7. Sequences
Key Concepts
- Contextual effects of various kinds occur when segments are articulated in sequences.
- Speakers can simplify articulation to reduce speaking effort so long as intelligibility is maintained.
- Dynamical considerations require that articulation needs careful planning.
- A Gestural Score is a way of graphing articulation to explain causes of contextual change.
- Coarticulation, Assimilation, Elision are types of contextual effect that may be explained in articulatory terms.
- Contextual effects may be the historical cause of certain phonological phenomena such as Sandhi, Liaison and Harmony.
Learning Objectives
At the end of this topic the student should be able to:
- describe some of the changes that arise when phonetic segments are executed in sequence
- describe how some contextual changes occur because of limitations of articulator dynamics
- use gestural scores to explain how some contextual effects arise in the planning and execution of efficient articulation
- give some reasons why contextual effects may be different in different languages
- give examples of contextual effects of different types: coarticulation, assimilation, elision and harmony.
Topics
- Contextual Effects
When sequences of phonetic segments are spoken we do not expect that each one would be articulated in the same way as when articulated in isolation. Of necessity the articulators move smoothly and continuously when moving from one segment to the next, and this requires that their position at some time t is influenced both by their position and movement at times earlier than t and in anticipation of their position and movement at times later than t. We shall call all variations in the articulation of a segment caused by its location within an utterance contextual effects.
Contextual variations in the articulation of a segment are influenced by many factors, including:
- identity of nearby segments
- position in syllable
- syllable stress, word focus and sentence intonation
- rhythm and speaking rate
- speaking style
In this lecture we will mainly focus on contextual effects arising from the identity of nearby segments. We approach this through the "speaking to be understood" model introduced in week 3. In this model, we assume that the speaker has acquired knowledge of what the utterance needs to sound like to be understandable to a listener, then creates some articulation which is sufficient to trigger that understanding. In such a model it is not necessary for the speaker to make each phonological aspect of a word individually discernible so long as the word itself may be identified in context. This allows for the possibility that the realised form may underspecify (i.e. be ambiguous about) its phonological structure.
Thus under the speaking to be understood approach, we have an underlying phonological representation of some utterance and an articulatory plan which the speaker believes will generate a sound which is "good enough" for the listener. Contextual effects arise because there are advantages to the speaker in having a simpler plan which uses less articulator movement: these can be produced faster and with less effort. But the need for the message to be understandable limits which simplifications may be made.
Lastly, we would expect (and indeed we find) that the allowable degree of simplification will depend on many factors of the communicative act: the novelty of the message, the likelihood and danger of misunderstanding, the familiarity of the listener to the speaker or the quality of the listening environment. We shall address these issues in a later lecture.
- Some Elementary Dynamics
Before we look at the movements of articulators, let's consider some simple aspects of the dynamics of moving objects.
An example of a simple dynamical system is a mass connected to a spring responding to an applied force. When a force is applied, the mass accelerates in the direction of the force and travels until the applied force is equal to the restoring force of the spring. Consider a step change in an applied force:
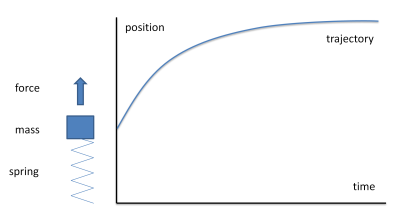
The object moves from its current position to a new position under the action of the force. The path that it takes depends on the degree of damping in the system (what frictional forces apply). If damping is too low then the mass overshoots the new rest position; if it is too high, then the mass takes a long time to get to the new position. If the damping is just sufficient to get to the new position without overshoot, we say the system is critically damped.
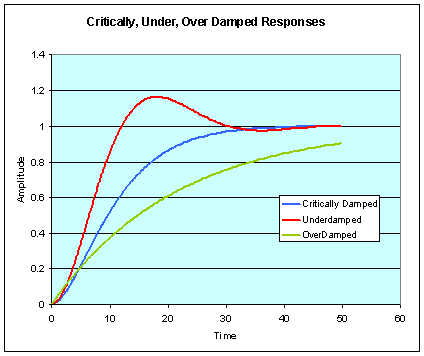
Critically damped movement is the fastest way to get to the target without overshoot. A reasonable assumption (and one accepted by various articulatory theories) is that articulator movement is critically damped.
