6. Obstruents
Key Concepts
- The source of energy for fricatives is turbulence generated at or near the constriction.
- Fricative spectra are strongly affected by size and shape of cavity forward of the constriction.
- Plosives have a series of events: closing, hold, burst, opening and optional aspiration.
- Place cues for plosive arise from the spectrum of the burst and the F2 & F3 formant transitions.
- VOT is an important voicing cue for plosives.
- Experiments in speech perception have highlighted how strongly adapted adult listeners are to the phonological contrasts present in their L1.
- Listeners make use of all information present in the signal that varies systematically with consonant category, whether that information is in the consonant itself, in adjoining parts of the syllable, or in vision.
Learning Objectives
At the end of this topic the student should be able to:
- describe how the acoustic properties of fricatives and plosives arise in their production
- describe some quantitative measures that differentiate fricative and plosive sounds
- describe some acoustic cues used by listeners to discriminate voicing and place of articulation in obstruents
- give examples for how human recognition of consonants is highly adapted to their spectrographic form in context
Topics
- Acoustics of Fricatives
Fricative articulations can occur at many places along the vocal tract - wherever a sufficiently small constriction can be made. The IPA chart recognises these fricatives as being used to make phonological distinctions in some world language:

All phonetic fricatives involve turbulence as a source of excitation in the vocal tract. Turbulence arises when fluid is forced to flow at high speeds through a constriction or around obstacles. While at low speeds the fluid flow is smooth and predictable, at high speeds eddies and counter currents arise which create a disturbed flow of an unpredictable nature. This turbulent flow in air gives rise to random pressure variations that we hear as an aperiodic or noise waveform.
Turbulence in fricatives arises from two main causes: (i) when air flow becomes turbulent as it passes through a constriction, e.g. at the glottis or at the lips; (ii) when a constriction creates a high-velocity jet of air which hits a stationary sharp-edged obstacle, e.g. in /s/, where the alveolar constriction directs a jet at the upper teeth. Shadle's physical model of fricative production is able to recreate most aspects of fricative acoustics, see diagram below. The main elements of fricative acoustics demonstrated in the model are the posterior and anterior cavities, the constriction and an obstacle.
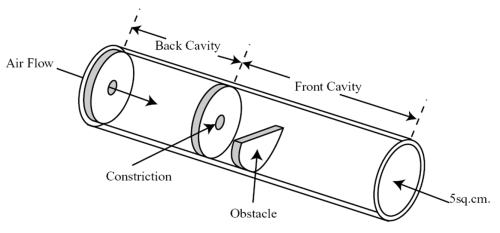
Little is known in detail about the form of the spectrum of turbulent excitation in the vocal tract. We assume it is relatively flat in the speech frequencies from 1k to 10kHz. The noise excitation is generated close to the point of constriction and relatively little sound energy passes back through the constriction from the posterior cavity to the anterior cavity. This means that most of the spectral shaping of the excitation is caused by the response of the cavity anterior to the constriction. The presence of the obstacle has two consequences: as an additional edge on which turbulence is generated, and as a means for damping some resonant vibrations within the anterior cavity - affecting the cavity's frequency response.
Acoustic Cues to Fricative Place
The frequency response of the anterior cavity changes as a function of its size. As the fricative place of articulation moves towards the front of the mouth, the anterior cavity gets smaller and its frequency response peaks at a higher frequency with a broader response peak. You can see this in the table and the spectrograms below.
Fricative h x ʃ s θ f Constriction glottis velum palato-alveolar alveolar dental labiodental Type slit slit grooved grooved slit slit Obstacle lower teeth upper teeth Front cavity response vowel response 1-3kHz 2-4kHz 4-6kHz broad ~8kHz little Since the timbre of fricatives is caused by the overall spectral shape of the sound, any quantitative description must characterise the whole spectrum in some way. Since we have seen that the main spectral peak and the bandwidth of the peak seem to vary across fricatives, some authorities have suggested we record the "centre" and the "spread" of spectral energies. However there is no consensus on the best way to measure fricatives that parallels the agreement to use formant frequencies for sonorants.
Beth am y fricative ochrol - discussion of the voiceless alveolar lateral fricative (as in Welsh).
