2. Measuring Timing and Rhythm
Learning Objectives
- to gain experience in collecting duration measurements from annotated speech signals
- to understand why the log normal distribution provides good summary statistics of durations
- to use a statistics program to plot distributions and measure means and variances
- to use a statistics program to compare the means of samples
- to learn about measures of speech rhythm
- to learn about the modelling of duration in context using CART
Topics
- Why study durations?
Segmental durations are interesting because they are influenced by many linguistic and phonetic factors. A model that predicts well how durations change with context will also then be a good model for how the context influences production. Durational cues may also useful in distinguishing different speakers, accents, languages or speech disorders. Predictive models of duration from text are used in text-to-speech conversion systems.
- Contextual influences
The duration of a segment is influenced by factors at many levels. At the lowest level, the category of segment and the category of neighbouring segments seem to affect its duration. The position of the segment in its syllable and the other constituents of the syllable are also important. Duration can also be affected by the position of the syllable in the prosodic foot and its position in the word. The position of the word or foot in the phrase can also have an effect, as can the selection of focus and pitch accents. Overall durations are also affected by speaking rate, which in itself can be affected by communicative context, style and emotion. [See Campbell, 2000]
Examples of well known duration factors are:
- Shortening of vowel durations before fortis consonants (pre-fortis clipping)
- Shortening of consonants in clusters
- Shortening in vowels in closed syllables
- Shortening of unstressed syllables
- Lengthening of accented syllables
- Foot-internal shortening
- Phrase-final lengthening
- Simple duration model
Klatt (1979) popularised a model of segmental duration in which segments have an intrinsic duration and an intrinsic compressibility, then each factor has a multiplicative influence, with multiple factors combining to give an overall duration scaling.
Klatt's basic formula is given by
DUR = MINDUR + (INHDUR-MINDUR) * PRCNT
DUR is the target duration for the segment, MINDUR the minimum duration for the segment, INHDUR is the inherent duration, and PRCNT is the proportion by which the segment is lengthened or shortened over its inherent duration.
Klatt's duration rules may then be summarised as:
- Pause insertion rule: insert a 200ms pause before each sentence internal main clause and at boundaries delimited by comma, but not before relative clauses.
- Clause-final lengthening: the vowel or syllabic consonant in the syllable just before a pause is lengthened by PRCNT=1.4. Any consonants between this vowel and the pause are also lengthened by PRCNT=1.4.
- Non-phrase-final shortening: syllabic segments are shortened by PRCNT=0.6 if not in a phrase-final syllable. A phrase-final postvocalic liquid or nasal is lengthened by PRCNT=1.4.
- Non-word-final shortening: syllabic segments are shortened by PRCNT=0.85 if not in a word-final syllable.
- Polysyllabic shortening: syllabic segments in a polysyllabic word are shortened by PRCNT=0.8.
- Non-initial consonant shortening: consonants in non-word initial positions are shortened by PRCNT=0.85.
- Unstressed shortening: unstressed segments are half again more compressible than stressed segments (i.e. MINDUR=MINDUR/2). Then both stressed and secondary-stressed segments are shortened by a factor depending on segment type: syllabic in word medial syllable PRCNT=0.5; syllabic in other positions PRCNT=0.7; prevocalic liquid or glide PRCNT=0.1; all others PRCNT=0.7.
- Lengthening for emphasis: an emphasized vowel is lengthened by PRCNT=1.4.
- Postvocalic context of vowels: the influence of a postvocalic consonant or sonorant-stop cluster on the duration of a vowel is given below. The consonant must be in the same morpheme as the vowel and be marked as unstressed. In a postvocalic sonorant-obstruent cluster, the obstruent determines the effect on the vowel and on the sonorant. Open syllable, word-final PRCNT=1.2; before a voiced fricative PRCNT=1.6; before a voiced plosive PRCNT=1.2; before an unstressed nasal PRCNT=0.85; before a voiceless plosive PRCNT=0.7; all others PRCNT=1.0. If non-phrase final, change PRCNT to 0.7+0.3*PRCNT.
