1. Audio recording and transcription
Learning Objectives
- to learn good practice in making digital speech recordings for phonetic research
- to understand how recording equipment may be judged for quality
- to understand the importance of meta-data in the construction of speech corpora
- to understand how symbolic labels can be associated with the signal at different levels of linguistic description
- to appreciate that phonetic segmentation is difficult, but nonetheless useful
- to experience the use of a transcription notation
- to experience use of manual and automatic transcription tools
Topics
- The changing face of experimental phonetics research
New instrumental methods
New, less invasive methods for instrumenting articulation, such as electro-magnetic articulography (EMA) and real-time magnetic-resonance imaging (rtMRI) are providing much more quantitative data about the processes of speech planning and execution. Improved mathematical modelling techniques provide better means for building predictive models from data. More coherent theoretical positions relating underlying phonological representations to surface articulatory gestures provide new frameworks for hypothesis testing.
Ease of making and analysing speech audio recordings
Speech audio analysis remains the most used instrument for experimental phonetics. Portable digital audio recorders, miniature condenser microphones, high-quality analog-to-digital conversion, large digital memories and long battery life make the process of collecting high-quality speech recordings easier than ever. Faster computers, greater storage capacities and faster network speeds make speech signal analysis quicker to perform. Better speech analysis tools provide more accurate measurements of signal properties.
Open access research and open data & tools
A shift to open access publishing makes it easier for researchers to find published work related to their research topics. Under the heading of "open data", it is increasingly the view of the research community that researchers should publish all the tools and data used to derive journal paper results. When speech audio is collected to investigate some phonetic hypothesis, it is wasteful to then discard the data afterwards, not only because the data might be re-used by yourself or someone else, but also because anyone wanting to reproduce your research will need access to your data.
Public corpora
Increasingly large amounts of speech data are now publicly available, reducing the need for individual researchers to collect their own data. However, well-constructed speech corpora are expensive to make and sometimes access to corpora entails a fee, even for research purposes. Generally however, the fee will be less than the cost of recording the data yourself. The two largest commercial speech corpora agencies are Linguistic Data Consortium (LDC) and European Language Resources Association (ELRA). Research groups also band together to share data free of charge to other researchers, for example OSCAAR or CHILDES.
Corpora of speech recordings collected within a clinical context are also becoming more widely available. The idea here is for the collection of large numbers of audio recordings with sufficient meta-data (i.e. indexical information) such that the recurring speaking characteristics of particular groups of speakers can be analysed by acoustical and statistical means. Such analysis may then lead to new means of diagnosis, new methods for the assessment of individuals or for the evaluation of new therapies.
- Making good speech recordings
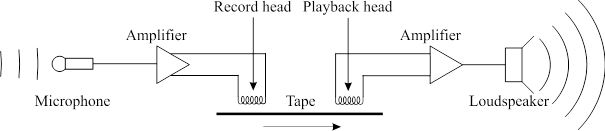
The recording chain
You can consider audio recording and playback as involving a chain of different components and a sequence of transformations of the signal: the microphone converts sound to electricity; the pre-amplifier increases the size of the microphone signal; the recorder converts the signal to a physical form which can be stored permanently; the storage medium holds the recording but may itself deteriorate with time; the player reconverts the stored form back to a signal; the amplifier makes the signal large enough to drive a loudspeaker which converts signals back into pressure waves. Each component of the chain is a system that may change the signal passing through it. The overall quality of the chain is the combination of the quality of the components.
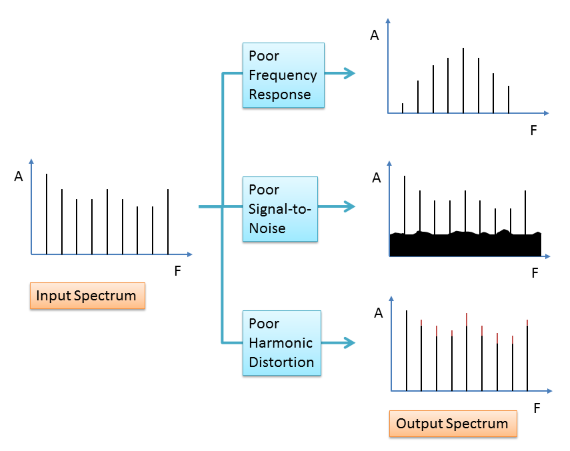
Measuring recording component quality
A number of standard measures are used to describe the quality of the component systems in the recording chain:
- the frequency response of a system shows us how it changes the spectrum of the signal passing through, typically this is described using the range of frequencies which have a response within 3dB of the peak response. For speech recordings you need to ensure that the recorder is capable of capturing frequencies between 100 and 10,000Hz.