Acoustic Cues to Fricative Voicing
In voiced fricatives like [z], vocal fold vibration occurs in the larynx while simultaneous turbulence is generated close to the constriction. Sound from the periodic source must pass through the constriction (or through the flesh of the neck) and is quiet and predominantly low-frequency. Sound from the aperiodic source is modulated by the changing air-flow pattern caused by the periodic interruptions in flow caused by the vibrating vocal folds. This pulsed turbulence can be clearly seen in wide-band spectrograms.
The production of voiced fricatives is quite tricky since it is hard to balance the pressures in the tract in such a way as to obtain good flow across the larynx and good flow through the fricative constriction. If the pressure above the larynx is too high, then vocal fold vibration ceases and the consonant becomes devoiced; if the pressure is too low, then the turbulence ceases and the consonant becomes a voiced approximant.
- Acoustics of Plosives
The IPA chart recognises plosive articulations at these places:

Phases of plosive production
Plosives are articulations in which the air flow from the lungs is temporarily obstructed at some place, then rapidly removed. The creation of the obstruction creates a quiet interval in the speech signal, while the sudden release of air at higher than atmospheric pressure creates short-lived turbulence, or 'burst'. Here is a stylised spectrogram of a voiced plosive between two vowels:
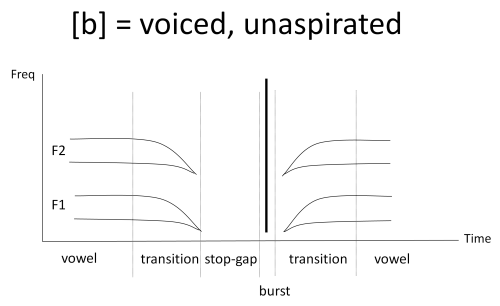
As well as turbulence at the place of obstruction, voiceless plosives can also have turbulence added from a narrowing of the glottis. This is called aspiration. Aspiration is like a short [h] sound after the plosive release that only occurs when air flow has built up sufficiently after release for turbulence to occur at the glottis. The spectrum of aspiration is much like the spectra of [h], and is variable depending on the following vowel articulation. Here is a stylised spectrogram of a voiceless plosive between two vowels:
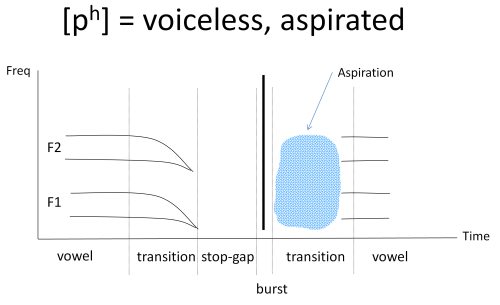
Note how the presence of aspiration hides to some extent the outgoing transition region.
Acoustic Cues to Plosive Place
Listeners can identify the place of the plosive from the acoustic character of the plosive bursts together with the effect of the closing and opening gestures on the edges of the preceding and following vowel.
The spectra of bursts are similar to the spectra of fricatives made at the same place: this is because the anterior cavity is similar for both. This means that the place of articulation can be recovered in a similar manner as for fricatives.
Although the gestures that make plosives are quite rapid, we can see evidence of the closing movement in the vowel formant pattern going into an obstruction, and evidence of the opening movement coming out. If we study the formant frequency movements that occur as an obstruction is made we see a lowering of F1 for all places of articulation, and changes in F2 and F3 which vary according to the place of articulation. These formant transitions are perceptually important clues (or cues) to the manner (F1) and the place (F2 & F3) of the consonant. The "locus frequency" of a formant is the direction to which the transition points as the obstruction is first made then released.
This table summarises the acoustic cues to place:
Place Burst Centre Frequency F2 Locus Frequency F3 Locus Frequency Bilabial Lower than vowel F2 Low Low Alveolar Higher than vowel F2 Mid High Velar Close to vowel F2 High Mid To make quantitative measurements to characterise the acoustic form of plosives, we need to make measurements of each phase (closing transition, stop gap, burst, opening transition). Typically this is done by characterising the average spectrum over each phase. It has proved hard to measure the shape of formant transitions in a reliable manner, although we know they are important to human listeners.
