5. Sonorants
Key Concepts
- The Cardinal Vowel system is one way to describe vowel articulation and is the basis of the vowel diagram on the IPA chart.
- The acoustics of sonorants are well described by the source-filter model.
- The frequency response of an unobstructed vocal tract may be well characterised by the frequencies of its resonances called formants.
- Measuring the first two or three formant frequencies over time is a simple way to quantify sonorant timbre.
- Because formant frequencies are affected by vocal tract size, they need to be normalised before they can be averaged or compared across speakers.
- Outside the laboratory other approaches to quantifying sonorant timbre are often preferred to formant frequencies.
Learning Objectives
At the end of this topic the student should be able to:
- define the class of sound Sonorant
- explain how the Cardinal Vowel system is used to characterise the space of vowel articulations
- describe the articulatory and acoustic form of diphthongs, approximants and nasals
- describe how the source-filter model explains the timbre of sonorants
- quantify the timbre of sonorants using the concept of formant frequencies and explain some limitations of their use
- explain why normalisation is necessary to compare vowel qualities across speakers
Topics
- Sonorants
Sonorants are a class of speech sound types which do not involve obstructions in the vocal tract that interrupt the air flow or generate turbulent sound. Sonorants stand in distinction to obstruents, which do have obstructions and/or generate turbulence. Within the class of Sonorant are found vowels, diphthongs, approximants and nasals. Some authorities also include flaps and taps as sonorants (we don't here).
The sub-class of approximants is sometimes divided into semi-vowels and liquids. Semi-vowels have articulations which are similar to vowels, but have a more extreme or more rapidly-changing articulation, while liquids have articulations that are unlike vowels, such as laterals ("l-like") and rhotic ("r-like") consonants.
Because sonorants have unobstructed vocal tracts, they are easier to describe and measure acoustically than obstruents. However because sonorants are not necessarily stationary (that is their articulatory and acoustic form are intrinsically dynamic), we need to think about how to describe and quantify articulations and sounds which change over time.
- Describing Vowel Articulation
We can define an articulatory vowel space in terms of the limits to the extremes of tongue position that still give rise to non-nasal resonant sounds. The idea is that if the tongue position became more extreme, then turbulence would occur. Three tongue positions can be used to demonstrate this: [i] the closest front-est tongue position, [ɯ] the closest backest tongue position, and [ɑ] the openest backest tongue position, as can be seen in the diagram below [from Catford, 1988]:
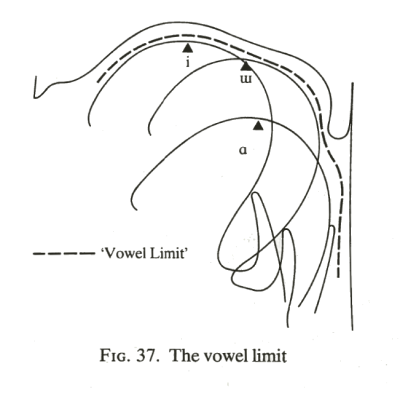
Give these upper and back extremes, we now consider how to judge variation in height and frontness. The long-standing convention is that we do so with respect to the highest point on the tongue. Different vowels cause the highest point to trace out a grid of positions as shown in the diagram below [from Catford, 1988]:
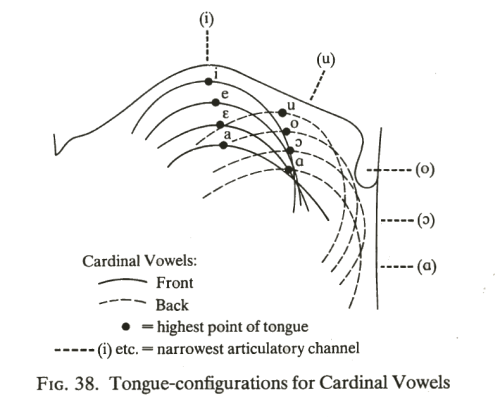
The thing to note here is that the highest point of the tongue does not coincide with the point of maximum constriction, as you might have thought. For back vowels, the narrowest constriction can occur much further back than the highest point.