- Shortening in clusters: segments are shortened in consonant-consonant sequences (disregarding word boundaries, but not across phrase boundaries), and are also modified in vowel-vowel sequences. Vowel followed by a vowel PRCNT=1.2; vowel preceed by a vowel PRCNT=0.7; consonant surrounded by consonants PRCNT=0.5; consonant preceded by consonant PRCNT=0.7; consonant followed by consonant PRCNT=0.7.
While Klatt's model was influential at the time, it is not without problems. The mathematical model of compressibility is too simple to model factors which have non-linear effects. There are likely to be interactions between rules which mean that they can't be modelled independently. Lastly the whole model is hard to change or optimise since changes to one rule changes the effects of others.
- Corpus analysis
Modern duration modelling is based around large annotated corpora. Distributions of durations expressed in milliseconds tend not to be normally distributed (because durations have a lower limit but no upper limit). A logarithmic transform is commonly applied to achieve a normal shape [see Rosen, 2005]. See figure below for example.
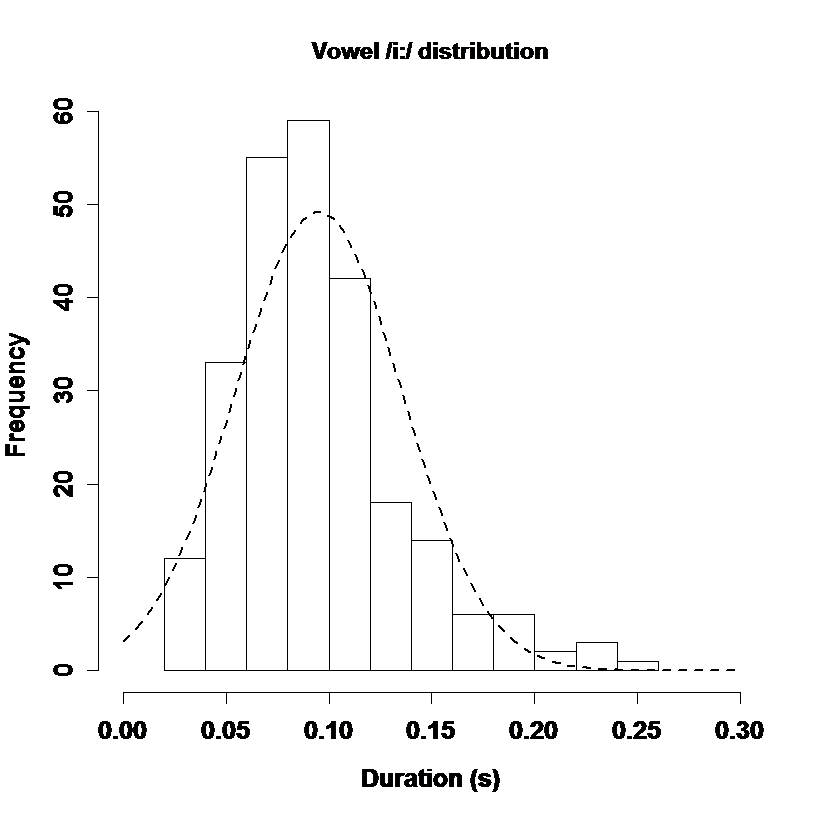
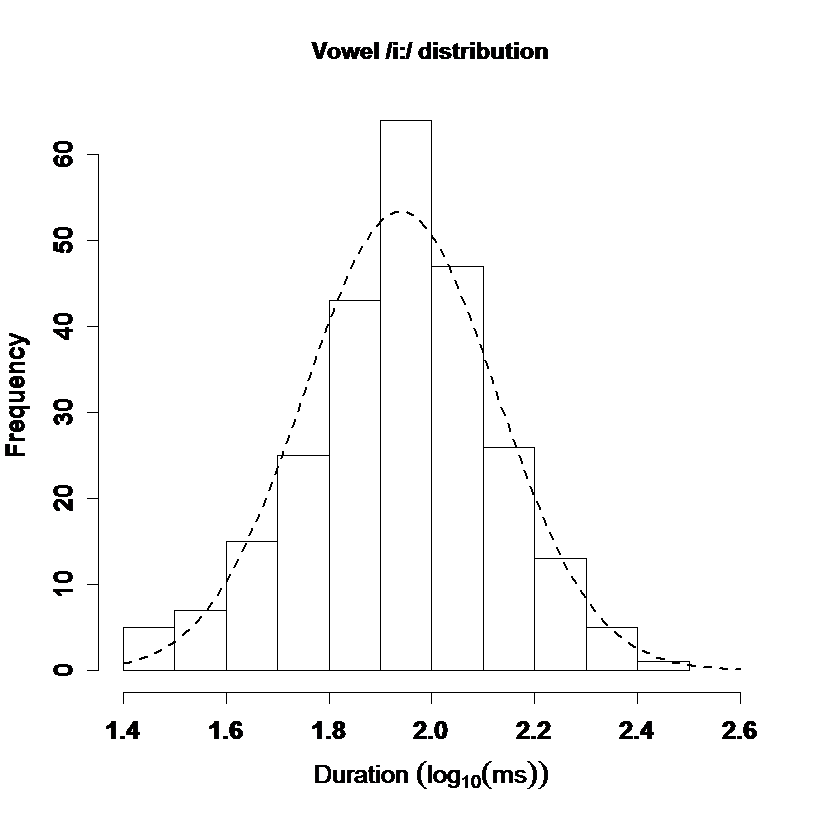