Acoustic Cues to Plosive Voicing
Unlike fricatives, voicing in plosives is not about the presence/absence of vocal fold vibration, but about the relative timing of the oral release and the onset of phonation. In a fully voiced plosive [b̬], vocal fold vibration is initiated by increased sub-glottal pressure before the oral release; in a normal voiced plosive [b], the vocal folds are adducted at the time of release and voicing starts as soon as air-flow builds up sufficiently; in an unvoiced unaspirated plosive [p], the vocal folds are apart at the time of release, but come together about 30ms later with a separate laryngeal approximation gesture; in an unvoiced aspirated plosive [pʰ], the vocal folds are partially abducted at the time of oral release, and the air-flow through the glottis gives rise to turbulence, voicing starts with a subsequent laryngeal approximation gesture about 50ms later.
The timing interval between oral release and the onset of vocal fold vibration is called the voice onset time (VOT). As well as VOT other voicing cues for plosives include the presence of aspiration, the presence of an audible F1 transition (i.e. one not hidden by aspiration) , the intensity of the burst and the duration of the preceding vowel. There are notable differences in cues to voicing across languages: some do not use aspiration, others have a three-way contrast.
Voice onset time has proved a popular quantitative measure of plosive articulation because it is very easy to measure from the signal. You will find it used in many studies of speech production and perception. However it is only one of the cues to plosive voicing.
- Flaps, taps and trills (Revision)
Flaps, taps and trills are rapid, ballistic movements of articulators. Flaps are rapid approximations between an active and a passive articulator without contact between them. Taps are rapid approximations with contact. Trills are repeated flaps or taps, caused by an aerodynamic process rather than controlled muscular movement of the articulator. The IPA chart recognises the following flaps, taps and trills:

The uvular trill is made by the uvular vibrating against the back of the tongue. The oscillation mechanism is like phonation in that air flow is used to force the articulators apart, then a Bernoulli effect force brings them back together again. Trills can be voiced or voiceless, and include varying amounts of frication/turbulence.
Flaps are associated with a flexed tongue tip making an approximating gesture, while taps involve contact. These diagrams contrast an alveolar flap with a dental tap:
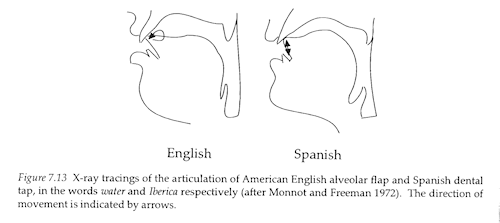
Symbol Description Listen ʙ Bilabial trill r Alveolar trill ʀ Uvular trill ⱱ Labialdental flap ɾ Alveolar tap ɽ Retroflex tap Flaps and taps cause changes in the energy level of the acoustic signal as the obstruction is made and released. They may also cause formant transitions as the articulators move and change the shape and resonant frequencies of the vocal tract pipe.
- Multiple and secondary articulations (Revision)
The classification system for the IPA assumes one active articulator acting against one passive articulator, for example the tongue tip against the alveolar ridge. However the articulatory system has many more degrees of freedom, and while one primary articulation is being made, there are still many opportunities for other simultaneous articulations, or for secondary, modifying articulations.
Multiple articulations
- We have already met the labial-velar approximant [w] which has narrowings at both the lips and soft palate.
- Double stop articulations articulations also occur, such as
[k͡p] and[g͡b] in Yoruba.
In general these multiple articulations enhance aspects of the spectrographic pattern used to make distinctive sounds. Thus additional lip rounding in [w] lowers F2 further than would occur by velar narrowing alone.
