10. Speakers and Accents
Key Concepts
- Speakers vary at all levels in the linguistic hierarchy – from physical form of vocal apparatus to linguistic habits
- Speakers are also highly variable in the way they use speech
- It is not always possible to identify or discriminate speakers from their voices
- First language accents arise and change for social purposes
- Second language accents are strongly influenced by the phonetic and phonological form of the speaker's first language
- Speaker recognition/comparison has application in Forensics and in Biometrics
Learning Objectives
At the end of this topic the student should be able to:
- describe the main speech characteristics that differ according to the physical size of speakers
- give examples of speech characteristics that differ across speakers
- give examples of speech characteristics that differ across accents
- account for the weaknesses of voice identification in a voice line-up
- criticise the idea of voiceprint as a reliable means of speaker identification
Topics
- Speaker Variation
It is a common experience that we can identify at least some of the people we know from listening to the sounds of their speech. That is, some speakers vary in the way they speak to such a degree that in some situations their speech allows their identity to be established. However you should not take this simple fact as meaning that (i) all speakers have unique voices, or (ii) pairs of speaker can always be told apart, or (iii) a given speaker is recognisable whatever they do. These are not valid conclusions that can be drawn from the observed facts. Unfortunately these fallacies have blighted the history of the field of speaker recognition.
Let's consider the ways in which a person's identity could be reflected in their speech:
- Physical differences: The physical size of a person affects both the size of the larynx and the size of the vocal tract. Larynx size affects the range of fundamental frequencies produced during phonation, with larger larynges producing lower repetition rates. Vocal tract size affects the size of the acoustic cavities that give rise to formants, with larger vocal tracts giving rise to lower formant frequencies. Although larynx size and vocal tract size are two different aspects, they are often correlated, meaning that speakers with low-pitched voices also tend to have low frequency resonances. Larynx size changes at puberty, but with larger effects in men than women.
- Physiological differences: Speakers are also likely to vary in the anatomy of the vocal apparatus and its neural control. One person's vocal folds, for example, may vibrate more irregularly than another's; one person's respiratory system might deliver less air volume at lower pressures than another; or one person may have weaker articulatory muscles and so speak more slowly or less clearly. Neural control over the articulators may vary in terms of speed, accuracy or adaptability.
- Phonetic differences: Even with the same sized larynx, speakers may vary in their default pitch or voice quality. Speakers may use different habitual settings for jaw height, lip position or velum height. Speakers may also use different habitual gestures for the execution of phonological units: the exact position and timing of the tongue tip movement, say; or the degree of rounding and nasality used for particular segments. The speaker's accent will affect the exact quality of vowels and other segments, or the choice of allophonic variants (differing articulations for the same phonological segment) in different contexts. Speakers may show differences in prosody: preferences for certain intonational tunes, speaking rate, rhythm or fluency.
- Phonological differences: Accent differences can also show up as changes to the inventory of phonological segments used in the lexicon, or to distributional differences in how the inventory is exploited in different groups of words. Speakers may even have idiosyncratic pronunciations of particular words.
- Lexical and syntactic differences: At lexical and higher linguistic levels, a speaker may show preferences for particular words, or preferences for certain word sequences, or preferences for certain syntactic constructions.
- Cognitive differences: Speakers as individuals may show preferences for certain topics of discussion, express certain attitudes to events in the world, be knowledgeable about certain fields, differ in intelligence or personality.
From this long but non-exhaustive list we note that (i) differences can be exhibited at all levels of linguistic description, and (ii) it is likely that any single characteristic will occur in many speakers (none are going to be unique to the speaker). For such potential sources of speaker information to be useful in establishing a speaker's identity it needs to be established that some combination of the factors are distinctive and reliably found in their speech.
- Speaker Variability
Although there are many possible ways in which speakers may vary in their speech, we also have to take into account the fact that speech of a single speaker is itself highly variable:
- Content: changes to the linguistic content of a recording might affect the distribution of fundamental frequencies used, the range of spectral qualities and spectral dynamics.
- Speaking style: changes to the required intelligibility, familiarity of the interlocutor, or formality of the situation will affect the speech.
- Emotion: the nature of the emotional state of the speaker and their level of arousal will affect their speech.
- Health: the health of the speaker may change.
- Age: people's speech may vary as they get older.
- Acoustic environment and channel: the recording itself can be affected by noise, reverberation or audio channel.
- Deliberate disguise/imitation: the speaker may be acting, imitating another speaker or deliberately trying to disguise his voice.