Segment durations measured in seconds are not normally distributed. Here 250 instances of /i:/ from one speaker are analysed. When durations are measured in seconds, the shape is significantly different to normal, however when measured in terms of log10(ms),the distribution is better shaped.
When durations are collected from a corpus, it is important to record the phonetic and prosodic context of each segment so that modelling can include them as factors.
- Modelling of contextual factors with CART
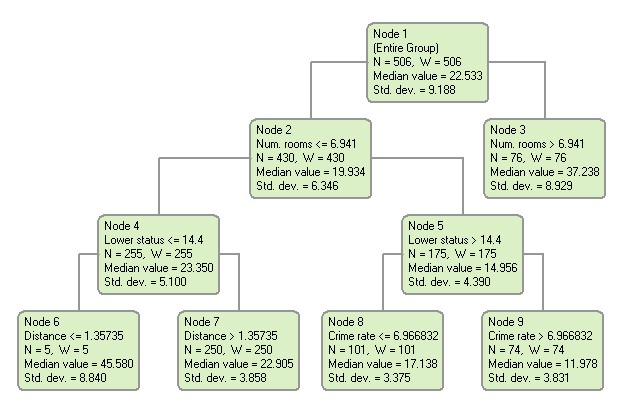
The use of a multiplicative model for connecting segmental durations with contextual factors has gone out of fashion, being replaced by data-driven techniques which make fewer assumptions about how factors influence duration. A popular approach is the use of Classification and Regression Trees (CART). A CART consists of a binary branching tree, where a question about the segment and its context is posed at each node. The tree is traversed from the root node to the leaves. If the question (e.g. “Does the segment precede a voiceless consonant?”) on a node is answered yes, then one branch below the node is taken, otherwise the other branch. Eventually a leaf node is reached which contains the mean and standard deviation for the segments which end up at that node. The tree is built from training data, and optimised to best predict some unseen development data. The tree can then be evaluated for performance against some held-out test data.