Secondary articulations
Secondary articulations are marked in transcription using diacritical marks:
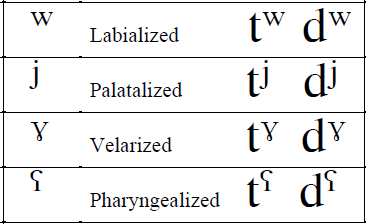
- Labialisation refers to the addition of lip rounding, for example
[sʷuː] for "sue". - Palatalisation refers to movement of the tongue body toward the hard palate. "Russian and several other Slavic languages opposes a whole series of palatized consonants to non-palatized ones. Thus, in addition to
[p, b, m, f, v, t, d, n, l, r, s, z] , Russian has[pʲ, bʲ, mʲ, fʲ, vʲ, tʲ, dʲ, nʲ, lʲ, rʲ, sʲ, zʲ] " [Catford, 1977]. - Velarisation refers to movement of the back of the tongue toward the soft palate. The auditory effect of velarisation is to give a 'darker' quality to the sound, for example in 'dark-l'
[ɫ] - this is due to a lowering of the second formant frequency. - Pharyngealisation refers to retraction of the root of the tongue toward the back wall of the pharynx. Pharyngealisation can be used to make phonological contrasts in some dialects of Arabic.
- Laryngealisation refers to a secondary laryngeal gesture simultaneous with the primary articulation. A common form of laryngealisation is the addition of creaky voice, as in the Danish stød that we met in Week 4. Some English speakers reinforce voiceless plosives with a simultaneous glottal stop, this process is also given names such as 'glottalisation' or 'glottal reinforcement'.
These additional articulatory gestures will affect the spectral qualities of the sounds to which they are applied. Labialisation, for example, will lower the second formant in amplitude and frequency, and reduce the frequency of the main spectral peak in fricatives. The effects of secondary articulations can be studied by comparing the same sound for the same speaker with and without their application. Changes in vocal tract tube shape affect the filter response and measured formant frequencies and amplitudes.
- Consonant Perception
Although we can see differences in the spectrogram between different obstruents, we can never be certain that listeners exploit these differences for recognition until we perform a perceptual experiment. It may be that the differences we observe are too small, or too fast, or too unreliable to be useful for listeners.
Perceptual experiments take many forms, but a classic approach is to synthesize artificial speech-like sounds and manipulate their acoustic content to explore how that affects the ability of human listeners to recognise lexical items. For example, we might create synthetic versions of "coat" and "goat" that differ only by voice onset time to see if listeners use that property to discriminate between the two words. The concept is to reduce each phonological contrast to a number of independent "acoustic cues", then test each in isolation. Although the independence assumption is questionable, the approach seems to generate interesting outcomes.
We give some examples of how acoustic cues work for discriminating place and voice of plosives.
- How VOT affects voicing perception. It turns out that an important consequence of a delayed voice onset is that the vowel starts with its first formant frequency already in the right place for the following vowel. That is, there is no audible F1 transition between consonant and vowel. This is because by the time voiced phonation restarts the lips & tongue have largely moved into the appropriate position for the vowel. This absence of an F1 transition in plosives with delayed voicing turns out to be a more important cue to voicelessness than the long VOT by itself (artificial stimuli with short VOT but no F1 transition are labelled voiceless by many speakers).
- How VOT varies with place. Voice onset time for voiced plosives varies systematically with place - typically it is shortest in bilabials, longest in velars and intermediate in alveolars. This is likely because of changes in the time it takes for the pressure above the larynx to fall once the oral closure is removed. For various reasons the pressure falls fastest when the lips are opened and slowest when the body of the tongue comes down from the soft palate. The faster the air pressure falls, the more rapidly the air-flow through the glottis builds up and the more quickly voicing restarts.
- How burst centre frequency affects place perception. We have said that the spectral shape of plosive bursts are distinctive of place of articulation, but perceptual experiments have shown that the story is a little more complex. Bursts that have energy concentrated at low frequency are recognised as /b/, and bursts that have energy concentrated at high frequency are recognised as /d/, but to be recognised as /g/ bursts need have energy concentrated close to the F2 frequency of the following vowel. In other words the listener interprets the spectrum of the burst with respect to the spectrum of the surrounding sounds. This means that there is no context independent cue to place based on the spectrum of the burst. Indeed one can make a burst that sounds like /p/ in one context and /k/ in another.
- How formant transitions vary shape with vowel context. A related story applies the formant transition cue to place. Perceptual experiments confirm that formant movements that occur at the edges of vowels are powerful cues to obstruent place of articulation even in the absence of a burst. But again these cues are not context independent. They arise as the articulators move from vowel to consonant to vowel, and the shape of the transitions not only depends on the identity of the consonant but also on the identity of the vowels. The F2 formant transition in /diː/ is quite different to its shape in /dɑː/ - in fact the F2 rises going into /iː/ but falls going in to /ɑː/.