However, if movement of the object is critically damped and if there is not enough time for it to travel to its target location under the applied force, then undershoot can arise, as seen in this diagram:
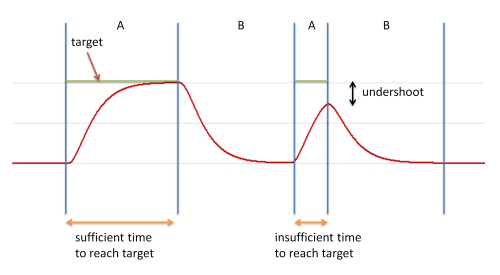
Here we see a sequence of targets A, B, A, B. For the first A target, the object has sufficient time to reach the target value before it heads off for the following B target. For the second A target, however, insufficient time is available, and the object heads on to the second B target before it reaches the A target position. This behaviour is called undershoot.
What happens when we want to move multiple articulators into a given target configuration? Generally, different articulators will move at different speeds. This means that if we require the articulators to get into a specific configuration at a specific time, then they need to be set off in movement at different times:
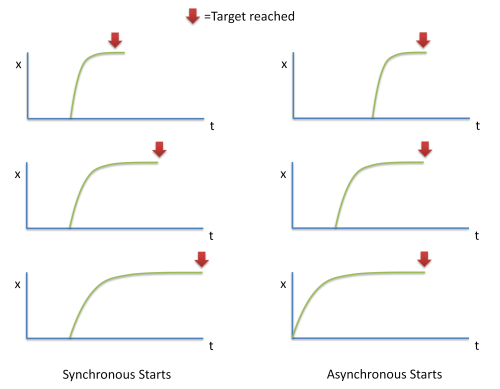
In the left panel of the diagram above, we see that if articulator movement is triggered at one time, then the target configuration is only achieved when the slowest articulator is in position. This may be a problem if the intermediate articulatory configurations produce the wrong sound. In the right panel, we see that if the slowest articulator is set off first, it can be arranged that all articulators get into position at the same time.
From this discussion we need to draw the conclusion that speaking sequences of speech sounds - involving multiple articulators each with different dynamical properties - is going to take a lot of planning. We cannot just throw the articulators around and hope that they will be in the right position at the right time to make the right sound. We need to allow sufficient time for each articulator to reach the location needed for the given sound and we need to plan asynchronous starts to ensure that the slower articulators are in position for when they are needed to synchronise with the faster articulators.
- Articulatory Planning and Execution
Elements of Motor Planning
How is the articulation of an utterance planned and executed? There are multiple theories, but each involve elements such as:
- Motor primitives: these are assumed to be pre-stored, pre-planned, learned movements of muscles that control the movement of one articulator (or one part of one articulator). A motor primitive might be a lower-lip raising movement, or a velum lowering movement.
- Motor programs: these are combinations of motor primitives required to execute all the articulators for some stretch of speech: a single phone, a syllable onset or rhyme, or even a whole syllable or word. These are supposed to be well practised and rehearsed, but can be adapted according to need.
- Motor plans: these are combinations of motor programs which are built as required to articulate a complete, new utterance.
Generally the assumption is that speaking is a highly-rehearsed and learned behaviour, and that articulation is not wholly planned from scratch for each utterance, but is composed from more primitive elements (motor primitives & motor programs), which might be finite in number. Such ideas not only reduce the complexity of speaking, but explain some aspects of speech acquisition by children and the occurrence of idiosyncratic speaking habits in individuals.