We must take into account the possibility of variability in a person's speech when we are trying to determine their identity: not just to allow their speech to vary from the average, but also to accommodate the possibility that someone else's speech might have given rise to the observed measurements:
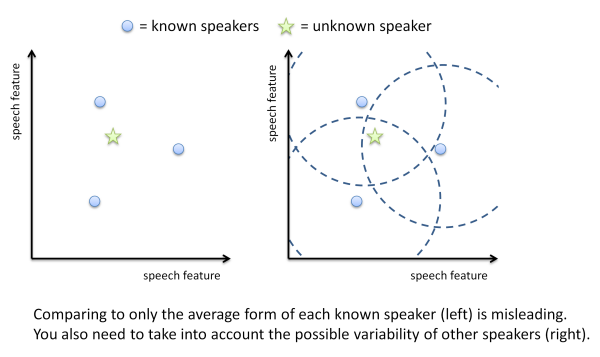
- Accents
What is an accent? These definitions have been adapted from Laver 1994.
- An accent is simply the manner of pronunciation of a speaker. Everyone, in this definition, speaks with an accent. An accent involves both phonological and phonetic aspects of pronunciation.
- A dialect refers to the types and meanings of the words available to a speaker and the range of grammatical patterns into which they can be combined. Dialects may be differentiated by their morphological, syntactic, lexical and semantic patterns and inventories. A dialect may be associated with more than one accent.
- A language is made up from a group of related dialects and their associated accents. How dialects are grouped into languages can be geopolitical decision rather than a linguistic one.
- An idiolect is the combination of dialect and accent for one particular speaker.
In the British Isles, the dominant dialect is called Standard English (the word 'Standard' here has the meaning 'everyday' rather than 'correct'). Standard English is widely understood in all English-speaking countries.
However the British Isles has many differentiable accents. Some are associated with particular regions of the country, such as Geordie, Scouse and Cockney. Other accents are non-regional, in that speakers of these accents can be found in all areas. The most well-known non-regional accent of the British Isles is Received Pronunciation (RP), although it is now only spoken by a minority.
An example of two similar dialects that are nevertheless called different languages is Norwegian and Swedish. It has been said that a language is just a dialect with an army and navy.
- Accents of the British Isles
The British Isles has a number of well-described regional accents.
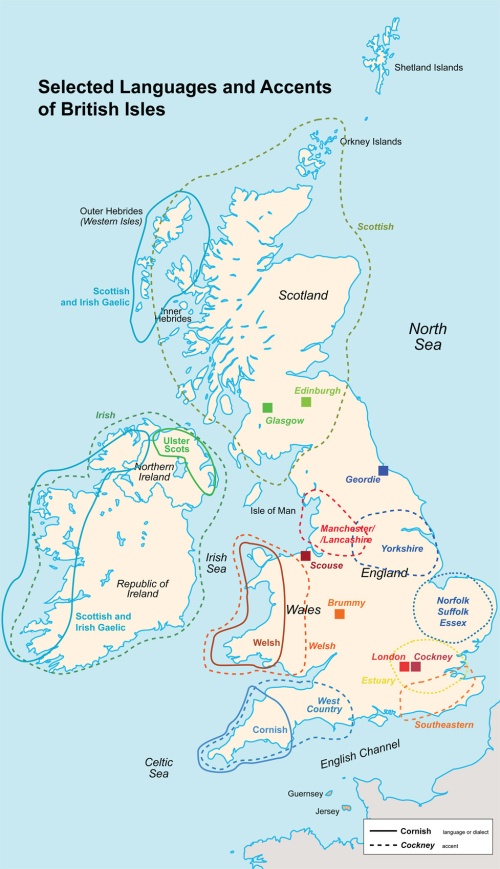
These accents vary in a number of ways. Some variation is due to changes in the inventory of phonological units, or to their use within the lexicon. For example, Northern and Southern varieties of British English differ in the selection of /ɑː/ and /æ/ or the selection of /ʌ/ and /ʊ/ in certain words, some accents do not distinguish /f/ and /θ/, or "rhotic" accents articulate post-vocalic /r/. Other variation can occur in terms of the choice and distribution of allophones (phoneme variants), for example the use of clear and dark variants of /l/, or the use of the labio-dental approximant [ʋ] for /r/. Most obviously, accents vary in the precise articulatory implementation of the same phonemes, particularly vowels. Variations also exist in prosody, both in term of syllable timing and in intonation, for example Southern English
[bæːd] vs Northern[bæd] , or the use of "uptalk", a rising intonation used in statements.A list of the major variations in British English is given in Hughes, Trudgill & Watt, 2005:
Variation Example Vowel /ʌ/ merge "butter" as /bʌtə/, /bʊtə/ Vowels /æ/ and /ɑ/ "laugh" as /læf/, /lɑːf/ Vowels /ɪ/ and /i/ "city" as /sɪtɪ/, /sɪti/ Post vocalic /r/ "farm" as /fɑːm/, /fɑːrm/ Vowels /ʊ/ and /uː/ "pull" as /pʊl/, /puːl/ /h/ dropping "harm" as /hɑːm/, /ɑːm/ Glottal stop [ʔ] "button" as [bʌtən], [bʌʔən] Velar nasal /ŋ/ "walking" as /wɔːkɪŋ/, /wɔːkɪn/ /j/ dropping "news" as /njuːz/, /nuːz/ lonɡ mid diphthonɡs "boat" as [bəʊt], [bɔːt] - Forensic Phonetics
An important application of the phonetic study of speaker differences is in criminal cases. This is called Forensic Phonetics.