Perceptual experiments have shown that our perceptual system is sensitive to these changes in VOT with place. In simple terms, the VOT value that separates voiced from voiceless plosives is a smaller value for /b/ vs /p/ than it is for /g/ vs /k/. A medium length VOT that might trigger recognition of a /p/, might be too short to trigger recognition of a /k/. For more information see the reading by Lisker in the Background Reading section.
What these effects tell us about human speech perception
In these four effects noted above, we can see a common pattern. Listeners make use of whatever information is reliably present in the signal that systematically varies with the phonological contrast. If the F1 transition varies with plosive voicing because it is affected by delayed VOT, then listeners will listen out for the F1 transition as well as for VOT. If VOT varies with place for voiced plosives then an optimal procedure for identifying the voice of plosives needs to take place into account. If the way in which burst spectra and formant transitions provide information about the identity of a plosive differs according to the vowel context then we need to recognise the consonant and the vowel at the same time.
Adult listeners have perceptual systems that are highly tuned to the phonological contrasts used to discriminate between lexical items in their language. This tuning involves seeking out all and any acoustic patterns that provide information to make a decision, whether that information is in the phonetic segment, in the rest of the syllable or even in adjoining syllables.
This specialisation to one's own language starts early. It has been seen in infants before 12 months of age, and it continues into adulthood. A downside of this specialisation is that we become less sensitive to acoustic aspects which are not used to make phonological contrasts in our own language. It is as if we have gained sensitivity to variations across phoneme classes at the price of reduced sensitivity to variation within a phoneme class.
This tuning of the perceptual system to one's first language (L1) has consequences for learning a second language (L2). If sounds in the L2 are similar enough to categories in the L1, then speakers will simply adopt the L1 category - even if it is a bit off. On the other hand if sounds in the L2 are dissimilar enough to categories in the L1, then speakers have less difficulty in acquiring them. This general observation has been studied comprehensively by Flege and colleagues, see Research Paper of the Week.
Audio-visual speech perception
So far we have discussed perception as if it were a purely acoustic phenomenon, but as we know from the Speech Chain, listeners are also able to extract information about phonological identity from visual information. It is easier to recognise a /b/ in a poor acoustic environment, for example, if you can see the speaker's lips close and open. Both the look and the sound of a consonant can affect its identification of by listeners. Listeners find the underlying phonological unit which best explains the joint visual and acoustic information. This can be demonstrated dramatically by creating artificial stimuli in which the visual and acoustic information are in conflict - listeners hear different consonants depending on whether their eyes are open or shut! This is called the McGurk effect.
We might hypothesize two psychological models for the combination of audio and visual information in consonant perception. In the first model ("late integration") we make separate judgements of the consonant in each modality and combine the decisions. In the second model ("early integration") we combine information coming from both modalities before we make a single decision. Our lab experiment this week may shed some light on which model best fits the evidence.
For more information look at the reading by Summerfield in the Background Reading section.
Readings
Essential
- Hewlett and Beck, Introduction to the Science of Phonetics, Chapter 4, Basic principles of consonant description. [available in library].
Background
- Lisker & Abramson, "The voicing dimension: some experiments in comparative phonetics", Proc. Sixth International Congress of Phonetic Science, Prague, 1967.
- Summerfield, Q. "Lipreading and Audio-visual Speech Perception". Philosophical Transactions: Biological Sciences 335.1273 (1992): 71–78.
- Laver (1994) Principles of Phonetics, Chapters 8, 9 & 11, Stops, Fricatives and Multiple articulations [available in library].
Laboratory Activities
In this week's laboratory activity, we will study two phenomena of consonant perception.
Activities are as follows:
- Perception of plosive voicing as a function of voice onset time. Here you will be asked to identify CV syllables as one of /b,p,d,t,g,k/ and we will analyse your responses as a function of the VOT used to make the sounds.
- Audio-visual perception of consonants. Here you will be asked to identify the consonant in VCV utterances based on the audio signal alone, the visual signal alone, or the combined audio-visual signal.