A Gestural Score
How are the primitive elements assembled into a motor plan for an utterance? One model for this is called the gestural score. Analogous to a musical score, it sets out which primitive gestures need to be articulated at which times to execute the production of an utterance [image source]:
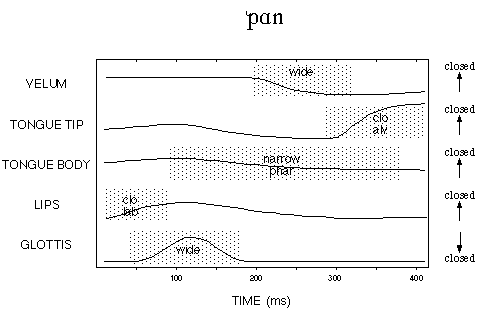
Different combinations of the different primitives give rise to different utterances [image source]:
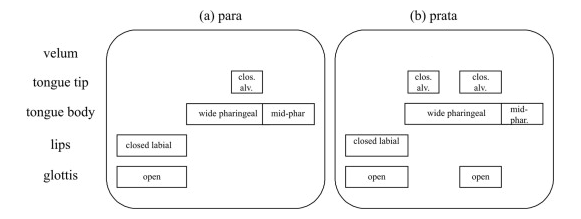
And the same combination of primitives but with different timing can also give rise to different utterances [image source]:
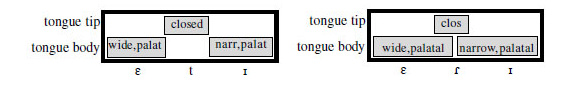
Articulatory undershoot
Articulatory undershoot will have an effect on sound generation. If the tongue fails to reach the articulatory position for a peripheral vowel, then it may appear to sound centralised. If the articulators fail to close for a plosive or create a narrow-enough channel for a fricative then the whole sound may be weakened, this is called lenition. A plosive might turn into a fricative (e.g. "recognition" as [rexəˈnɪʃən], or a fricative into an approximant (e.g. "saving" as [seɪʋɪŋ]).
Anticipatory movements of the articulators
At a minimum the gestural score needs to take into account the different speeds of the articulators, so that slower more massive articulators are started to move into position ahead of when they are needed. In fact we can easily show that forces are often applied ahead of the latest time they are required to position the articulator. Consider lip rounding in the word "sue" compared to the word "see". Since /u/ requires lip-rounding, this must be applied in time to be ready for when the vowel starts. But a moment's reflection shows that the lips are already rounded at the start of the word! In other words the lip rounding articulation of the vowel is anticipated within the whole motor plan even before the onset of the utterance.
Jaw position, lip position and velum position are prone to this type of extended anticipation - perhaps because they can be moved relatively independently of other articulators. We may not be able to move the tongue earlier than necessary because its anticipatory movement might interfere with the currently executing segments.
There is one other important aspect of anticipatory planning worth recording. Whether anticipatory positioning of an articulator is possible will depend on how much it disrupts the segments leading up to the target segment - and that will depend on the phonological contrasts in the language. Consider a language, like English, which makes no contrast between nasal and non-nasal vowels preceding a nasal consonant: here there is no problem in lowering the velum during the vowel because no distinctiveness is lost. But this would not be the case for a language in which oral and nasal vowels were contrasted (e.g. French). In a situation where an oral and nasal vowel are contrasted before a nasal consonant (e.g. French "bon" [bɔ̃], "bonne" [bɔnə]), the velum must remain closed for the oral vowel until the very last second when it can be lowered for the following nasal.
Adaptability of plans
Another question about motor planning is whether it is complete and unchangeable prior to the execution of the articulation, or whether the plan changes during execution depending on circumstances. Experiments have shown that the motor plans are surprisingly adaptable, and can change even while they are being executed. If, for example, a speaker's lower lip is pulled down while they are attempting to make a bilabial closure, it can be observed that the upper lip makes a larger than normal compensatory movement. This type of behaviour is taken to infer that the quality of articulation is continually monitored during execution, possibly through proprioceptive feedback.
Limits to contextual effects
The design and execution of the motor plan must take into account two aspects: first that the speech should be easy and fast to articulate and second that it should maintain its intelligibility to listeners. If we didn't care about intelligibility, then it wouldn't matter how accurately each segment was articulated and we would see many large contextual effects. Conversely, if we only cared about maximising intelligibility then we would speak very slowly indeed and minimise the contextual effects. Generally we want to speak quickly (since the rate limiting factor is often the articulation rather than the planning or the understanding), but at the same time we want the message to be understood. In good listening conditions, when intelligibility is high a fast speaking rate is a priority, while in poor listening conditions when intelligibility is lower a slower speaking rate is required.
- Types of contextual effects
In the literature you will find a range of names for different types of contextual effects. Let us take them in turn, with examples.