We can now add a vowel articulation representing the front-est open-est tongue position [a] to create a quadrilateral that represents the highest point of the tongue for four extreme vowels, as shown in the diagram below:
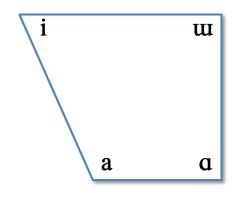
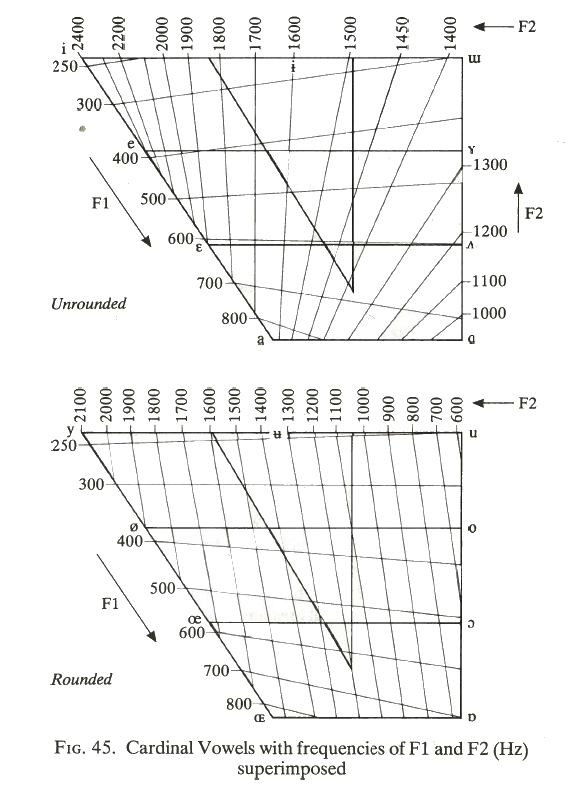
The edges of this diagram can now be enhanced by considering vowels that divide the vertical edges into three equal steps. There is some debate whether we should do this on articulatory grounds or on acoustic grounds, but let's not worry about that for now. Lastly we can add different lip positions for different parts of the quadrilateral to get the Cardinal Vowel chart:
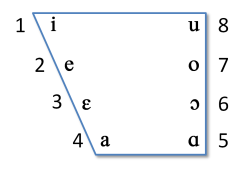
As you can see from the diagram below, cardinal vowel 1-4 have an unrounded lip position, while cardinal vowels 5-8 are rounded [source: Catford, 1988]:
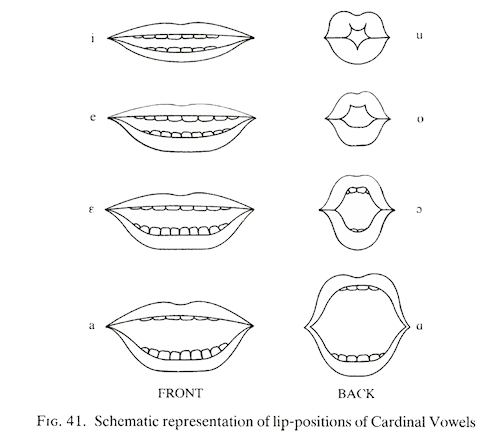
The invention of the Cardinal Vowel system is usually credited to Daniel Jones although its basis goes back to the work of earlier phoneticians. Hear Daniel Jones himself speaking the first 8 Cardinal Vowels [Source]:
Daniel Jones also defined Secondary Cardinal Vowels as the cardinal Vowels 1-8 with the opposite lip rounding. This approach is still seen in the vowel chart of the modern IPA:
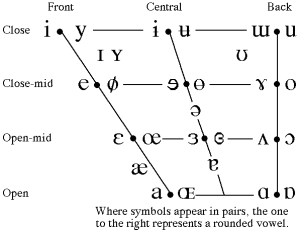
- Quantifying the timbre of sonorants
Jones's Cardinal Vowel notation provides a means to write down the perceived quality of any vowel. The accuracy of the system depends, however, on the skills and biases of the listener. The Phonetician has to judge where some given vowel sits with respect to some supposed extreme vowels spoken by the same speaker. Inevitably we will find differences across listeners simply because of the complexity of that judgement and the effect of perceptual biases caused by their language background. To make our analysis objective we have two challenges: (i) to describe the spectrum of the vowel sound itself, and (ii) to use information about the range of vowel sounds available to the speaker to establish where this sound comes with respect to others.