This laboratory session will also be the basis for the first assessed laboratory report. Further details on the Moodle site.
Research paper of the week
Second Language Perception
- Jim Flege, "The production of 'new' and 'similar' phones in a foreign language: Evidence for the effect of equivalence classification". Journal of Phonetics, 15 (1987), 47-65.
Jim Flege performed a lifetime of research work into second language learning at the University of Alabama. His research looked at the phonetic aspects of L2 acquisition focussing on individuals learning an L2 naturalistically in an immersive environment rather than in the classroom.
Some of Flege's early work, like this paper, produced results which conflicted with the current understanding of the time. For example, what do you think would be most problematic for a learner - L2 phonemes which were similar to those in the learner's L1 or phonemes which were most dissimilar? Surprisingly learners cope quite well with phonemes that are dissimilar - they just create a new category for the sound - but struggle when the new phoneme overlaps with those existing in the L1.
In this paper, English speakers were tested on their ability to produce French [u] and [y]. It turned out that [y] was different enough to any English vowel category that they produced that vowel with the same formant frequencies as French speakers. However the English speakers persevered with their English /u/ quality even if it was not the same as the French /u/ - that is they put the French [u] sound into the English /u/ category. Likewise English speakers productions of French /t/ had the long VOT of English [tʰ], not the short VOT of unaspirated [d̥] of French. Flege argues that learners make mistakes when they re-use their L1 categories inappropriately.
In a situation where the L2 has different vowel categories compared to the L1, learners may create new vowel categories or assimilate existing L1 vowel categories. Once a speaker becomes fully bilingual it can even be possible to see how the L2 has modified the L1 categories, which may move to stay distinct from the new L2 categories.
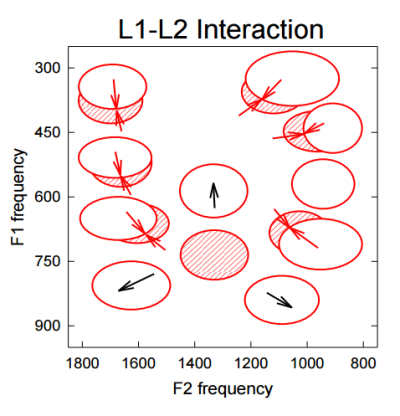
The introduction of L2 vowel categories (grey ovals) causes an adjustment in the location of the L1 categories (white ovals).
This paper was one piece of evidence that Flege incorporated into his "Speech Learning Model". Considerable further research in the area has been conducted since to determine whether it is possible to break learners out of their pronunciation habits though some innovation in perceptual learning. Much effort has been spent on finding better ways to teach /l/ and /r/ to Japanese learners of English!
Application of the Week
This week's application of phonetics is automated phonetic transcription, that is automatic recognition of the phoneme sequence from an audio recording of speech.
Phonetic recognition is a different problem to word recognition. Phonetic recognition is actually harder than word recognition because the recogniser is required to operate without knowledge of what words exist in the language or their frequency of occurrence. Phonetic recognition can only use what contextual information is present in the phoneme sequence. As a consequence, phonetic transcription accuracy is far worse than word transcription accuracy.
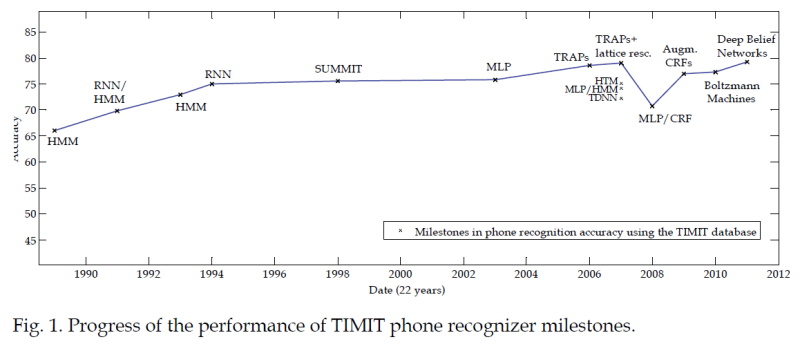
For the building and construction of phonetic recognisers, the TIMIT corpus has proved to be useful. This is because it is a large database of short sentences from many talkers that have been manually transcribed. A recent article provides a technical history of phonetic recognition of TIMIT. The article shows how recognition performance has improved over the years:
There are perhaps three main approaches to the construction of a phonetic recogniser:
- The knowledge-based approach: here the idea is to create feature detectors for acoustic elements of the signal that are known to be of use in making phonological contrasts. Each detector contains specialised knowledge for one phonetic aspect, such as the detection of voicing, or the classification of plosive bursts, or the location of syllable nucleii. The outcomes of the set of detectors are then combined to make a decision about the likely underlying phoneme. Despite much effort in constructing such systems over many years, these systems do not work as well as the aproaches below. One problem is to build detectors which work well in a wide variety of acoustic environments, phonetic contexts and across different speakers. Another is the difficulty of combining information across feature detectors when each may be in error and so might show conflicting interpretations of the signal. More information.
