-stream? A glottalic ingressive air-stream? A velaric ingressive air-stream?
- What is meant by "speaking to be understood"?
- What would "speaking to be understood" predict for an adult talking to an infant?
- Speculate on connections between the co-operative principle in pragmatics and "speaking to be understood".
Word count: . Last modified: 09:58 22-Oct-2017.