- Coarticulation: Coarticulation means 'joint articulation', that is a situation where one articulator is trying to satisfy more than one segment. A classic example is in the articulation of "car" and "key"; in the first, anticipation of the vowel moves the body of the tongue low and back and so the velar closure occurs further back in the mouth [k̠ɑ]; while in the second, anticipation of the vowel moves the body of the tongue high and front and so the velar closure occurs further forward in the mouth [k̟i]. The contextual variation of the two [k] sounds is caused by the joint articulation of the plosive and the vowel. Another example of coarticulation is audible in the quality of /h/ before different vowels. When articulating [h], the tongue anticipates the position for the following vowel and so the vocal tract tube that filters the turbulence generated by the glottal fricative has the frequency response of the following vowel. Indeed we could say that varieties of /h/ are as different to one another as varieties of vowels.
- Assimilation: Sometimes the gestural score is so modified by efficient planning that the resulting score is confused even in terms of what phonological segment sequence it represents. In "good boy" or "good girl", for example, it appears that the alveolar plosive can be substituted for a bilabial or velar plosive respectively: [gʊbbɔɪ], [ɡʊɡɡɜːl]. However, an alternative explanation is shown in the gestural scores below:
- Without assimilation:
tongue body ʊ vowel ɔ vowel ɪ vowel tongue tip alveolar closure lips lip closure - Anticipate lip closure:
tongue body ʊ vowel ɔ vowel ɪ vowel tongue tip alveolar closure lips lip closure - Drop alveolar closure:
tongue body ʊ vowel ɔ vowel ɪ vowel tongue tip lips lip closure - Elision: In the assimilation example above, we see how elements of the score which become redundant because of efficient planning (like the [d] in "good boy") can seem to be dropped. There are other situations in which elements can be dropped, perhaps simply because there is not enough time to articulate them, or because meaning is preserved without them. This dropping of whole phonological segments is called elision.
- Harmony, liaison and other phonological-level effects: Harmony is a phenomenon of many languages of the world, and refers to constraints on which phonological segments can co-occur within a word or morpheme. In Igbo, a Nigerian language, the vowels in a word must all come from one of two sets, either [i,e,u,o] or [i̙,a,u̙,o̙] (the diacritic is retracted tongue root). For example /isiri/ "you cooked", /osie/ "he cooks", /i̙si̙ri̙/ "you said", /o̙si̙a/ "he says".In other words, the tongue root position is spread throughout the word.
These two types of coarticulation work right-to-left, with later sounds influencing earlier sounds. The term for this is anticipatory coarticulation. Left-to-right coarticulation can also occur, although it is less common. This is called carryover or perseverative coarticulation. An example of perseverative coarticulation is the carrying over of voicelessness from the consonant to the lateral in "please" [pl̥iːz].
In this explanation, there is no "shift" from /d/ to /b/, just a plan in which /b/ takes over the role of /d/ and the /d/ is lost. It is hard to call this 'coarticulation', since there is no real problem in producing an alveolar plosive in this context, and in any case the articulators for [b], [d] are different - so it cannot be the case that the change in articulation is due to the tongue tip being jointly articulated for both [d] and [b].
This combination of coarticulation and phonological re-writing is called assimilation.
Another common form of assimilation is devoicing, particularly of voiced plosives and voiced fricatives before voiceless sounds. Since all English voiced plosives and fricatives have voiceless counterparts, a loss of voicing can always be interpreted as a change in the identity of the segment itself (i.e. assimilation could arise from voicing coarticulation). It is common to hear "have to" spoken as [hæftʊ] for example.
It is interesting to note that there is nothing to stop voiceless segments being assimilated to voiced ones in the complementary context, e.g. "nice boy" as [naɪzbɔɪ]. However this kind of voicing assimilation doesn't seem to occur in English, although it does occur in Frenchː "avec vous" as [aveɡvu].
These examples of assimilation are right-to-left or anticipatory, but assimilation can occur left-to-right, as in "happen" [hæpm̩] or in "don't you" [dəʊntʃuː].
Assimilation is important diachronically, since if a motor plan is ambiguous about which phonological sequence it represents then new generations of listeners can misinterpret the phonological form of the word. Historically this may have arisen in the voicing agreement of the plural morpheme "-s" to the voicing of the last consonant in the word; or the pronunciation of "in+possible" as /ɪmpɒsɪbl̩/. A newspaper was once just paper /peɪpə/ containing news /njuːz/, but now for many people it is a /njuːspeɪpə/.