- the signal-to-noise ratio (SNR) is the ratio of the average signal level to the average noise level, where the noise is any unwanted signal added to the input by the system. For speech recordings you want any added noise to be more than 50dB below the level of the speech.
- the harmonic distortion of a system is a measure of how many new harmonics are introduced by changes to the shape of the input signal. For speech recordings you want the size of any distortion components to be more than 50dB below the level of the speech (i.e. less than 0.3%).
Choosing microphones
Microphones come in three main types: crystal or piezo microphones which are cheap and of poor quality; dynamic microphones which operate with a moving coil and can be found for moderate price and good quality; condenser or electret microphones which exploit capacitance changes and which tend to be more expensive but of higher quality than dynamic microphones. Most condenser microphones require a separate power supply which makes them less convenient unless they can be powered from the recorder.
Microphones also vary according to their polar pattern, that is, their directional sensitivity. Omni-directional microphones have similar sensitivity in all directions, cardioid pattern microphones have greater sensitivity in one direction and are suited for noisy environments where the microphone can be pointed at the speaker.
- Digital audio
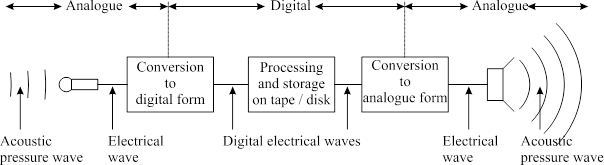
Analogue versus Digital Audio
In an analogue recorder, the storage medium stores an "analogy" of the pressure waveform, that is, the physical character of the medium changes in the same way that the pressure changes. However this means that the characteristics of the recording is limited by the range of physical properties of the medium; and also that damage or degradation of the medium also damages or degrades the original signal.
In a digital recorder, the storage medium only stores binary data representing numerical values of the pressure wave amplitude sampled at regular intervals. As long as the numbers themselves can be recovered, the value of the numbers will not change if the medium is damaged or degraded. The reproduction should be identical each time.
Sampling
When a speech recording is digitised for manipulation by a digital computer, the continuous sound pressure signal is sliced into discrete time intervals and the amplitude of the signal in each interval is recorded as a whole number. The division into discrete time intervals is called sampling and is performed at a given sampling rate specified in terms of the number of signal samples generated per second. A very common sampling rate is 44,100 samples per second, since this was the rate chosen by Sony when the compact disc format was being designed. This is a very high rate, but it ensures that the digital signal is sampled fast enough to capture the highest sinusoidal frequencies detectable by the ear. Mathematical analysis of sampling tells us that the highest frequency faithfully captured will be at half of the sampling rate. In practice, filters are employed in the analogue-to-digital conversion step which ensure that the analogue signal does not contain significant energy above about 0.45 of the sampling rate prior to sampling. Since speech signals have very little energy and very little phonetically useful information above 8000Hz, sampling rates of 16000, 20000 or 22050 samples/sec are also commonly found. 16000 samples/sec is probably the lowest rate one would want to use for acoustic analysis.
The storage of the amplitude value as a whole number is called quantisation. Each sampled amplitude is stored as a whole number within a limited range, and the vast majority of recordings are made with a "16-bit" range of -32768 to +32767 (that is -215 to 215-1). This range provides a dynamic range for the sound much greater than is important for speech communication (16-bits provides a dynamic range of >90dB, whereas a spectrogram only has a dynamic range of 50dB typically). Although 8-bit samples and 12-bit samples are used in some telephone communication systems, these resolutions are not satisfactory for acoustic analysis. Modern digital audio recorders support 24-bit samples; the increased dynamic range can be useful in that the recorder is less likely to overload on excessively loud audio segments.