The Source-Filter Model
The most powerful explanatory model we have for the spectra of speech signals is called the source-filter model. In this model, sounds are generated and then independently shaped (filtered) by the vocal tract acting as a resonant tube. For example, the source of sound in a vowel is vocal fold vibration while the filtering is performed by a characteristically-shaped vocal tract tube extending from larynx to lips. The pitch or the voice quality of a vowel is changed by modifying the source; the phonetic quality of a vowel is changed by modifying the filter: i.e. changing the shape of the vocal tract tube. This diagram shows three different tubes generating three different vowels sounds from the same larynx buzz.
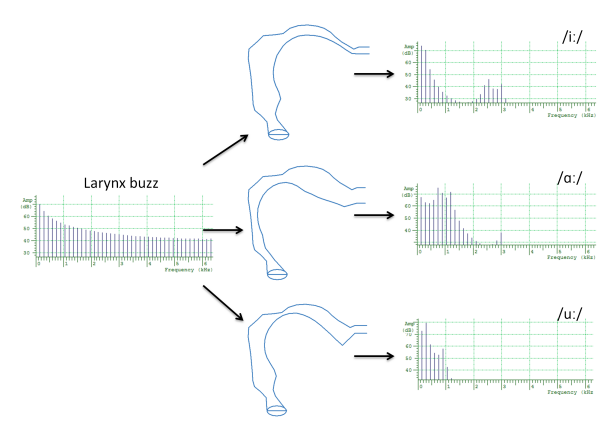
Since the acoustics of an unobstructed vocal tract (as found in oral sonorants) are relatively simple, the shaping effect of the vocal tract tube can be described in terms of a multiplicative effect on the amplitude of the frequency components of the sound passing through it. We can estimate this by dividing the output spectrum by the input spectrum to obtain something called a frequency characteristic or frequency response of the tube. A frequency response is just a graph of the change in amplitude caused by a system on a signal as a function of frequency. You should be able to see this in the diagram below.
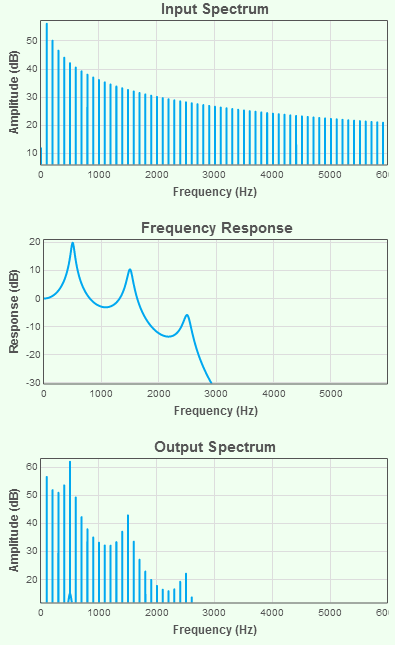
Note how the frequency response diagram explains the effect of the system on the input sound to generate the output sound. You can explore the use of spectra to describe sounds, and frequency response to describe systems using the ESystem signals and systems tutorial.
Describing the filter using formant frequencies
When the vocal tract tube is unobstructed, the frequency response of the tube has a shape which contains a small number of peaks and valleys. Peaks in the frequency response graph are caused by the fact that the tube has certain preferred frequencies of vibration. These preferences are otherwise called the resonances of the system. Phoneticians use the special term formants for the resonances of the vocal tract demonstrated by peaks in its frequency response.
Formants are important because they provide a convenient means for quantifying vowel timbre. When we listen to a vowel sound, the most salient features of its timbre are caused by the spectral peaks (because these are the "loud" parts of the spectrum), and these peaks are caused by the resonances of the tube acting on the source spectrum. Formant frequencies locate these peaks within the spectrum. Note, however, that our hearing mechanism does not extract the frequencies of formants directly, instead we hear the effect of the formants on the spectral envelope giving the sound a certain timbre.