Consider the phrase "next week", it is indeed possible to articulate this as [nekstwiːk] but it is also very often heard as just [nekswiːk]. The [t] is tricky to articulate between consonants, and it is unlikely that the listener will interpret the result as "necks week".
In a famous experiment, Browman & Goldstein used articulator tracking to study tongue tip movement in the phrase "perfect memory", which contains a tricky articulatory sequence [ktm]. When spoken quickly, the bilabial closure precedes the velar release and the [t] is elided to get [pɜːfek̚ memriː]. The scores below show the process:
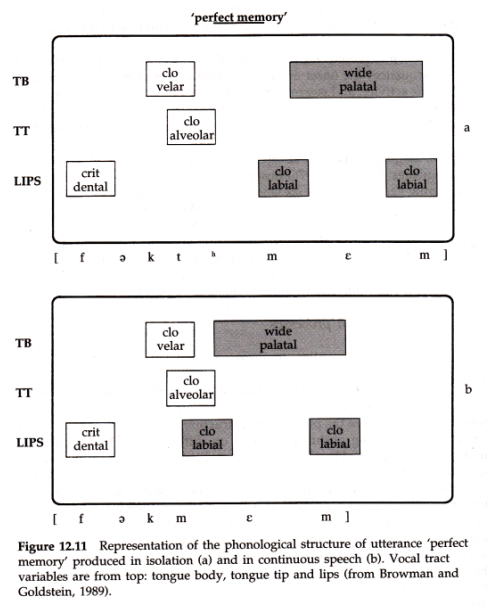
But articulator tracking gave an interesting result around the elided /t/ segment - the tonɡue tip still made some brief movement, even though there were no acoustic consequences because of the lip closure.
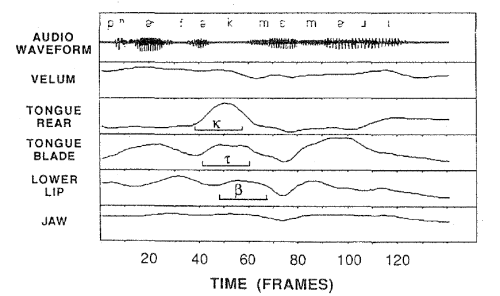
The fact that elements of the motor plan are still executed even when they are redundant is evidence that planning is an active process performed "on the fly" while speaking.
One important aspect of elision that is worth noting, is that elision does not disturb the speech rhythm. That is, deleting segments does not speed up the speaking rate (causality is the other way around: increasing rate causes elements to be dropped). The consequence of this is that listeners can sometimes tell from the timing of the utterance that elements have been elided. Consider the phrase "book-case" as [bʊkkeɪs]; after elision of the first [k] segment, we get [bʊkːeɪs] and not [bʊkeɪs]. This is an example of gemination.
Although harmony is often taken to be a phonological phenomenon operating at the level of segment selection rather than motor planning, it could have its origins in coarticulatory behaviour. Long-range coarticulatory phenomena do occur which stretch over multiple syllables - we see examples of that in English with multi-syllable stretches of nasality and nasalisation, in words like "murmuring". Coarticulatory anticipation of lip rounding can also occur many segments ahead of a rounded vowel. Also the first words of infants tend to exploit reduplication of syllables, which is also a kind of harmony, in "mama", "dada", "wowo", etc.
Thus what we see synchronically as vowel harmony, may have arisen diachronically as a phonologisation of long-range vowel-to-vowel coarticulatory patterns.
A similar story might be told about Liaison: the intrusion of a sound between words to reinforce a word boundary. An example of this in English is "linking-r", where an /r/ sound is introduced between a word ending in a non-high vowel when followed by a word beginning with a vowel, such as [bʊtʃə(r)ənbeɪker] or [ɪndɪə(r)ənpɑːkɪstɑːn]. Such effects might have arisen from situations where a word-final /r/ is lost due to contextual effects, except for these situations where it is still helpful for the listener. This might then appear (diachronically) as a regularity in the phonological pattern which is then applied by new speakers in new contexts.