Compression
A stream of a monophonic speech recording consisting of 44100 samples per second of 16 bits per sample, gives a data rate of over 700kbits/sec. This rate is often considered extravagant for speech, and to make best use of storage media or network bandwidth, this rate is frequently reduced. There are two ways to reduce the data rate. Firstly, a speech signal contains a level of redundancy - that is some parts of the signal are predictable from other parts. Some of this redundancy can be exploited to reduce the signal data rate without changing the signal at all. This is called lossless compression, and can often reduce the data rate by a factor of 2. However even this rate is far higher than can be processed by our auditory system, and so means have been developed to reduce the data rate for an audio recording whilst preserving (to a greater or lesser extent) not the signal but the auditory impression of the signal. This is called psychacoustic or lossy compression, and can reduce the data rate by factors of 5-10. Since acoustic analysis may be more sensitive to changes in the signal caused by lossy compression than our hearing system, it is not a good idea to use lossy compression on speech signals recorded for scientific research if it can be avoided. If lossy compression is used, then it is advisable to maintain relatively high data rates, for example above 200kbits/sec. This corresponds to the data rate used in minidisc recorders, and is commonly used for 'transparent' coding of music. Studies have shown that such data rates have a relatively small impact on phonetic analyses (van Son, 2005).
File formats
Digital speech recordings can now be made on a wide variety of hardware devices, and this does lead to speech signals being stored in a variety of different computer file formats. The most common formats for storing uncompressed audio data are WAV, AIFF and AU. Uncompressed data is sometimes called "PCM" data, referring to an obsolete method of encoding the bit stream over a telecom channel. A popular form of lossless compression is called "FLAC" which has its own file format supported by a few software utilities. The most popular forms of lossy compression are currently MP3, OGG and AAC, each with its own file format. These are widely supported by media players and converters.
Digital speech recordings are also made in conjunction with video in an even wider range of devices and file types. Popular audio-video formats include: 3G2, 3GP, ASF, AVI, FLV, MOV, MP4, MPG, RM, SWF, VOB and WMV. These are widely supported by media players and converters. In general it will be necessary to separate the audio signal from the video signal and to convert audio from compressed to uncompressed before acoustic analysis. Commercial media conversion tools can be purchased for this purpose, although free tools can often also be found.
- Meta Data
Every speech recording should be associated with some meta-data which describes who was speaking, where and when the recording was made, and how it was recorded. Additionally it may include indexical information about the speaker, such as age, sex, accent or clinical group. It is worth emphasising that recordings missing such data are pretty worthless, since the goal of experimental phonetics is not just to find the average characteristics of speech, but to explore how speech varies across individuals and situations.
A transcription of the speech in a recording can form an extremely useful element of the meta-data. Even an orthographic transcription can be used to help find recordings in a corpus that contain pronunciations of particular words. A phonological transcription can provide an interpretation of what the speaker was trying to say, such that the realised acoustic form can be related to standard lexical forms.
A continuing challenge and topic for debate is whether transcripts should be "time-aligned" to the recording. That is, whether utterances or words or phonological segments should be associated with specific intervals of the audio signal. On the one hand, this provides a much finer level of indexation of the signals, such that sections corresponding to linguistic chunks can be located within a corpus automatically. In turn this might allow for automated analyses of the average signal properties across many occurrences of a word or segment. On the other hand time alignment of transcription by hand can be very labour-intensive, and since speech signals are not really discrete sequences of sound types, the resulting alignments are somewhat arbitrary. Combined with considerable transcriber variability, time-aligned narrow phonetic labels are of questionable use in most research.
A compromise position seems inevitable here. It is extremely useful to be able to find how a speaker chose to realise a particular phonological contrast through the acoustic analysis of many realised instances of that contrast. But it is extremely time-consuming and error-prone to hand-align transcription even at a phonological segment level. A balance position is perhaps to provide an aligned utterance-level orthographic transcription such that a phonological transcription could be generated and aligned by automatic means. Automatic generation of phonological transcription from orthography is usually performed by concatenating lexical pronunciations from a dictionary. For particularly disordered speech this may not be appropriate, so a non-time aligned phonological transcription could be provided instead. There are a number of systems for automatic alignment of transcription. However these systems do require good quality audio recordings, and even then the alignments may not be ideal. The general hope is that the gain in productivity allowed by automatic alignment over hand alignments will allow much more material to be annotated, and then the quantity of alignments available for analysis will compensate for their poorer quality.