The diagram below gives an example of a CART tree: [Source image]
- Identifying rhythmical differences between languages
Segmental durations can also be used to collect long-term statistics about rhythmical properties of utterances. A number of speech rhythm measures have been proposed [e.g. Ramus, et al, 1999], based on aspects like the percentage of time spent in vowels as opposed to consonants, or the variability in vowel or consonant duration.

These measures have been used to distinguish between languages that have a syllable-timed rhythm (e.g. Spanish) and those that have a stress-timed rhythm (e.g. English). The figures below show the range of these measures collected from groups of speakers from a number of different languages.
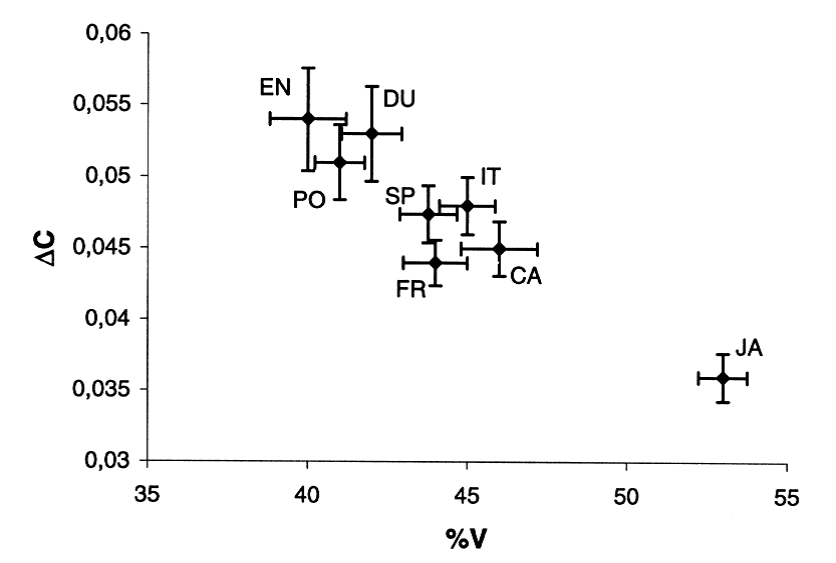
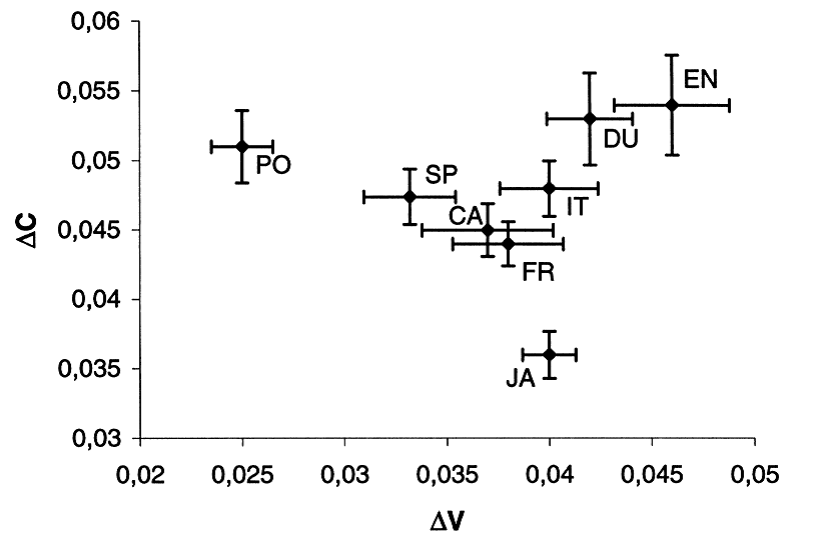
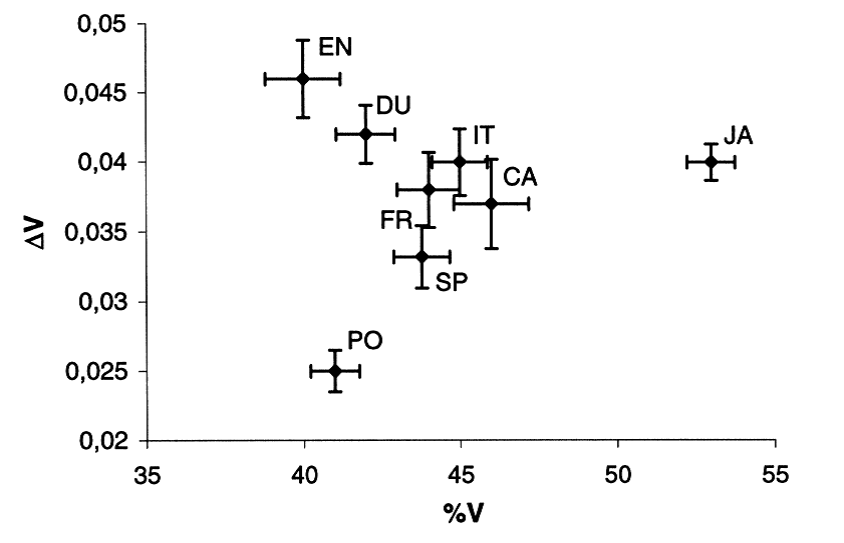
Speech rhythm measures for a number of languages. From Ramus et al (1999). [EN=English, PO=Polish, DU=Dutch, FR=French, SP=Spanish, IT=Italian, CA=Catalan, JA=Japanese]
These rhythmical differences between languages are interesting because their causes are still unclear. Are rhythmical differences driven by the segmental phonology of the language or by other general factors of phonetics which apply across multiple languages?
- Comparison of means
Given two samples (e.g. durations of the same segment in two different contexts) we can perform a hypothesis test to determine the likelihood that any observed difference in sample means was due only to chance effects. This probability can be calculated using a t-test. Measurements of the two samples are supplied to the t-test procedure, and the outcome is the probability of the null hypothesis, that is the probability that sample differences are due to chance alone. If that probability is small, then we reject the null hypothesis (because it is unlikely to be true) and accept the alternative hypothesis – namely that the observed sample differences are due to some real differences between the underlying populations. The criterion for a small probability is often taken to be 0.05, that is: less than one experiment in twenty would give these results by chance alone.