Finally, some contextual effects are so old and accepted that they enter the spelling system, such as "in+possible" => "impossible". It then becomes questionable as to whether modern speakers even think of such words as arising from derivational morphology plus contextual effect.
Readings
Essential
- Coarticulation and connected speech processes, a web tutorial by Peter Roach.
- An introduction to coarticulation, some web pages by Sidney Wood.
Background
- Gick, Wilson & Derrick, Articulatory Phonetics, Wiley Blackwell 2013, Chapter 11, Putting articulations together. [available in library].
- Farnetani & Recasens, “Coarticulation and connected speech processes”, in Handbook of Phonetic Sciences (ed W.Hardcastle, J. Laver & F. Gibbon), Wiley-Blackwell 2010 [available in library].
Laboratory Activities
In this week's lab session we will experiment with creating new utterances by gluing together the sound elements from old utterances.
Activities:
- concatenation of individual segments
- concatenation of syllable components
- concatenation of words
- concatenation using a 'slot and filler' grammar.
Research paper of the week
Articulatory Inversion
- A. Toutios, K. Margaritis, "A Rough Guide to the Acoustic-to-Articulatory Inversion of Speech", 6th Hellenic European Conference on Computer Mathematics & its Applications (HERCMA), Athens, Greece, September 2003.
Articulatory inversion is the challenge of deriving an appropriate articulatory motor program to reproduce an utterance that you have heard. Toutis and Margaritis describe the problem:
if the acoustic signal is known (something which is the usual case) can the articulatory state be somehow calculated or even approximated?
The recovery of the articulatory state given the acoustic signal is not a trivial problem. Not having a direct analytical solution, it is considered a difficult and ill-posed problem, puzzling researchers for over three decades now, and being given the status of becoming a whole research area, called acoustic-to-articulatory inversion of speech or, more simply, speech inversion. Of course there are reasons for this difficulty.
One of the first things one has to consider is the way the articulatory state will be described, or modeled ... Another factor that contributes to making the speech inversion problem hard to solve, is the one-to-many nature of the acoustic-to-articulatory mapping. A given articulatory state has always only one acoustic realization. But, from the other side, a given acoustic signal may be the outcome of more than one articulatory states. Furthermore, the mapping is highly non-linear. A slight variation of the articulatory state may give rise to a whole different acoustic signal.
In the paper, the authors review a number of approaches to the articulatory inversion problem. First they review a number of models of the articulatory system such as models of articulator position and vocal tract tube cross-section, models based on phonetic or phonological features, or 3D models based on X-Ray, MRI or Electromagnetic Articulography (EMA) data.
Next the authors review some previous inversion methods, including:
- Codebooks - where many matched articulatory-acoustic pairs are pre-calculated and stored in a codebook. Then the collection is searched to find a sequence of codebook entries that would generate the given sound. A big problem with this approach is how to maintain articulatory continuity. The codebook also has to be very large with more entries in the articulatory space where small changes to the articulation lead to big changes in the sound.
- Neural networks - where the articulatory model is caused to babble sounds, and the neural network learns the relationships between positions/velocities of the articulators and the spectral character and dynamics of the sounds generated.
- Optimisation - where an iterative approach is taken: make a first guess on the articulation, see what sound it produces, then adjust the articulation in the direction of making a sound closer to the target. Repeat until no further improvements can be made.
- Statistical modelling - where explicit constraints on the position and dynamics of the articulators are built in to a generative model of the synthetic sounds, and the inversion problem is posed as a search for the best set of positions and velocities which fits both the required sound and the limitations of articulatory movement.
Articulatory inversion remains an active area of research. It has connections to research seeking to improve speech recognition and speech synthesis. It also has relevance to models of speech acquisition by infants, and in the future, to speech acquisition by robots.
Application of the Week
This week's application of phonetics is an approach to speech synthesis based on the concatenation of extracts from a corpus of recorded sentences.
The basic idea behind concatenative speech synthesis is that new utterances can be generated from pieces of old utterances provided that the pieces are carefully chosen so that they (i) closely match the form required for the target utterance, and (ii) fit together well.
The first stage is to record a 'voice talent' in the studio reading a lot of simple sentences. 1000 sentences would be a minumum, sometime many hours of recording are used.