Some software tools also support non-linear phonological representations, most commonly through multiple "tiers" of annotation, with potential synchronisation across tiers, so that a simple hierarchical structure can be represented. Levels might represent, e.g., intonational phrases, accent groups, feet, syllables, onsets, rhymes and segments. Software tools are essential to aid the construction of hierarchical annotation, particularly if each tier is also time aligned to the signal. The advantage of providing a hierarchical context for a segment of signal, is that it then becomes easier to search for and to analyse signal form conditioned on its position within the phonological structure of an utterance (Bombien, Cassidy, Harrington, John, & Palethorpe, 2006).
- Annotation
Choice of units
It is important first to establish what we are trying to label in the signal (Barry & Fourcin, 1990). We might label acoustic events: periodicity, silence, breath noise; we might label articulatory events: voicing, voice quality, bursts, transitions; or we might label according to our belief of the underlying phonological units involved. When we label phonological units, we make assumptions about the underlying to surface mapping: firstly that there is a linear ordering of units, secondly that there is a single time at which the influence of adjacent segments on the articulation/sound are “equal”. We call these the segmental assumptions of annotation. Furthermore, we usually label units using a small inventory of symbols, so we are always making subjective decisions about which label is appropriate in each context.
Notational schemes
For broad phonetic transcription, we prefer to use the SAMPA system. For a narrower transcription, you might consider the X-SAMPA extensions to SAMPA which cover the IPA chart. For intonational annotation, the most popular system is ToBI, although there are many others.
Tools
There are many tools to aid in transcription and annotation. We tend to use the Speech Filing System (SFS) for annotation, since it is free and works on Windows. Other tools such as Praat and EMU are commonly used for transcription. There is an increasing use of tools for the automatic alignment of transcription to the signal (e.g. analign in SFS).
References
- Bombien, L., Cassidy, S., Harrington, J., John, T., & Palethorpe, S. (2006). Recent Developments in the Emu Speech Database System. Proceedings of the Australian Speech Science and Technology Conference. Auckland, NZ.
Readings
Annotation:
- W.Barry & A.Fourcin, "Levels of labelling", Speech Hearing & Language, Work in Progress, UCL, 1990. [on Moodle]
- Gibbon, Moore & Winski (eds), Handbook of Standards and Resources for Spoken Language Systems, Mouton de Gruyter, 1997, Chapter 5. [in library]
Digital recording:
- R. van Son, "Can standard analysis tools be used on decompressed speech", Cocosda workshop, Denver, 2002. [on Moodle]
- Rosen & Howell, Signals and Systems for Speech and Hearing, (2013). Chapter 14: Digital systems. [in library]
Checklist for Speech Recording
- Obtain details about the speakers
- record physical character: e.g. age, sex, pathology, smoker, etc
- record language background: e.g. L1/L2, dialect, accent, level of education, profession
- obtain copyright permissions to use & distribute recordings
- Choose the right material to record
- read speech/spontaneous speech
- monologue/dialogue
- nonsense words, word lists, sentences, narratives
- Select the right environment
- quiet surroundings
- non-reverberant surroundings, soft furnishings
- Select the right equipment
- external microphone
- good quality recorder (uncompressed if digital)
- Take care in operation
- keep distance to microphone < 0.5m
- keep microphone out of airstream
- set recording levels to get a large input that does not overload recorder (e.g. -10dB lower than maximum)
- don't speak over subject's speech
- Manage your recordings
- keep details of recording, introduce recording, record rough times
- label tape/disk/memory storage
- interpret unintelligible speech
SEC Prosodic Transcription System
(Taken from G. Knowles, B. Williams, & L. Taylor (eds.), A corpus of formal British English speech. London: Longman, 1996)
The prosodic transcription was based on the system used by O'Connor and Arnold (1973) with some modifications:
- no distinction was made between symbols for onsets and nucleii
- the distinction between high and low variants was extended to all tones
- high and low were defined not with respect to the pitch range, but to the immediately preceding pitch level.
The following set of 15 special characters were used:
| Symbol | Description |
|---|---|
| ∣ | Minor tone-group boundary |
| ∥ | Major tone-group boundary |
| ˋ | High fall |
| ˎ | Low fall |
| ˊ | High rise |
| ˏ | Low rise |
| ˉ | High level |
| ˍ | Low level |
| ˇ | High fall-rise |
| ⌵ | Low fall-rise |
| ˆ | Rise-fall |
| • | Stressed but unaccented |
SAMPA Broad Phonetic Transcription System for English
(Taken from Gibbon, Moore & Winski (eds), Handbook of Standards and Resources for Spoken Language Systems, Mouton de Gruyter, 1997)
Consonants
The standard English consonant system is traditionally considered to comprise 17 obstruents (6 plosives, 2 affricates and 9 fricatives) and 7 sonorants (3 nasals, 2 liquids and 2 semivowel glides).