Vowels on the F1-F2 plane
If we measure the first few formant frequencies for vowels, we find something rather remarkable:
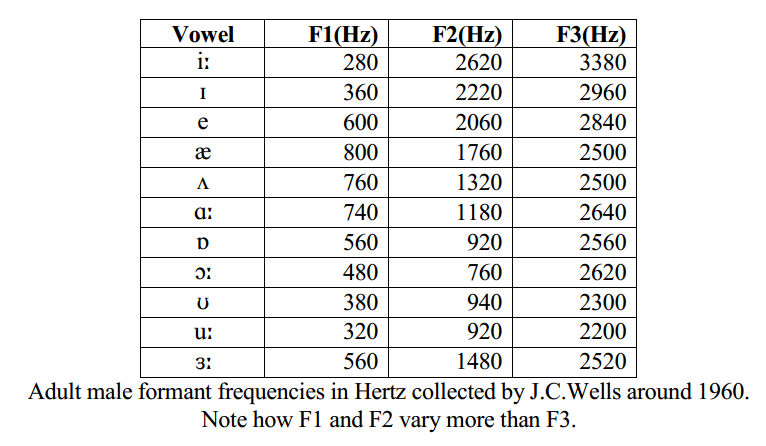
It turns out that differences in vowel quality are well described by changes in the first two formant frequencies (formant frequencies = frequencies of the peaks in the vocal tract tube frequency response for that vowel).
We can even overlay a grid of the first two formant frequencies on the vowel quadrilateral: [source: Catford, 1988]
The effect of the formant frequencies on the vowel spectrum is clearly seen as thick, dark, slow-moving, horizontal bars on the spectrogram.
Advantages and disadvantages of using formant frequencies to characterise sonorants
Historically phoneticians have been very keen on using formant frequencies for describing sonorants even though they are problematic in many respects. Disadvantages of the use of formant frequencies include:
- There is more to the timbre of vowel sounds than the formant frequencies: formant amplitudes are also important, as are other aspects of the spectrum.
- Formant frequencies are hard to measure reliably using the acoustic analysis tools we have to hand, particularly in poor audio conditions or from high-pitched speakers.
- Formant frequencies alone are not sufficient for describing nasal sonorants.
Formant frequencies do have some advantages however:
- They reduce the dimensionality of vowel timbre to pretty much two-dimensions which make it easy to plot graphs.
- Formant frequencies are independent of overall spectral amplitude or spectral slope, making them more robust to changes in voice quality or recording conditions.
- Formant frequencies may be scaled (multipled by a factor) to compensate for differences in vocal tract length across speakers.
It may be worth noting here that contemporary speech recognition systems do not use formant frequencies to describe sonorant quality.
- Measuring the Vowel Space
The formant frequencies of the same phonological vowel are not the same for all speakers. This is not just because of accent differences, but because formant frequencies scale with vocal tract length which correlates with a person's height. In a famous study, Peterson & Barney(1952), demonstrated considerable variation across speakers even for one context:
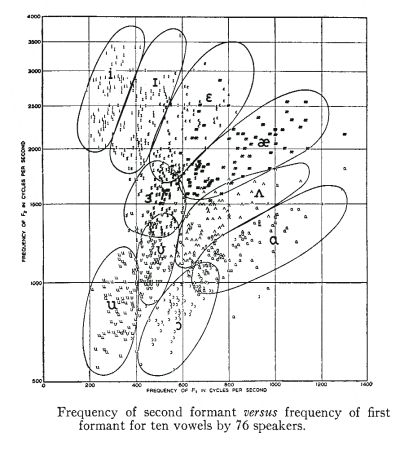
When formant frequencies are used to compare phonological vowels across speakers, you should always consider the possibility that the differences you observe could be due to physical differences between the speakers rather than one of accent. One way this can be addressed is to normalise the vowel measurements to each speaker's typical range before comparison. A number of different approaches to normalisation are possible:
- Use an estimate of the vocal tract size of the speaker. Scale the formant frequencies by a factor related to the length of a person's vocal tract. Vocal tract length might be estimated from a person's height or from a numerical analysis of the higher formant frequencies.
- Estimating the range of formant frequencies used by the speaker. Scale the formant frequencies by the typical range of formant frequencies that the speaker uses over all vowels. On approach is: F1norm is just (F1 - F1min)/(F1max-F1min. This would represent all formant frequencies in terms of values between 0 and 1.