Next the sentences are annotated: that is a linguistic description is generated for each recorded utterance, and that description is aligned to the signal for that utterance. The linguistic description not only identifies the phone sequence, but also identifies the syllables, stress level, words, word classes and sentence position. Thus each section of signal is seen to be associated with a hierarchy of labelling. This process could be very labour-intensive, but computer tools are available to largely automate the annotation process.
An index is then built which allows for all signal sections that match a given linguistic description to be found rapidly in the database of recordings.
For the actual synthesis, the text of the required utterance is analysed so that a linguistic description is generated that matches the form of descriptions used in the database. The description is then used to find matching signal sections in the database. Is the whole utterance in the database? Are some of the words? Where can the required syllables be found? In each case there may be zero, one or more matches to each part of the target linguistic description. These matching signal sections are then retrieved from the database and analysed to determine which ones fit together best.
The algorithm for selecting the best sequence of signal sections is called unit selection. The algorithm belongs to an interesting set of graph-search algorithms called dynamic programming. These algorithms are very efficient at finding the single best path through a network of graph nodes, where costs are associated with traversing arcs between nodes.
For unit-selection synthesis, the signal sections are put into a graph structure like the diagram below. Each lettered box represents a signal section retrieved from the database. The arcs represent the different ways in which the sections may be concatenated to produce an utterance matching the linguistic description.
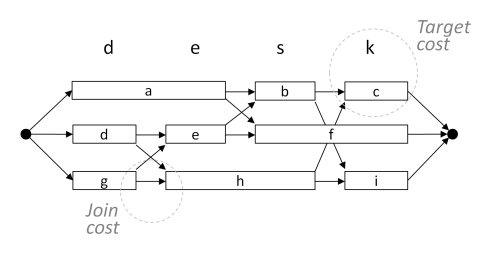
You can see that there are many different paths through the network; each would represent different readings of the sentence. But different paths will vary in two ways: (i) in terms of how well each section matches the required linguistic description (is it the right word, is it the right syllable, is it in the right sentence position, ...). This is called the target cost. Then (ii) in terms of how well each section on a path glues to its neighbours (is there a big change in loudness, or a big change in pitch, or a big change in timbre?). This is called the join cost. The best path is then the path which minimises the combination of the target cost and the join cost. This is found by (effectively) exploring all paths and determining the single best path using dynamic programming.
Finally, the signal sections on the best path are concatenated, some additional smoothing is applied, and the resulting signal replayed.
A number of text-to-speech systems are available for demonstration on-line, such as the Acapela TTS demonstration. You can purchase a wide range of synthetic voices for your Windows computer at modest cost.
If you'd like to read more about unit selection synthesis there is a good overview paper by Paul Taylor.
Language of the Week
This week's language is French as spoken by a young Parisian woman. [ Source material ].

- Identify sounds present in the French passage that are not normally found in SSBE.
- What do the diacritics used in the passage [ x̃ ẍ x̥ x̞ x̝ x̹ xʲ ] mean?
- Below are some examples of "liaison" in French. How does liaison relate to the contextual effects discussed this week?
| un homme | [ɛ̃nɔm] | les amis | [lezami] |
| vous avez | [vuzave] | ont-ils | [ɔ̃ntil] |
| tout entier | [tutɑ̃tje] | chez elle | [ʃezɛl] |
Reflections
You can improve your learning by reflecting on your understanding. Come to the tutorial prepared to discuss the items below.
- What type of contextual effects are exemplified by these phenomena:
- Rounding of /s/ before rounded vowel
- Clear vs. dark /l/
- Undershoot of vowel formant frequency in /ɡɒɡ/ vs /bɒb/
- "this shop" as [ðɪʃʃɒp]
- "don't you" as [dəʊntʃuː]
- Linking /r/ in "butcher and baker"
- The opposite of "elision" is "epenthesis" - the insertion of segments. Provide a dynamical articulatory explanation for the insertion of [t] in "prince"
- What things might affect the amount by which a speaker can simplify an articulatory plan?
- Do you think contextual effects make speech harder to understand? What would speech be like if there were no contextual effects?
Word count: . Last modified: 08:50 26-Nov-2017.