With the exception of the fricative /h/, the obstruents are usually classified in pairs as "voiceless" or "voiced", although the presence or absence of periodicity in the signal resulting from laryngeal vibration is not a reliable feature distinguishing the two classes. They are better considered "fortis" (strong) and "lenis" (weak), with duration of constriction and intensity of the noise component signalling the distinction.
The six plosives are p b t d k g:
| IPA | SAMPA | Word | Transcription |
|---|---|---|---|
| p | p | pin | pIn |
| p | p | bin | bIn |
| t | t | tin | tIn |
| d | d | din | dIn |
| k | k | kin | kIn |
| g | g | give | gIv |
The "lenis" stops are most reliably voiced intervocalically; aspiration duration following the release in the fortis stops varies considerably with context, being practically absent following /s/, and varying with degree of stress syllable-initially.
The two phonemic affricates are tS and dZ:
| IPA | SAMPA | Word | Transcription |
|---|---|---|---|
| tʃ | tS | chin | tSIn |
| dʒ | dZ | gin | dZIn |
As with the lenis stop consonants, /dZ/ is most reliably voiced between vowels.
There are nine fricatives f v T D s z S Z h:
| IPA | SAMPA | Word | Transcription |
|---|---|---|---|
| f | f | fin | fIn |
| v | v | vim | vIm |
| θ | T | thin | TIn |
| ð | D | this | DIs |
| s | s | sin | sIn |
| z | z | zing | zIN |
| ʃ | S | shin | SIn |
| ʒ | Z | measure | meZ@ |
| h | h | hit | hIt |
Intervocalically the lenis fricatives are usually fully voiced, and they are often weakened to approximants (frictionless continuants) in unstressed position.
The sonorants are three nasals m n N, two liquids r l, and two sonorant glides w j:
| IPA | SAMPA | Word | Transcription |
|---|---|---|---|
| m | m | mock | mQk |
| n | n | knock | nQk |
| ŋ | N | thinɡ | TIN |
| r | r | wronɡ | rQN |
| l | l | lonɡ | lQN |
| w | w | wasp | wQsp |
| j | j | yacht | jQt |
Vowels
The English vowels fall into two classes, traditionally known as "short" and "long" but owing to the contextual effect on duration of following "fortis" and "lenis" consonants, they are better described as "checked" (not occurring in a stressed syllable without a following consonant) and "free".
The checked vowels are I e { Q V U:
| IPA | SAMPA | Word | Transcription |
|---|---|---|---|
| ɪ | I | pit | pIt |
| e | e | pet | pet |
| æ | { | pat | p{t |
| ɒ | Q | pot | pQt |
| ʌ | V | cut | kVt |
| ʊ | U | put | pUt |
There is a short central vowel, normally unstressed:
| IPA | SAMPA | Word | Transcription |
|---|---|---|---|
| ə | @ | another | @"nVD@ |
The free vowels comprise monophthongs and diphthongs, although no hard and fast line can be drawn between these categories. They can be placed in three groups according to their final quality: i: eI aI OI, u: @U aU, 3: A: O: I@ e@ U@. They are exemplified as follows:
| IPA | SAMPA | Word | Transcription |
|---|---|---|---|
| iː | i: | ease | i:z |
| eɪ | eI | raise | reIz |
| aɪ | aI | rise | raIz |
| ɔɪ | OI | noise | nOIz |
| uː | u: | lose | lu:z |
| əʊ | @U | nose | n@Uz |
| aʊ | aU | rouse | raUz |
| ɜː | 3: | furs | f3:z |
| ɑː | A: | stars | stA:z |
| ɔː | O: | cause | kO:z |
| ɪə | I@ | fears | fI@z |
| eə | e@ | stairs | ste@z |
| ʊə | U@ | cures | kjU@z |
The vowels /i:/ and /u:/ in unstressed syllables vary in their pronunciation between a close [i]/[u] and a more open [I]/[U]. Therefore, it is suggested that /i/ and /u/ be used as indeterminacy symbols:
| IPA | SAMPA | Word | Transcription |
|---|---|---|---|
| i | i | happy | h{pi |
| u | u | into | Intu |
BKB Sentences List 1
(Taken from Bench J, Kowal A, Bamford J., The BKB (Bamford-Kowal-Bench) sentence lists for partially-hearing children, Br J Audiol. 1979 Aug;13(3):108-12)
| bkb01 | The clown had a funny face. |
| bkb02 | The car engine’s running. |
| bkb03 | She cut with her knife. |
| bkb04 | Children like strawberries. |
| bkb05 | The house had nine rooms. |