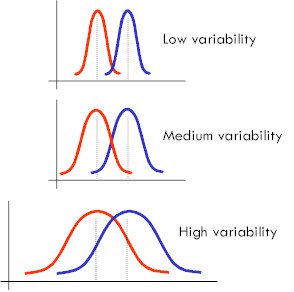
A t-test measures the difference in sample means in terms of the likelihood that two samples could have arisen by chance from the same underlying population.For a given difference, the greater the size of the samples and the smaller the sample variances, the less likely that the observed difference will be due to chance.
References
- Klatt, D.H. “Synthesis by rule of segmental durations in English sentences”, in B.Lindblom & S.Ohman, Frontiers of Speech Communication Research, Academic Press, 1979, 287-299.
Readings
- N.Campbell, "Timing in Speech: A Multi-Level Process", in M.Horne (ed), Prosody: Theory and Experiment, Kluwer Academic Publishers (2000), 281-334. [on Moodle]
- F.Ramus, M.Nespor, J.Mehler, "Correlates of linguistic rhythm in the speech signal", Cognition, 73 (1999) 265-292. [on Moodle]
- K.Rosen, "Analysis of speech segment duration with the log normal distribution: A basis for unification and comparison", Journal of Phonetics 33 (2005) 411–426. [on Moodle]
Laboratory Exercises
To run these exercises, you need to run CYGWIN from the desktop, and copy the scripts folder to the home directory. Then source the env.sh script to set up the working environment:
cp –r y:/EP/scripts ~ cd ~/scripts source env.sh
- Vowel durations
- Your recordings of the BKB sentences can be found in: y:/EP/bkb/yourname/bkb*.sfs. You can view any file with, e.g.:
- Run script 'voweldur.sml' to collect durations of the monophthongal vowels from all speakers:
- Start SPSS and open the 'monovoweldur.csv' data table. The full file name will be:
- You will see durations in ms for each vowel segment for each sentence for each speaker. Using Transform | Compute Variable, create a new column of the durations in log ms.