- Estimate a "map" of the vowels used the by the speaker. All the vowels used by the speaker are compared to one another in terms of similarity (this can be done with formant frequencies or whole spectra) and then a map is produced where distances on the map relate to differences in timbre. Any given vowel can then be located on this map with respect to the known vowels.
Formant frequency normalisation will be demonstrated in the lab session, and you can read about a comparison of different techniques for vowel normalisation in the paper by Adank et al listed in the Background Reading section.
- Diphthongs (Revision)
Diphthongs are vowels which change in quality, as if they were two adjacent vowel qualities. We can contrast a diphthong with a sequence of two monophthongs, because metrically a diphthong occupies the nucleus of one syllable rather than two.
The gliding movement of a diphthong is caused by movement of the articulators during their production. We can graph this on the vowel quadrilateral. Here for the Southern British English diphthongs: [source: Wikipedia]
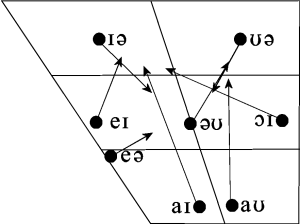
The movement of the articulators causes shifts in the formant frequencies of the vocal tract tube, which we can observe on a spectrogram:
To characterise diphthongs using formant frequencies means that we need to measure both the height and the shape of the formant movements. A simple approach might be to measure the starting and ending formant frequencies; a more realistic model might be to divide the diphthong into sections and calculate the height and slope of each formant frequency in each section.
- Approximants (Revision)
Approximants are speech sounds that involve the articulators approaching each other but not narrowly enough nor with enough articulatory precision to create turbulent airflow. Therefore, approximants fall between fricatives, which do produce a turbulent airstream, and vowels, which produce no turbulence. This class of sounds includes lateral approximants like [l] (as in "less"), non-lateral approximants like [ɹ] (as in "rest"), and semivowels like [j] and [w] (as in "yes" and "west", respectively). [source: Wikipedia]
As a class of sounds, approximants are articulations that create a narrowing in the vocal tract tube which strongly affects the formant pattern but without creating turbulent noise. Compared to a sequence of vowel articulations, approximants are more rapid and more precisely executed.

The /w/ sound is described as a labial-velar approximant, since it requires a narrowing at both the lips and the velum.
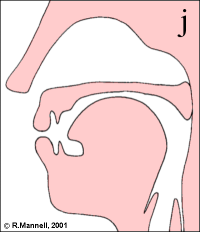
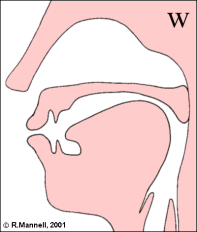
Lateral approximants have some tongue contact along the midline, but the sides of the tongue are left down to allow air flow to pass without turbulence. The "dark-l" [ɫ] is a velarised alveolar lateral approximant, and is articulated with the tongue body raised toward the velum.
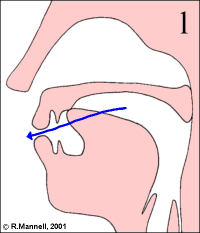
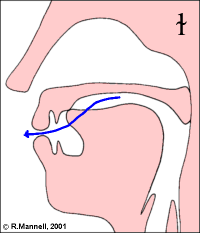
The rhotic approximants are rather an odd class, containing the labio-dental approximant, the alveolar approximant, the retroflex approximant and various uvular articulations. They might be better considered a phonological class than a phonetic one.
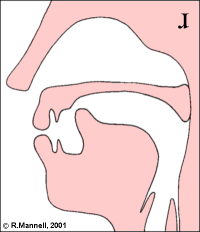
Spectrograms of approximants show rapid movements of the formant frequencies as the articulation is made and released.
The characterisation of approximants with formant frequencies faces the same difficulties as for diphthongs: the vowel quality is changing with time and we need to capture both the height and slope of the formant movements.