| bkb06 | They’re buying some bread. |
| bkb07 | The green tomatoes are small. |
| bkb08 | They’re looking at the clock. |
| bkb09 | He played with his train. |
| bkb10 | The postman shut the gate. |
| bkb11 | The bag bumps on the ground. |
| bkb12 | The boy did a handstand. |
| bkb13 | A cat sits on the bed. |
| bkb14 | The lorry carried fruit. |
| bkb15 | The rain came down. |
| bkb16 | The ice cream was pink. |
Laboratory Exercises
To run these exercises, you need to run CYGWIN from the desktop, and copy the scripts folder from the shared folder to your home directory. Then source the env.sh script to set up the working environment:
cp –r y:/EP/scripts ~ cd ~/scripts source env.sh
For each exercise you are encouraged to examine the scripts and explore the programs we use to learn more about laboratory practices.
- Recording a small corpus
- You will be shown how to record the 16 BKB sentences in one of the research booths. You will end up with a files called y:/EP/name.wav and y:/EP/name.txt, where name will be your given name.
- Use the ProChop program to divide your recording into utterances (ProChop is part of ProRec - Prompt & Record):
prochop -a y:/EP/name.wav -t y:/EP/name.txt -o y:/EP/name -f SFS -sw
You will end up with 16 SFS files in the folder y:/EP/name. - Use the bkbalign.sh script to align a phonetic transcription on all sentences (e.g.):
bkbalign.sh y:/EP/name
The SFS files in y:/EP/name now additionally contain an aligned phonetic transcription. - Look at alignments and identify regions where the alignment is incorrect. You can display one of the files with (e.g.):
Eswin -isp -ian y:/EP/name/bkb01.sfs
Attempt to correct the alignment for a few sentences - use command Annotation|Create/Edit annotations. The command Help|Keyboard Help gives some shortcuts. - How well does automatic alignment work? What are the causes of problems? What are some advantages of automatic alignment?
- Compare annotations of an utterance.
- Take a copy of the mystery file and start up the annotation editor:
cp y:/EP/mystery.sfs . Eswin -isp -ian -l "name" mystery.sfs
- Annotate the first few words of the sentence in "mystery.sfs" using the SAMPA broad phonetic transcription scheme. You will need to decide criteria for which labels to use and where to place the boundaries between segments. Make a note of the difficult decisions and your criteria.
- Save the annotated SFS file back to the shared folder under a new name, e.g. y:/EP/mystery-name.sfs.
- The annotations used by the different groups will then be combined and printed out.
- How much inter-group agreement was there? What were the major areas of disagreement?
- Intonational transcription
- You will be given an extract from the MARSEC corpus of prosodically-transcribed speech in y:/EP/whale.sfs. Display this with:
- Listen to the extract and write down an orthographic transcription indicating:
- Prosodic phrasing (major or minor tone-group boundaries)
- Accented syllables (stressed syllables close to pitch movements)
- Pitch accent type (low-fall, low-rise, high-fall, etc)
- Compare and contrast with the 'official' transcription once you have run out of time!
Eswin y:/EP/whale.sfs
A table of suitable symbols was given earlier.
The piece starts:
on aˇrrival at • Windsor | ˉNemo was ˋwinched |
Reflections
- What are the advantages and disadvantages of using speech audio for experimental phonetics research compared to instrumented articulation?
- What can you do to reduce distortion on your recordings? What can you do to improve the signal-to-noise ratio on your recordings?
- Why is transcription useful even if it cannot be accurately aligned to the signal?
- What are the "segmental assumptions" of annotation? Think of examples where these assumptions might not be met.
- Why is intonational transcription particularly troublesome?
Word count: . Last modified: 14:35 09-Jan-2018.