- Using Graphs | Legacy Dialogs | Histogram, plot distributions of all vowel durations in ms and then in log ms. Which has a more normal shape?
- Using Graphs | Legacy Dialogs | Boxplot, create a box-plot of vowel duration as a function of vowel category. Which vowels are shortest? Longest? Most variable? Least variable? Do the results fit your intuitions about vowel duration?
- Using Analyze | Compare Means | Independent Samples t-Test, perform a t-test between two vowel categories to see if the difference in means could just be due to chance.
- Classification and Regression Trees
- At the CYGWIN terminal, run the following script to collect durations and syllabic contexts for the monophthongal vowels.
domakefeat.sh
- Read the data table produced "dur.dat" into SPSS. The first column is the vowel duration in ms, the second column is the vowel label, and the remaining columns represent the sentence context: LNG=(+)long or (-)short vowel, STR=(+)stressed or (-)unstressed syllable, CLS=(+)closed or (-)open syllable, VOI=followed by (+)voiced or (-)voiceless consonant, PHR=phrase (-)non-final or (+)final.
- Using Analyze | Classify | Tree , build some Classification and Regression Trees to explain the duration in terms of the context features. In the Tree dialog, set the "Validation" option to "Crossvalidation", and the "Criteria" options to Maximum tree depth=5, Minimum cases for Parent node=20 and Minimum cases for child node 10. Set the dependent variable to DUR and use all the other features as predicting factors. Set the "Growing Method" to "CRT". Study the form of the tree generated to look for understandable "rules" of duration.
- Next try and build a tree without using the vowel labels (i.e. just the contextual factors) is the performance worse? The "Risk" value represents the quality of fit (sum of variance in nodes). Are different rules used?
- Rhythm Measures
- The Bonn Tempo Corpus is a collection of recordings of Czech (C), English (E), French (F), German (D) and Italian (I) speakers analysed with a large set of rhythm parameters.
- We will be looking at these rhythm measures:
- varcoC - coefficient of variation of durations of consonant intervals (coefficient of variation = standard deviation/mean)
- varcoV - coefficient of variation of durations of vowel intervals
- nPVI_C - normalized pairwise variability index of consonant intervals
- nPVI_V - normalized pairwise variability index of vowel intervals
- Open 'bonntempo_l1.csv' in SPSS and plot boxplots of how the parameters varcoC, varcoV, nPVI_C, nPVI_V vary by language (L1).
- Using Data | Aggregate, compute a new dataset from the mean scores for each language. Use L1 as the break variable, and compute means for varcoC, varcoV, nPVI_C, nPVI_V, outputting to a new data set "bonnavg".
- Using Graphs | Legacy Dialogs | Scatter/Dot, plot a scatter graph of the languages against pairs of these mean values. Do the positions of the languages make sense in terms of similarities and differences in rhythm?
Eswin y:/EP/bkb/yourname/bkb01.sfs
sml –ian monovoweldur.sml y:/EP/bkb/*/bkb*.sfs >monovoweldur.csv
c:/cygwin/home/b07_lab/scripts/monovoweldur.csv
Reflections
- Why might sound types have an "intrinsic" duration?
- What are the advantages and disadvantages of a multiplicative model of how factors influence duration?
- What are the advantages and disadvantages of a data-driven model of duration prediction?
- Why might greater variability in vowel or consonant duration point to a stress-timed language?
- Why is it a bad idea to perform multiple t-tests on the same data set when looking for significant differences?
Word count: . Last modified: 11:48 16-Jan-2018.