- The statistical approach: here the idea is to make a statistical model of the spectro-temporal pattern for each phoneme. Every phoneme is modelled in the same way, and the system starts with no knowledge of the acoustic form of any phone. Using transcribed sentences for training, the system learns the average acoustic form of each phoneme and the range of acoustic variation. Phonetic recognition is then posed as a search problem: find the sequence of phoneme models which would have been most likely to have generated the observed signal. This approach is often called the "HMM approach" after the most common form for the acoustic models. More information.
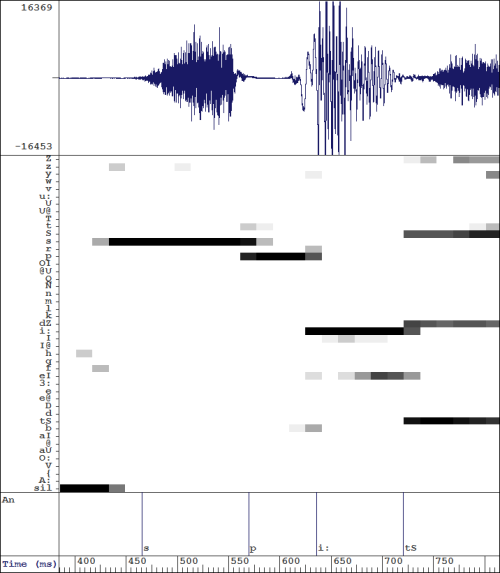
- The neural-network approach: here the idea is to create a computational machine dedicated to the task of estimating the probability that each segment of time could be a realisation of each available phoneme. The term neural-network refers to a particular class of computational system that is modelled (to some degree) on the computations performed by neurons in animal brains. The neural network is trained by presenting it with training data in which pieces of signal are paired with the correct phonetic label. The internal operation of the network of computing units is then modified to make it more likely that the phonetic label will be activated the next time it sees a similar piece of signal. Such networks often have thousands of processing elements, and their operation is typically opaque in that although good phonetic recognition is achieved, the processing is hidden in a distributed network of synapses that is too complex to understand. The diagram below shows how a neural network might estimate the probability (darkness) of each phone (left column) at different points in a speech signal (horizontal axis):
A recent innovation in neural networks, called deep belief nets currently holds the record for best performance on TIMIT, with about 80% phoneme transcription accuracy. More information.
Language of the Week
This week's language is Arabic; the speaker has lived in Palestine, Beirut and Damascus. [ Source material ].

- What consonants used in the Arabic passage above are not present in SSBE?
- Find examples of secondary pharyngealisation.
- What do the doubled vowels and consonants represent?
Reflections
You can improve your learning by reflecting on your understanding. Come to the tutorial prepared to discuss the items below.
- Generally, how do fricative sounds change as the place of articulation is brought forward in the mouth?
- Think of two ways in which losing your two front upper teeth will affect fricative production.
- How and why does lip-rounding affect fricative quality?
- What happens when a voiced fricative loses its voicing? What happens when it loses its turbulence?
- What causes a formant transition? Why can we hear them?
- Why does the burst centre frequency for /k/ vary with vowel context?
- Why is VOT more variable for voiceless plosives than voiced ones?
- Why might VOT vary with the place of a voiced plosive?
Word count: . Last modified: 11:40 19-Nov-2017.