- Nasals (Revision)
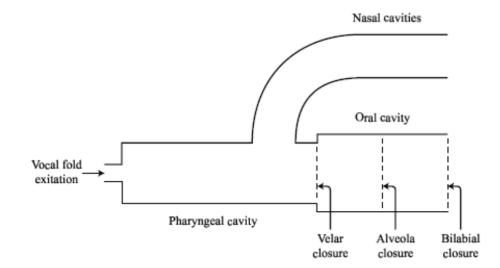
Nasal consonants are made with a combination of an oral obstruction and a lowered velum. The lowered velum allows air-flow out through the nose, and it also allows sound generated in the larynx to escape. Nasals differ according to the place of the oral obstruction. The IPA chart recognises seven different places:

The Tamil language is said to possesses distinct letters to represent [m], [n̪], [n], [ɳ], [ɲ] and [ŋ] (ம,ந,ன,ண,ஞ,ங). However not all seem to be realised contrastively.
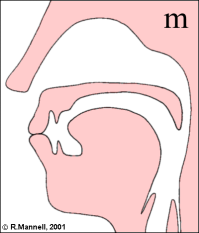
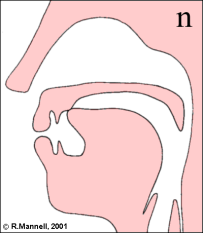
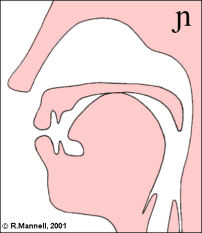
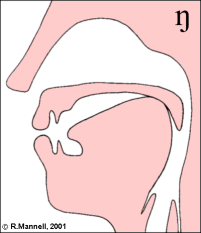
Nasal articulations create a branched tube between larynx and lips that has its own idiosyncratic frequency response. In general the nasal cavity adds a low-frequency resonance to the frequency response, and the sealed oral cavity has its own effect on the overall response depending on its size.
Spectrograms of nasals show a distinctive spectral pattern during the nasal closure and clear transition regions in the adjoining vowels.
Nasals can be quite hard to measure using formant frequencies, since the quite different vocal tract configuration has a more complex frequency response (it can have significant dips as well as significant peaks). Often the formant pattern changes abruptly when the oral closure occurs, when the resonances shift position due to the change in the configuration of the vocal tract pipe.
Nasalisation of vowels is caused by lowering of the soft palate and the linking of the nasal cavity with the vocal tract pipe. This can not only add other spectral peaks to the vowel sound, it can also reduce the amplitude of existing spectral peaks. Formant frequencies alone might not well-characterise the change in timbre caused by nasalisation.
Readings
Essential
- Ladefoged & Johnson (2010) A Course in Phonetics, Chapter 9, Vowels and Vowel-like Articulations. [available in library].
Background
- P. Adank, R.Smits, R.van Hout, " A comparison of vowel normalization procedures for language variation research", J. Acoust. Soc. Am. 116 (2004) 3099;
- J. C. Catford, A Practical Introduction to Phonetics, Chapter 7, Vowels: introduction, and Chapter 8: Cardinal Vowels. [available in library]
Laboratory Activities
In this week's laboratory activity, we will measure and synthesize vowel sounds.
- F1-F2 diagram of class vowels. Analysis of the class recordings of ten English monophthongs will be presented. You will have an opportunity to correct any analysis errors and compare your own vowels to the class average. We will look at the variation in formant frequencies across speakers and investigate the effect of normalisation.
- Analysis of a diphthong. You will measure the formant frequencies of a diphthong along with its duration and fundamental frequency.
- Articulatory synthesis. You will synthesize a version of your diphthong using a software model of a vocal tract - where the articulators need to be positioned to create the appropriate tube shape - then compare it to your original.
Research paper of the week
Evolution of Vowel Systems
- Bart de Boer, "Evolution and self-organisation in vowels systems", Evolution of Communication 3 (1999) 79-102.
In this article de Boer investigates whether the observed properties of vowel inventories in human languages might be explained from an evolutionary perspective. The goal is to explain why human languages typically have an inventory comprising a small number (3-17) of monophthongal vowels which tend to be acoustically distinct. Is this a consequence of limitations of the human language faculty, or is it just an evolutionary consequence of constraints on articulation, adaptation and memory operating in a population of speakers?