Forensic speaker comparison
Voice experts can be called upon to compare two or more speech recordings - one collected from the criminal and one collected from the suspect. The expert is asked his opinion as to whether it is possible (or likely) that the two recordings could have been made by the same speaker. Experts will use their own auditory phonetic judgements by listening for idiosyncratic characteristics like voice quality, speaking style and accent, often backed up by instrumental measurements of formant frequencies and prosody. See the tutorial on Forensic Phonetics in the readings.
Forensic Phonetics has a chequered history because of the claim made by some authorities that "Voiceprints" (i.e. spectrograms) are as accurate as fingerprints for identification. I hope the discussion above has convinced you that this is not the case. Just because you can choose between a few of your friends and relations from their voice does not mean that all speakers have unique voices, nor that speakers are recognisable in all circumstances. Forensic Phoneticians sometimes have to stand up in court and justify the procedures they have used and the conclusions they have drawn, it is beholden on them to be honest about the reliability and efficacy of their techniques. Unfortunately such high professional standards have not always been achieved.
Forensic voice line-ups
Determining the identity of speakers from their voice is found in another forensic area. This is where the voice of the criminal was not recorded at the scene of the crime, but was heard by a witness to the crime (an ear-witness). If the police have a suspect for the crime, they might present a recording of the suspect to the witness. To try to avoid bias, this is usually done in the form of a voice line-up.
A voice line-up is like an identity parade; the voice of the suspect is included in a list of distractor voices collected from non-suspects. The witness to the crime listens to all the voices in random order then picks out the voice they remember from the line-up.
While apparently scientific, the voice line-up is not without problems. For example, how are the distractor voices chosen? What if the suspect has a distinctive accent or voice quality - should the distractors be chosen to have the same? Many experiments have shown that listeners have a very poor memory for the qualities of speaker voices, and the results of a voice line up need to be interpreted with care. A famous criminal case involving voice identification was the Lindbergh baby kidnapping case.
Voice disguise
Systems for disguising the voice are sometimes useful in legal cases where the identity of a witness needs to be hidden. Typically disguise uses pitch shifting and spectral warping tools developed for the music industry. These can change the apparent larynx size and vocal tract size of the speaker, and hide some aspects of voice quality. However they are not very effective at disguising accent. Testing the effectiveness of voice disguise and evaluating the performance of human listeners for speaker identification are active areas of research.
- Speaker recognition systems
Automatic systems for recognising speakers are of two types:
- speaker identification systems select one speaker from N known speakers on the basis of their voice;
- speaker verification systems confirm the identity of a single named speaker on the basis of their voice.
Speaker verification systems are more widely employed at the present time, to authenticate access to buildings or bank accounts for example. The technology for speaker verification is well developed and is quite robust with error rates around 1% in laboratory tests (i.e. 1% false rejects and 1% false acceptances). Systems can be divided into text-dependent and text-independent systems, the former being of better performance. In a typical system, speakers enrol by recording some known sentences - say a few minutes of speech in total. From the enrolment recordings a statistical model is made of the spectral envelopes used by each speaker. In addition a population model is built from the combination of all enrolled speakers. In identification, a challenge recording is compared to each statistical model and the best fitting model chosen. In verification, the probability that the supposed speaker's model produced the speech is compared with the probability that the population model produced the speech. Only if the speech is more likely to have been produced by this speaker than by anyone in the population would the speaker's identity be confirmed.
Readings
Essential
- V. Dellwo, M. Ashby, M. Huckvale, "How is individuality expressed in voice? An introduction to speech production & description for speaker classification", in Speaker Classification II, C.Müller (ed), Springer Lecture Notes in Artificial Intelligence, 2007. [On Moodle]
Background
- Anders Eriksson, Tutorial on Forensic Speech Science.
Laboratory Activities
This week's lab session will look at speaker variation through these activities:
- Testing your ability to recognise class members from their voice (with and without disguise)
- Trying out an automatic speaker recognition system
Reflections
You can improve your learning by reflecting on your understanding. Come to the tutorial prepared to discuss the items below.
- Think of factors that might affect the reliability of earwitness evidence.
- What criteria should one use to choose "foils" for a voice line-up?
- Why might the performance of a speaker recognition system in the laboratory not be a good predictor for its performance in the field?
- Why is RP considered a non-regional accent?
- Why might a (Northern British English) speaker accidentally pronounce "pasta" as [pɑːstə] rather than [pæstə].
- Suggest reasons why accents change over time.
Word count: . Last modified: 10:45 09-Mar-2018.