To evaluate the evolutionary hypothesis, de Boer creates a computer simulation of artificial agents that communicate by speaking vowels. Each agent starts with a random number of random quality vowels, and communicates by choosing a vowel from the inventory and by producing a noisy version of it to another agent. The receiving agent then chooses the closest vowel in its inventory, updates the quality of it to better match the speaker's vowel, and produces a noisy version of that in reply.
Over many interaction cycles, the agents settle down on a commonly-acccepted inventory of vowels. Because of noisy processes of production and perception, the vowels tend to have distinctive qualities; and because larger vowel inventories create more confusions between individuals, smaller inventories are preferred over larger ones.
De Boer concludes:
These results show that realistic vowel systems can emerge in a population of agents as the result of self-organisation. The positions of the clusters are determined by the articulatory and perceptual constraints under which the agents operate. Although the emerged systems can be described perfectly in terms of distinctive features ... these are not necessary for the emergence of the sound systems. As the match between the emerged systems and human vowel systems is so good, it is likely that the universals of human vowel systems are also the result of self-organisation, rather than the result of innate features and their markedness.
Application of the Week
Second-language pronunciation assessment
It is an unfortunate fact in language teaching classes that relatively little time is spent on pronunciation practice, pronunciation correction or pronunciation assessment. Generally this is because vocabulary and grammar can be taught to the class as a whole, while pronunciation requires one-to-one teaching.
Over the past decade, there has been increasing interest in using speech and language technology to supplement language teaching instruction. In terms of written language, technology can be used to develop vocabulary or sentence construction or test language comprehension. In terms of spoken language, technology can be used to create spoken dialogues or to assess the quality of L2 pronunciation.
This article describes a study that compared human and computers for the judgement of spoken language proficiency:
- F. de Wet, C. Van der Walt, T.R. Niesler, Automatic assessment of oral language proficiency and listening comprehension, Speech Communication, Volume 51, Issue 10, October 2009, Pages 864-874
From the introduction:
This study describes an attempt to develop an automated system to assess the listening comprehension and oral language proficiency of large numbers of students. The purpose of the system is to improve the level of objectivity, reduce the associated manual workload, and allow speedy availability of the test results. To achieve this aim, we investigate the use of automatic speech recognition (ASR) for computer-based assessments of listening and speaking skills.
The study found that a simple measurement of speaking rate and the accuracy with which an automatic speech recognition system recognised test utterances correlated well with proficiency ratings of human experts.
On the downside, the study found that ASR systems were not so good at measuring pronunciation quality. This seems to be an area where more research is needed, and also an opportunity ripe for commercial exploitation.
Language of the Week
This week's language is Swedish as spoken by educated speakers in the Stockholm area. [ Source material ].

- Identify the sounds in the Swedish passage that are not found in SSBE.
- Swedish is said to have 17 monophthongal vowels. Most languages have 5 or 6. Southern British English has 12. What might be the advantages or disadvantages of a particularly large or particularly small inventory?
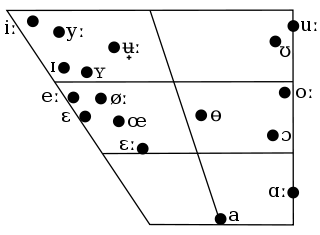
- In the videos below, locate the vowel productions on this Swedish vowel chart.
Reflections
You can improve your learning by reflecting on your understanding. Come to the tutorial prepared to discuss the items below.
- What aspects of the cardinal vowel diagram are articulatory and which acoustic?
- In the source-filter model, what is the source and what is the filter? When you produce a diphthong on a falling pitch how are the source and filter changing?
- What is a formant? Why are formant frequencies useful in the study of vowels?
- What difficulties does a child face when learning to copy adult vowel sounds? How are we able to understand child vowels?
- Find some examples where monophthongs in one accent are realised as diphthongs in another and vice versa.
- Why in Estuary English are /l/ phonemes sometimes realised as [l] and sometimes as [o]?
- Speculate why /r/ sounds are so variable within and across languages. Why do some speakers of English use a labio-dental approximant [ʋ] for /r/?
- What happens to nasal consonants when you have a 'blocked nose'? What speech problems are caused by a 'cleft palate'?
Word count: . Last modified: 13:40 31-Oct-2017.